Beyond Precision: Training-Inference Mismatch is an Optimization Problem and Simple LR Scheduling Fixes It
作者: Yaxiang Zhang, Yingru Li, Jiacai Liu, Jiawei Xu, Ziniu Li, Qian Liu, Haoyuan Li
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出动态学习率调度方法,解决LLM强化学习训练中的训练-推理不匹配问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 训练-推理不匹配 学习率调度 动态调整
📋 核心要点
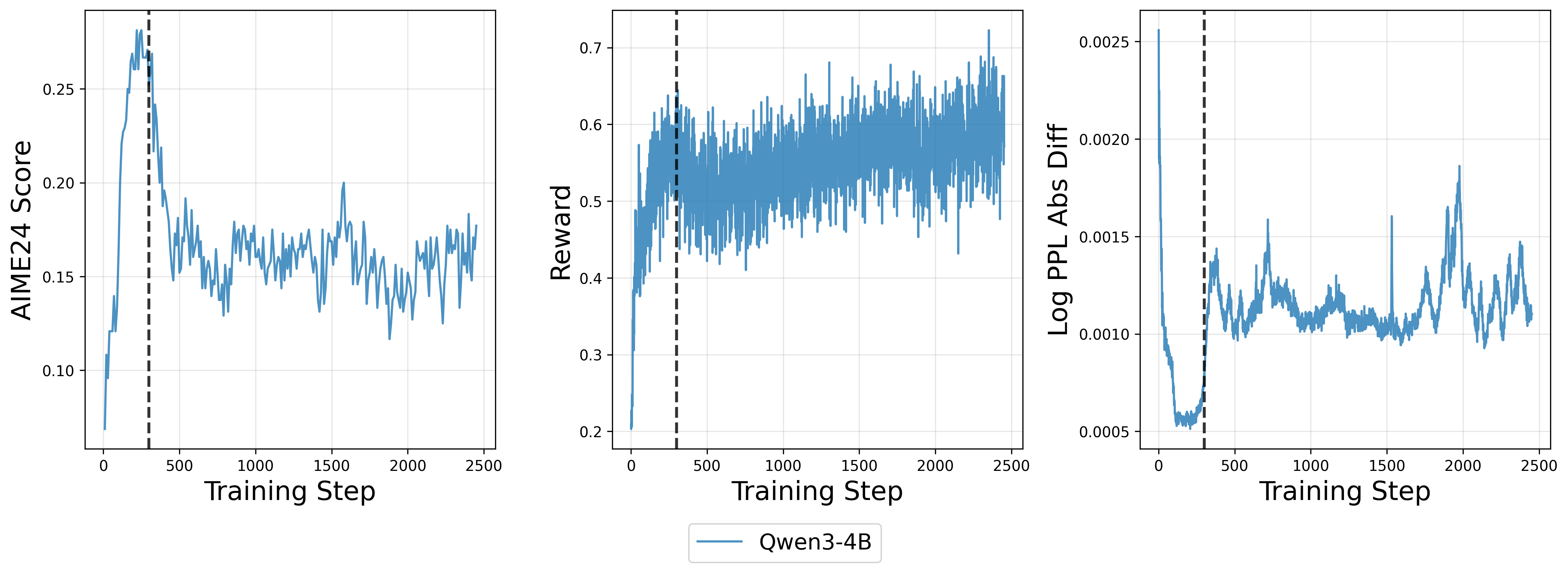
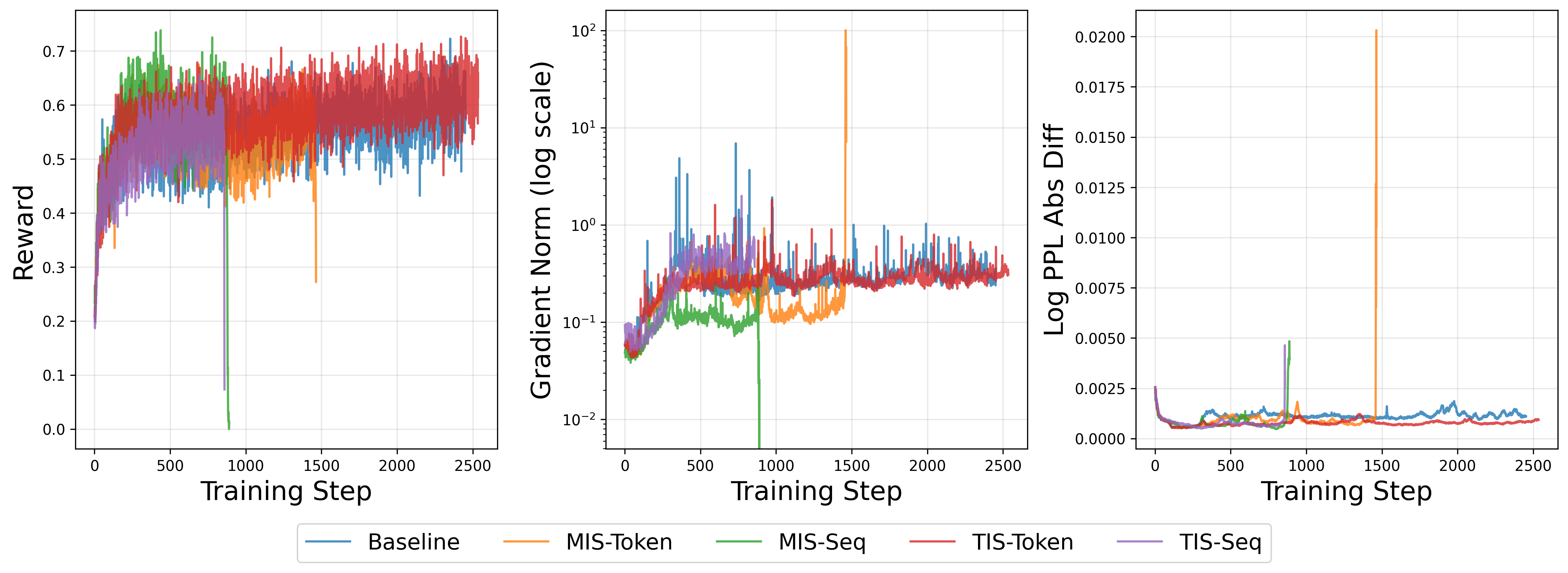
- 大型语言模型强化学习训练不稳定,现有方法如重要性采样在长时间训练中失效。
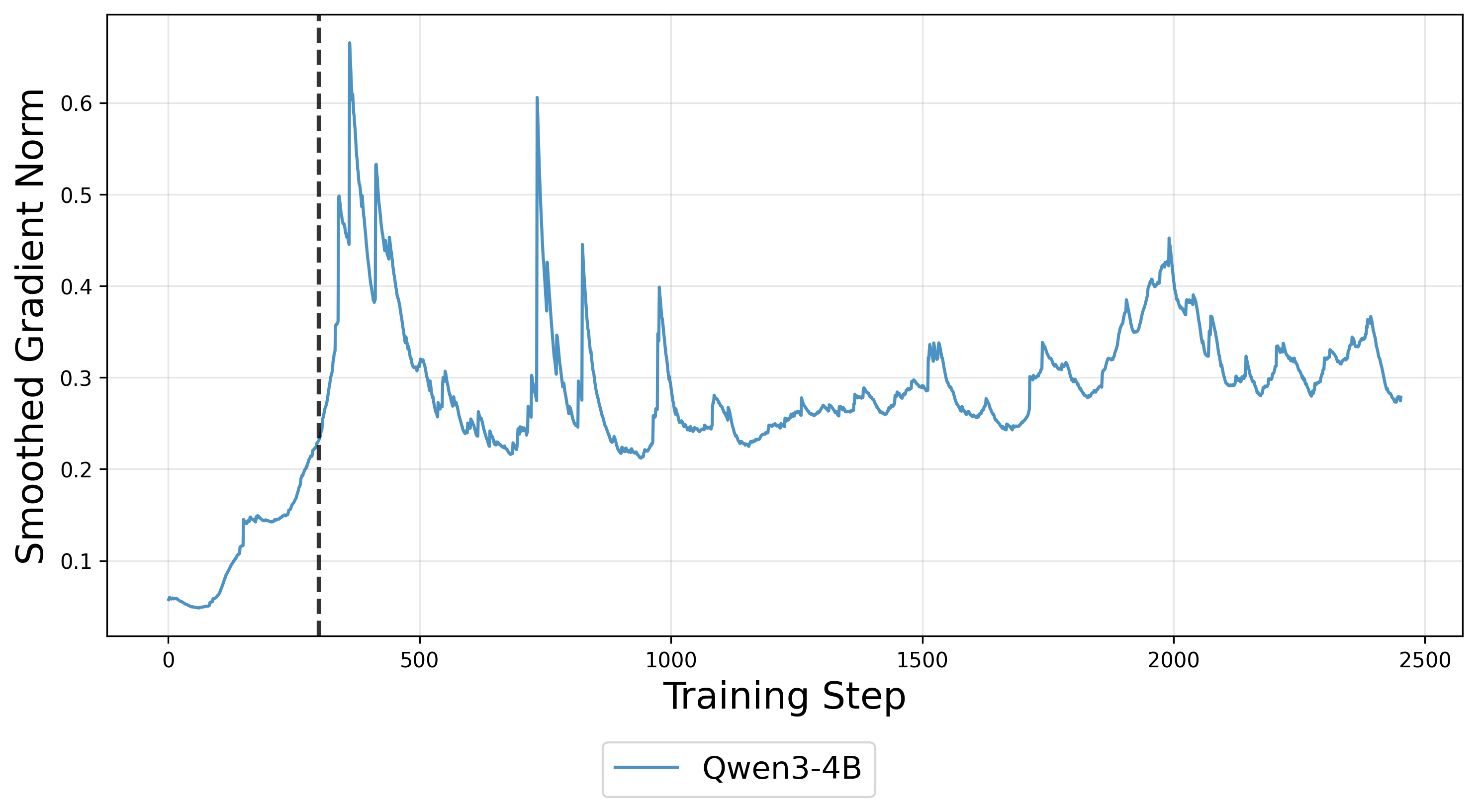
- 通过优化视角分析,发现梯度噪声和训练-推理不匹配同步增长,缩小更新步长可抑制不匹配。
- 提出动态学习率调度器,基于响应长度动态调整学习率,稳定训练并控制训练-推理不匹配。
📝 摘要(中文)
大型语言模型(LLM)的强化学习(RL)训练以其不稳定性而闻名。最近的研究将其归因于混合引擎不一致导致的“训练-推理不匹配”。然而,标准的补救措施,如重要性采样,在长时间的训练中可能会失效。本文从优化的角度分析了这种不稳定性,表明梯度噪声和训练-推理不匹配随着训练的进行而同步升级。同时,研究发现通过缩小更新步长可以有效地抑制不匹配。综上所述,不匹配不仅仅是一个静态的数值差异,而是一个与模型优化相关的动态失效。基于此,提出了一种简单而有效的解决方案:一种专门的学习率(LR)调度器。与传统LR调度器中预定义的衰减计划不同,该方法基于响应长度动态触发LR衰减,响应长度被认为是即将到来的不稳定性的可靠预警信号。经验证据表明,通过在梯度噪声升高时降低学习率,可以持续稳定RL训练,并将训练-推理不匹配保持在安全水平。
🔬 方法详解
问题定义:论文旨在解决大型语言模型强化学习训练过程中出现的训练-推理不匹配问题。现有方法,例如重要性采样,在长时间训练中无法有效解决该问题,导致训练不稳定。现有方法的痛点在于无法动态地适应训练过程中梯度噪声的变化,从而导致训练-推理不匹配的恶化。
核心思路:论文的核心思路是将训练-推理不匹配视为一个动态优化问题,并提出通过动态调整学习率来抑制这种不匹配。核心在于观察到响应长度可以作为训练不稳定性的早期预警信号,并据此动态调整学习率,从而在梯度噪声增大时降低更新步长,稳定训练过程。
技术框架:论文提出的方法主要包含以下几个阶段:1. 使用强化学习算法(如PPO)训练大型语言模型。2. 监测训练过程中模型的响应长度。3. 当响应长度超过预设阈值时,触发学习率衰减。4. 继续训练,并重复监测和调整学习率的过程。整体框架是在标准强化学习训练流程中加入了一个动态学习率调整模块,该模块根据模型的行为动态调整学习率。
关键创新:论文最重要的技术创新点在于提出了基于响应长度的动态学习率调度策略。与传统的预定义学习率衰减策略不同,该方法能够根据模型的实际训练情况动态调整学习率,从而更好地适应训练过程中的变化,有效抑制训练-推理不匹配。这种动态调整策略能够更有效地应对训练过程中出现的梯度噪声,从而稳定训练过程。
关键设计:关键设计在于响应长度阈值的设定以及学习率衰减的策略。响应长度阈值需要根据具体的模型和任务进行调整,以确保能够及时捕捉到训练不稳定性的信号。学习率衰减策略可以选择不同的衰减函数,例如指数衰减或余弦衰减,具体选择需要根据实验结果进行调整。此外,论文可能还涉及一些其他的超参数设置,例如学习率的初始值、批量大小等,这些参数也需要根据具体情况进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出的动态学习率调度方法的有效性。实验结果表明,该方法能够显著降低训练-推理不匹配,稳定强化学习训练过程,并提高模型的性能。具体的性能数据和对比基线需要在论文中查找,但总体而言,该方法能够带来显著的提升。
🎯 应用场景
该研究成果可应用于各种需要使用强化学习训练大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过稳定训练过程,可以提高模型的性能和可靠性,降低训练成本,并加速模型的开发和部署。该方法还有潜力推广到其他类型的模型和任务中,具有广泛的应用前景。
📄 摘要(原文)
Reinforcement Learning (RL) for training Large Language Models is notoriously unstable. While recent studies attribute this to "training inference mismatch stemming" from inconsistent hybrid engines, standard remedies, such as Importance Sampling, might fail during extended training runs. In this work, we analyze this instability through the lens of optimization, demonstrating that gradient noise and training-inference mismatch escalate in tandem as training progresses. Meanwhile, we find that the mismatch can be effectively suppressed by shrinking the update size. Taken together, we deduce that the mismatch is not merely a static numerical discrepancy, but a dynamic failure coupled with the model's optimization. Based on this insight, we propose a simple yet effective solution: a specialized Learning Rate (LR) scheduler. Instead of pre-defined decay schedule in traditional LR scheduler, our method dynamically triggers LR decay based on response length, which we identify as a reliable early-warning signal for impending instability. Empirical evidence suggests that by reducing the learning rate as gradient noise rises, we can consistently stabilize RL training and keep the training-inference mismatch at a safe level.