IRIS: Implicit Reward-Guided Internal Sifting for Mitigating Multimodal Hallucination
作者: Yuanshuai Li, Yuping Yan, Jirui Han, Fei Ming, Lingjuan Lv, Yaochu Jin
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
IRIS:利用隐式奖励引导内部筛选,缓解多模态大语言模型的幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 幻觉缓解 隐式奖励 直接偏好优化 策略内学习 模态对齐 内部筛选
📋 核心要点
- 现有MLLM方法依赖外部评估器,存在策略外学习差距和离散化损失,忽略了模态间的细粒度冲突。
- IRIS利用连续隐式奖励,在原生对数概率空间中捕获模态竞争,实现策略内优化,消除学习差距。
- 实验表明,IRIS仅用少量样本即可在幻觉基准测试中取得优异性能,无需外部反馈。
📝 摘要(中文)
幻觉仍然是多模态大语言模型(MLLM)面临的一个根本性挑战。直接偏好优化(DPO)是一个关键的对齐框架,但现有方法通常严重依赖昂贵的外部评估器进行评分或重写,导致策略外学习能力差距和离散化损失。由于无法访问内部状态,这些反馈忽略了生成过程中导致幻觉的不同模态之间的细粒度冲突。为了解决这个问题,我们提出了IRIS(隐式奖励引导的内部筛选),它利用原生对数概率空间中的连续隐式奖励来保留完整的信息密度并捕获内部模态竞争。这种策略内范式通过利用自我生成的偏好对来消除学习能力差距。通过基于多模态隐式奖励筛选这些对,IRIS确保优化由直接解决模态冲突的信号驱动。大量实验表明,IRIS仅使用5.7k个样本,无需任何外部反馈即可在关键幻觉基准测试中实现极具竞争力的性能。这些结果证实,IRIS为缓解MLLM幻觉提供了一种高效且有原则的范式。
🔬 方法详解
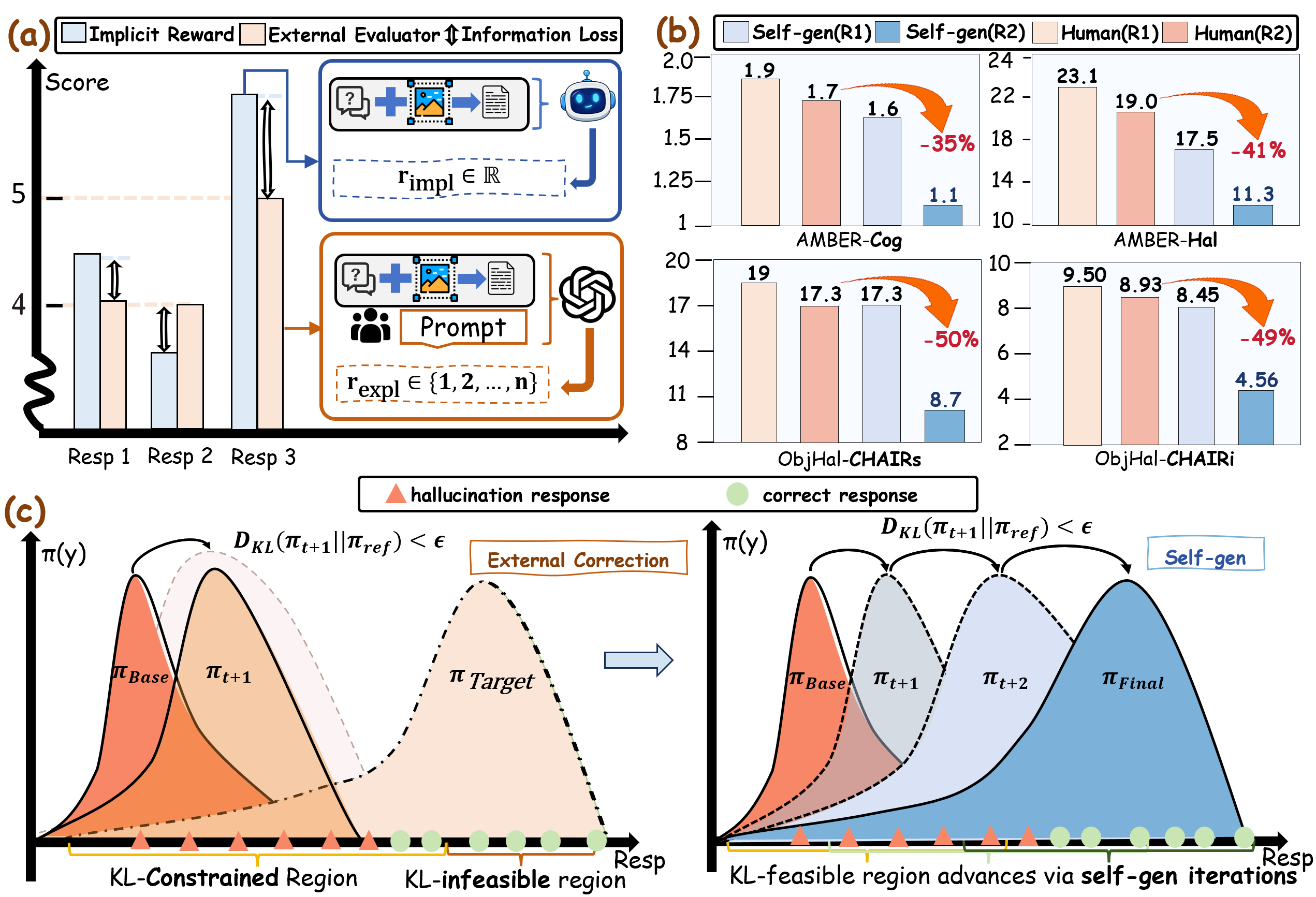
问题定义:多模态大语言模型(MLLM)在生成内容时容易出现幻觉,即生成与输入不一致或不真实的信息。现有的基于直接偏好优化(DPO)的方法通常依赖于外部评估器来对生成的内容进行评分或重写,这不仅成本高昂,而且引入了策略外学习能力差距和离散化损失。更重要的是,这些外部反馈无法访问模型的内部状态,因此忽略了不同模态之间细粒度的冲突,而这些冲突正是导致幻觉的根源。
核心思路:IRIS的核心思路是利用模型自身的内部信息,即在原生对数概率空间中的连续隐式奖励,来指导模型的学习过程。通过这种方式,IRIS能够保留完整的信息密度,并捕获不同模态之间的竞争关系。这种策略内(on-policy)的方法避免了策略外学习能力差距,并能够更有效地解决模态冲突,从而减少幻觉的产生。
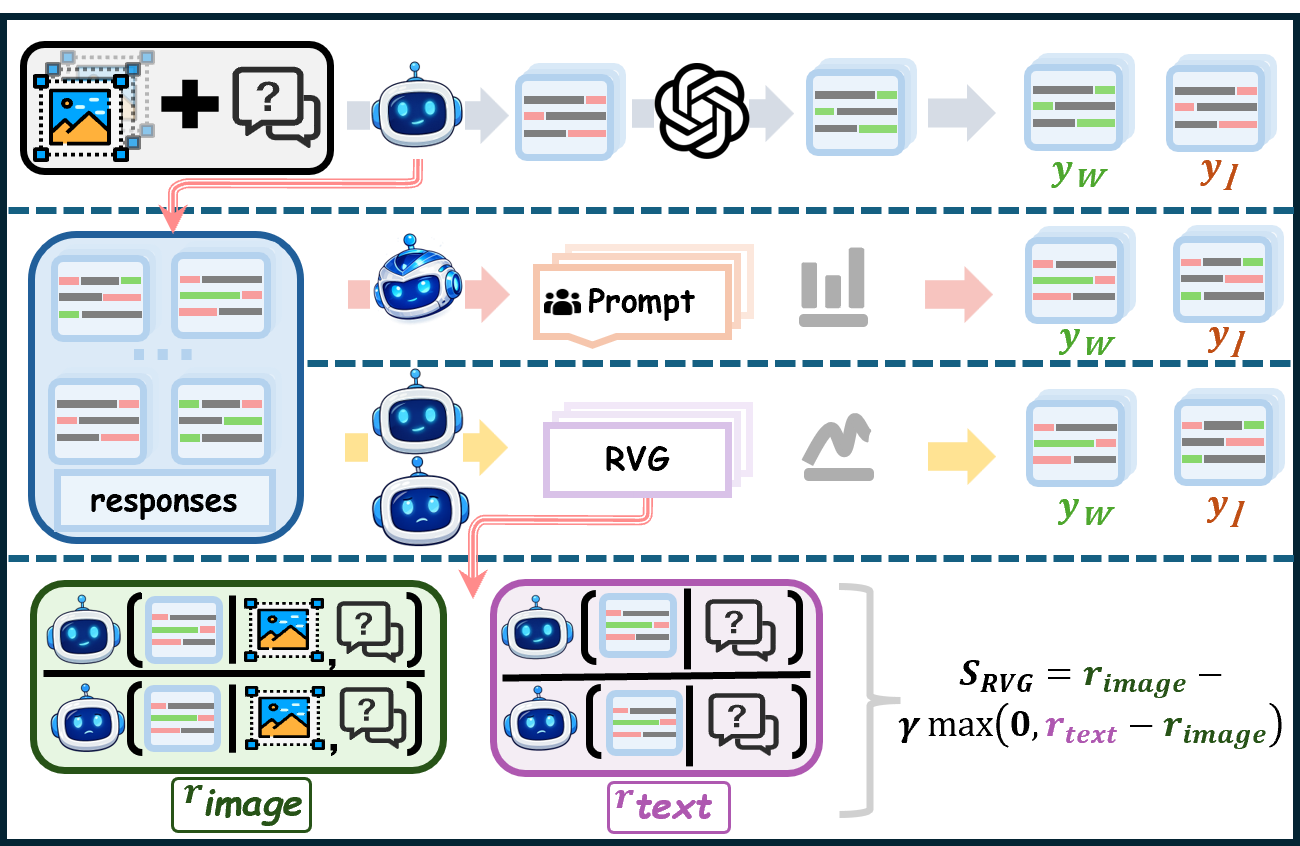
技术框架:IRIS的技术框架主要包括以下几个阶段:1) 使用MLLM生成多个候选回复;2) 利用模型的内部状态计算每个候选回复的隐式奖励,该奖励反映了不同模态之间的协调程度;3) 基于隐式奖励,构建偏好对,即选择奖励较高的回复作为更优的回复;4) 使用DPO算法,利用这些偏好对来微调MLLM,使其更倾向于生成模态协调的回复。
关键创新:IRIS最重要的技术创新在于它使用隐式奖励来指导模型的学习过程。与传统的依赖外部评估器的方法不同,IRIS的隐式奖励直接从模型的内部状态中提取,能够更准确地反映模态之间的冲突。此外,IRIS的策略内学习范式避免了策略外学习能力差距,使其能够更有效地利用数据。
关键设计:IRIS的关键设计包括:1) 隐式奖励的计算方式,论文中具体如何定义和计算隐式奖励需要参考原文;2) 偏好对的构建策略,如何选择正负样本对模型的训练效果有重要影响;3) DPO算法的参数设置,例如学习率、batch size等。
🖼️ 关键图片
📊 实验亮点
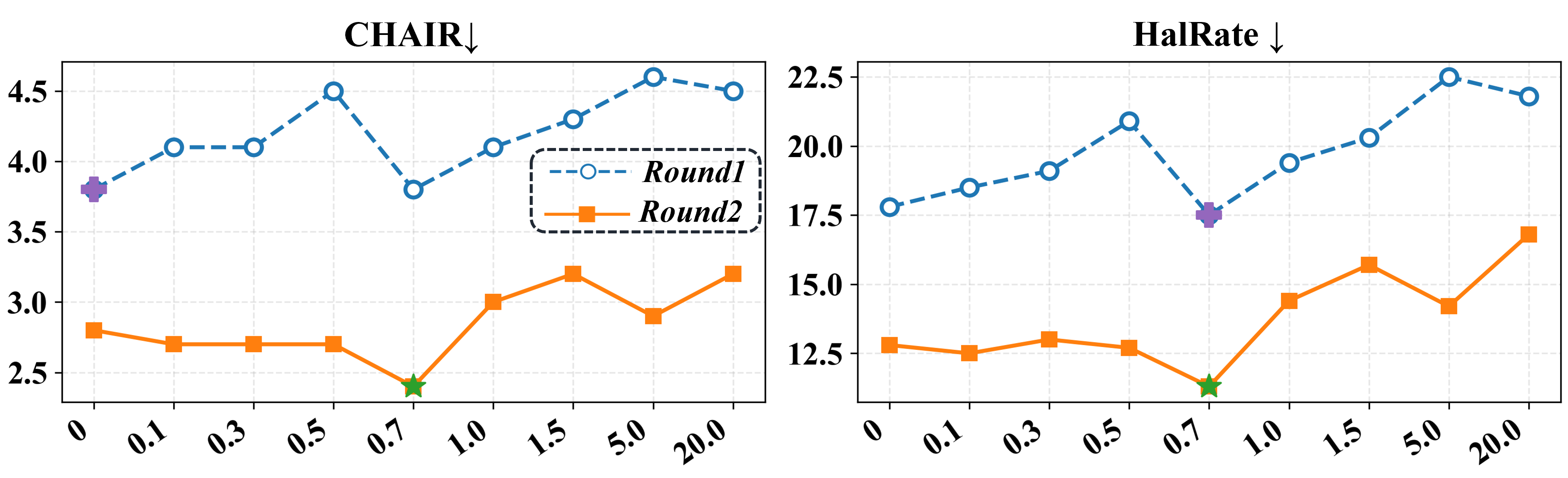
IRIS仅使用5.7k个样本,无需任何外部反馈,即可在关键幻觉基准测试中实现极具竞争力的性能。这表明IRIS在缓解MLLM幻觉方面具有高效性和有效性。具体的性能数据和对比基线需要在论文中查找,但总体而言,IRIS在数据效率和性能方面都优于现有方法。
🎯 应用场景
IRIS可应用于各种多模态大语言模型,提升其在图像描述、视觉问答、多模态对话等任务中的表现,减少幻觉现象,提高生成内容的可靠性和真实性。该研究对于构建更值得信赖和实用的多模态人工智能系统具有重要意义,并有望推动相关技术在智能客服、教育、医疗等领域的应用。
📄 摘要(原文)
Hallucination remains a fundamental challenge for Multimodal Large Language Models (MLLMs). While Direct Preference Optimization (DPO) is a key alignment framework, existing approaches often rely heavily on costly external evaluators for scoring or rewriting, incurring off-policy learnability gaps and discretization loss. Due to the lack of access to internal states, such feedback overlooks the fine-grained conflicts between different modalities that lead to hallucinations during generation. To address this issue, we propose IRIS (Implicit Reward-Guided Internal Sifting), which leverages continuous implicit rewards in the native log-probability space to preserve full information density and capture internal modal competition. This on-policy paradigm eliminates learnability gaps by utilizing self-generated preference pairs. By sifting these pairs based on multimodal implicit rewards, IRIS ensures that optimization is driven by signals that directly resolve modal conflicts. Extensive experiments demonstrate that IRIS achieves highly competitive performance on key hallucination benchmarks using only 5.7k samples, without requiring any external feedback during preference alignment. These results confirm that IRIS provides an efficient and principled paradigm for mitigating MLLM hallucinations.