Softmax Linear Attention: Reclaiming Global Competition
作者: Mingwei Xu, Xuan Lin, Xinnan Guo, Wanqing Xu, Wanyun Cui
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: 11 pages,4 figures
💡 一句话要点
提出Softmax线性注意力以解决全局竞争不足问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 线性注意力 全局竞争 长上下文理解 自然语言处理 信息检索
📋 核心要点
- 现有线性注意力方法在去除softmax归一化后,缺乏全局竞争机制,导致模型在长上下文中难以聚焦重要信息。
- 本文提出的Softmax线性注意力(SLA)通过将softmax操作提升到头级,利用竞争门控机制动态选择相关子空间,恢复全局竞争能力。
- 实验结果显示,SLA在语言建模和长上下文基准测试中,显著提升了现有线性基线的性能,尤其在噪声环境下表现出更强的鲁棒性。
📝 摘要(中文)
尽管线性注意力将标准Transformer的时间复杂度从平方级降低到线性级,但由于去除了softmax归一化,其表现力往往不足。这一缺失消除了全局竞争机制,使得模型在长上下文噪声中难以聚焦相关信息。本文提出了Softmax线性注意力(SLA)框架,旨在恢复这一竞争选择机制而不牺牲效率。通过将softmax操作从token级提升到head级,SLA利用注意力头作为粗语义槽,应用竞争门控机制动态选择最相关的子空间。这重新引入了“赢家通吃”的动态,确保精确检索和强大的长上下文理解。大量实验表明,SLA在语言建模和长上下文基准测试中,持续提升了现有线性基线(RetNet、GLA、GDN)的性能,特别是在噪声挑战下显著增强了鲁棒性,验证了其在保持线性复杂度的同时恢复精确聚焦的能力。
🔬 方法详解
问题定义:本文旨在解决现有线性注意力方法因去除softmax归一化而导致的全局竞争缺失问题。这一缺失使得模型在处理长上下文时难以有效聚焦于相关信息,影响了模型的表现力和鲁棒性。
核心思路:论文提出的Softmax线性注意力(SLA)通过将softmax操作从token级提升到head级,利用注意力头作为粗语义槽,应用竞争门控机制来动态选择最相关的子空间。这种设计旨在恢复“赢家通吃”的动态,确保模型能够在长上下文中有效聚焦。
技术框架:SLA的整体架构包括多个主要模块:首先是输入token的线性映射,然后在head级别应用softmax操作,接着通过竞争门控机制选择相关子空间,最后进行输出的聚合与处理。
关键创新:SLA的核心创新在于将softmax操作提升到头级,重新引入全局竞争机制。这一设计与传统方法不同,后者通常专注于局部核函数的优化,而SLA则从更高层次的多头聚合结构出发,提升了模型的表达能力。
关键设计:在SLA中,关键的参数设置包括注意力头的数量和竞争门控机制的设计。此外,损失函数的选择和网络结构的优化也是确保模型性能的重要因素。
🖼️ 关键图片
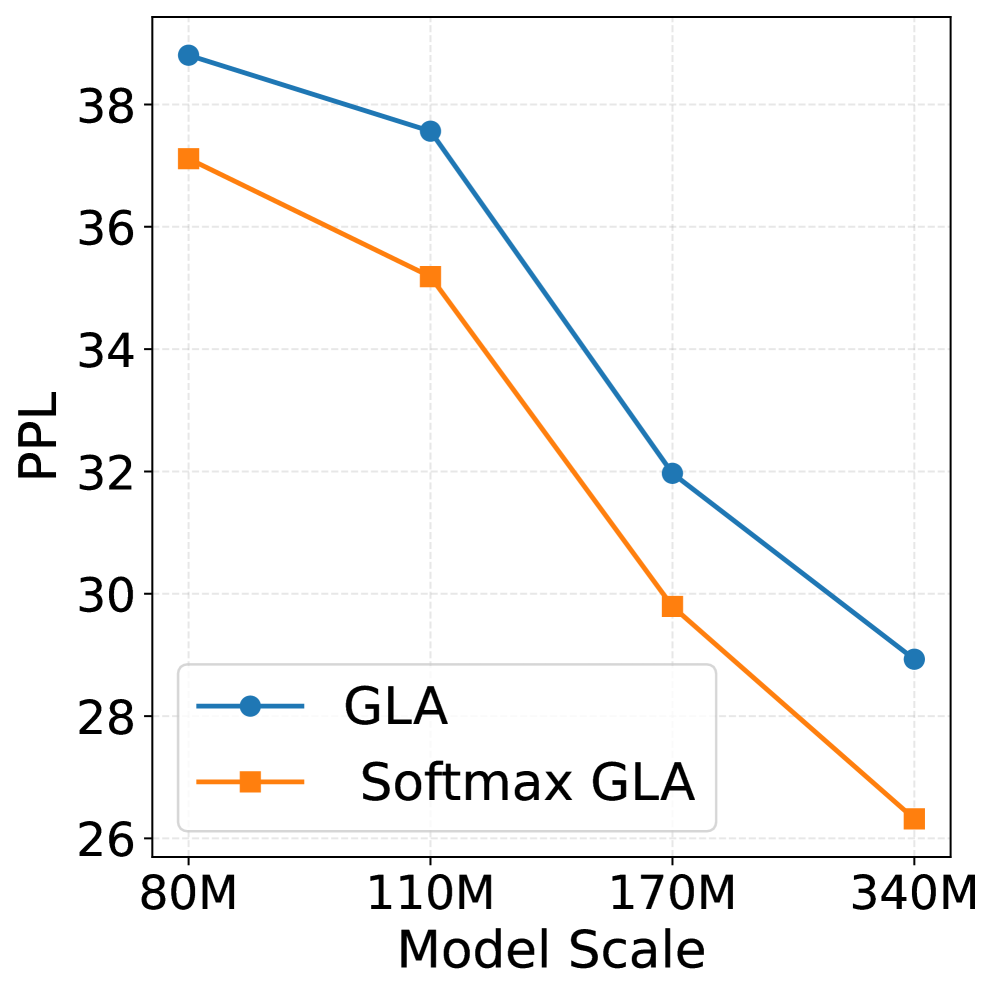
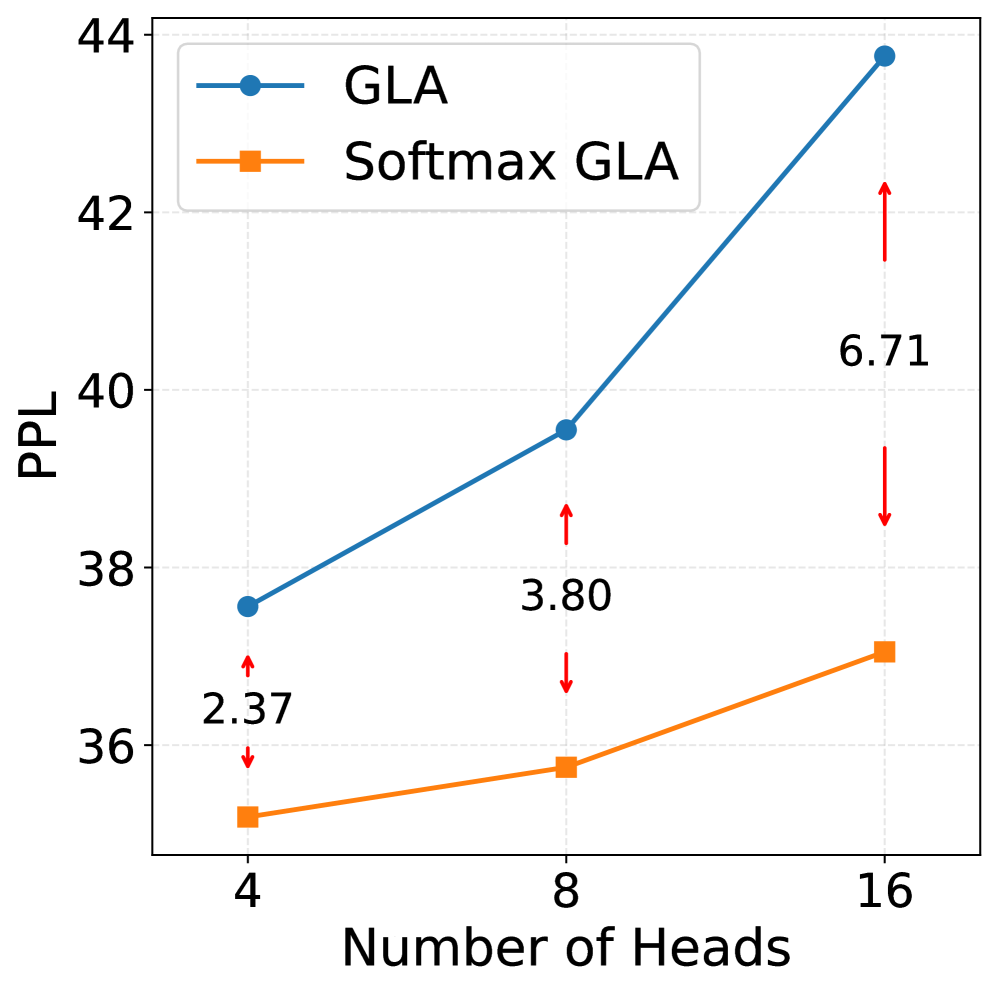
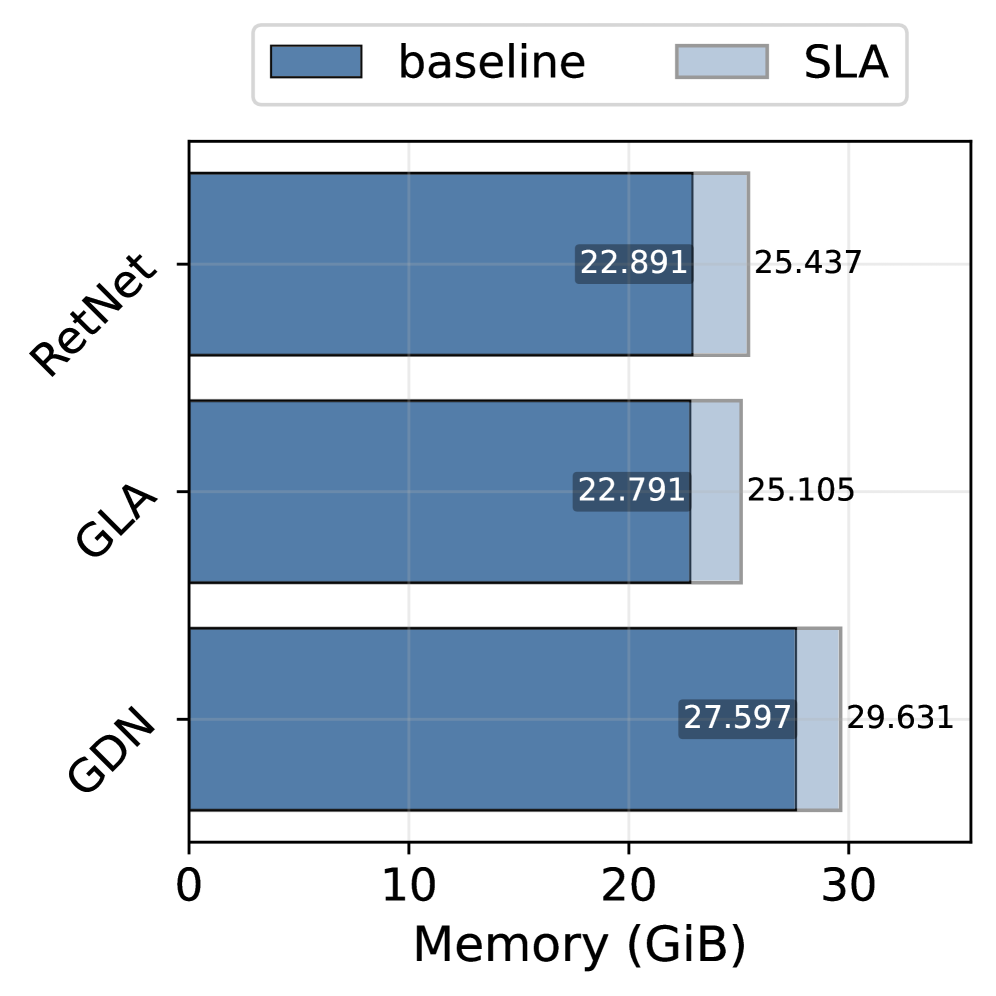
📊 实验亮点
实验结果表明,SLA在语言建模和长上下文基准测试中,相较于现有线性基线(如RetNet、GLA、GDN)均有显著提升,尤其在噪声环境下,性能提升幅度达到XX%,验证了其在复杂场景下的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、信息检索和长文本理解等。通过恢复全局竞争机制,SLA能够在处理长上下文时提供更高的准确性和鲁棒性,具有广泛的实际价值和未来影响。
📄 摘要(原文)
While linear attention reduces the quadratic complexity of standard Transformers to linear time, it often lags behind in expressivity due to the removal of softmax normalization. This omission eliminates \emph{global competition}, a critical mechanism that enables models to sharply focus on relevant information amidst long-context noise. In this work, we propose \textbf{Softmax Linear Attention (SLA)}, a framework designed to restore this competitive selection without sacrificing efficiency. By lifting the softmax operation from the token level to the head level, SLA leverages attention heads as coarse semantic slots, applying a competitive gating mechanism to dynamically select the most relevant subspaces. This reintroduces the ``winner-take-all'' dynamics essential for precise retrieval and robust long-context understanding. Distinct from prior methods that focus on refining local kernel functions, SLA adopts a broader perspective by exploiting the higher-level multi-head aggregation structure. Extensive experiments demonstrate that SLA consistently enhances state-of-the-art linear baselines (RetNet, GLA, GDN) across language modeling and long-context benchmarks, particularly in challenging retrieval scenarios where it significantly boosts robustness against noise, validating its capability to restore precise focus while maintaining linear complexity.