Beyond Mode Elicitation: Diversity-Preserving Reinforcement Learning via Latent Diffusion Reasoner
作者: Haoqiang Kang, Yizhe Zhang, Nikki Lijing Kuang, Yi-An Ma, Lianhui Qin
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出LaDi-RL,通过潜在扩散推理增强强化学习,解决LLM推理中多样性崩溃问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 扩散模型 潜在空间 LLM推理 多样性探索
📋 核心要点
- 离散强化学习在token空间探索时,策略熵降低导致多样性崩溃,限制了LLM推理能力。
- LaDi-RL在连续潜在空间进行探索,利用扩散模型保留多个解模式,提升探索效率。
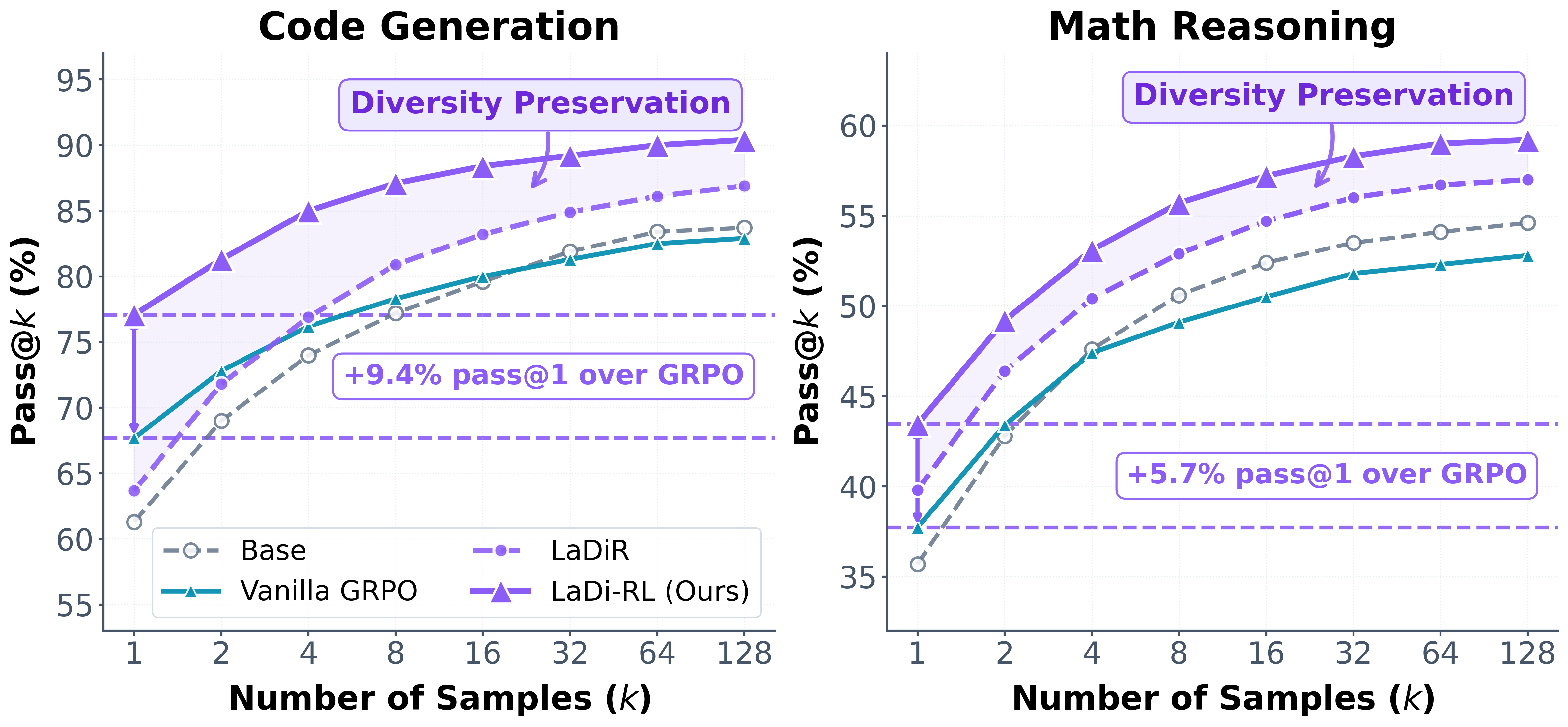
- 实验表明,LaDi-RL在代码生成和数学推理任务上,显著优于离散RL基线。
📝 摘要(中文)
本文提出了一种名为LaDi-RL(Latent Diffusion Reasoning with Reinforcement Learning)的框架,旨在解决强化学习优化LLM推理时,因离散token空间探索而导致的多样性崩溃问题。LaDi-RL直接在连续潜在空间中进行探索,其中潜在变量编码语义级别的推理轨迹。通过引导扩散建模探索过程,多步去噪能够分散随机性,并保留多个共存的解模式,避免相互抑制。此外,该方法将潜在空间探索与文本空间生成解耦,使得基于潜在扩散的优化比单独的文本空间策略优化更有效。结合文本策略后,性能可以进一步提升。在代码生成和数学推理基准测试上的实验表明,LaDi-RL在pass@1和pass@k指标上均优于离散RL基线,代码生成上pass@1提升9.4%,数学推理上提升5.7%,证明了基于扩散的潜在RL是离散token级别RL的一种有效替代方案。
🔬 方法详解
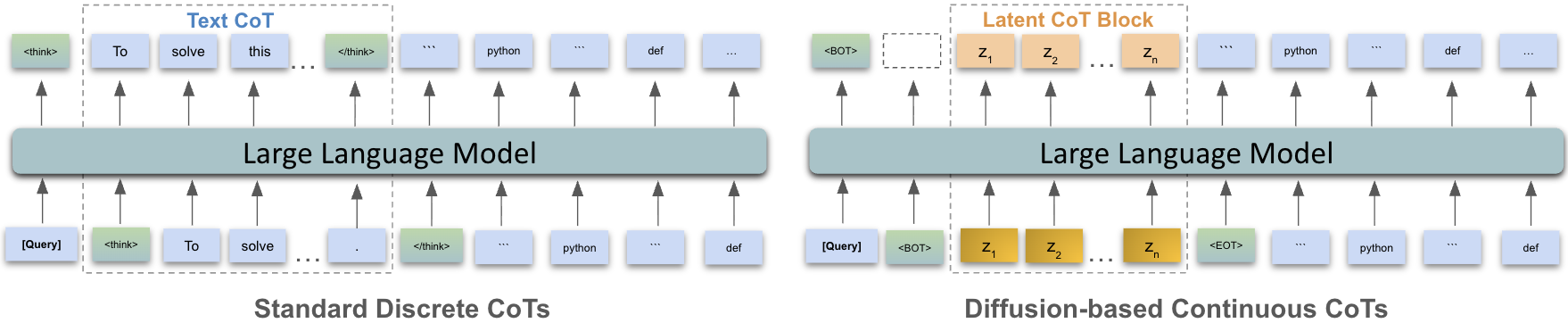
问题定义:现有基于强化学习的LLM推理方法,通常在离散的token空间进行探索和优化。这种方法容易陷入局部最优,导致策略的多样性降低,出现“mode elicitation”现象,即模型倾向于生成相似的、单一的推理路径,无法充分探索所有可能的解空间。这限制了模型解决复杂问题的能力。
核心思路:LaDi-RL的核心思路是将探索过程从离散的token空间转移到连续的潜在空间。通过学习一个将文本推理轨迹编码到潜在空间的映射,然后在该潜在空间中利用扩散模型进行探索。扩散模型能够生成多样化的样本,从而避免了在离散空间中容易出现的多样性崩溃问题。这种设计允许模型探索更广泛的推理路径,并找到更优的解决方案。
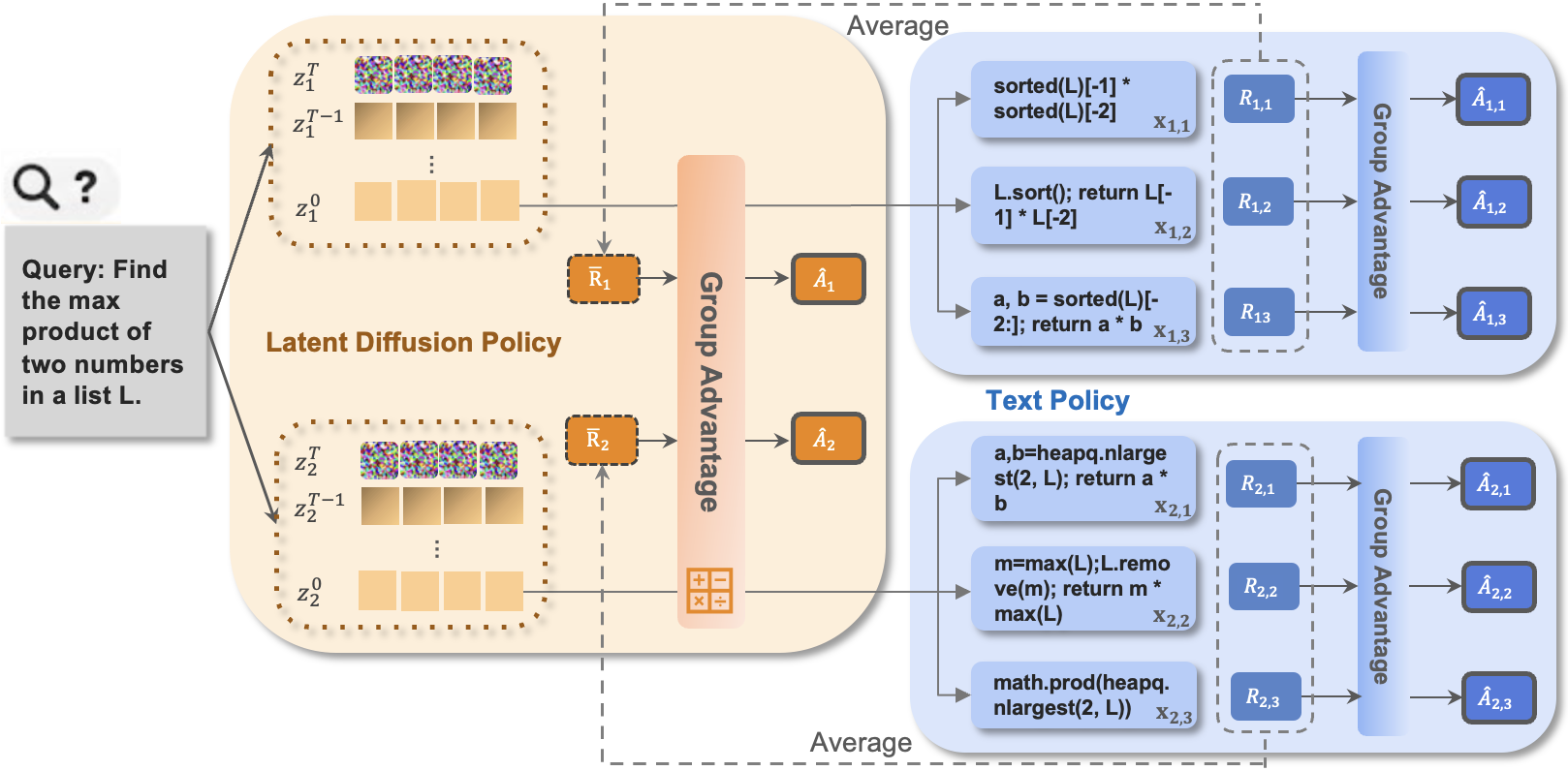
技术框架:LaDi-RL框架包含以下几个主要模块:1) 编码器:将文本推理轨迹编码到连续的潜在空间。2) 潜在扩散模型:在潜在空间中进行探索,生成新的潜在推理轨迹。3) 解码器:将潜在推理轨迹解码回文本空间,生成实际的推理过程。4) 强化学习模块:使用强化学习算法(如PPO)优化潜在扩散模型的策略,使其能够生成更有利于解决问题的推理轨迹。框架首先使用编码器将已有的推理数据映射到潜在空间,然后训练一个扩散模型来生成新的潜在轨迹。接着,使用解码器将这些潜在轨迹转换回文本,并使用强化学习来优化扩散模型的生成过程,使其能够产生更高奖励的推理轨迹。
关键创新:LaDi-RL的关键创新在于将扩散模型引入到强化学习的推理优化过程中,并且在连续的潜在空间中进行探索。这与传统的在离散token空间进行探索的方法有本质区别。通过扩散模型,LaDi-RL能够生成更多样化的推理轨迹,从而避免了多样性崩溃问题。此外,将潜在空间探索与文本空间生成解耦,使得优化过程更加高效。
关键设计:LaDi-RL的关键设计包括:1) 潜在空间的维度:需要根据具体任务选择合适的潜在空间维度,以平衡表达能力和计算复杂度。2) 扩散模型的架构:可以使用不同的扩散模型架构,如DDPM、DDIM等,来控制生成过程的质量和效率。3) 强化学习的奖励函数:需要设计合适的奖励函数,以引导模型生成更有利于解决问题的推理轨迹。4) 文本策略:使用额外的文本策略来进一步优化生成的文本,可以提高最终的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LaDi-RL在代码生成和数学推理任务上均取得了显著的性能提升。在代码生成任务上,LaDi-RL的pass@1指标提升了9.4%,在数学推理任务上,pass@1指标提升了5.7%。这些结果表明,基于扩散的潜在RL是一种有效的LLM推理优化方法,能够显著提高模型解决复杂问题的能力。
🎯 应用场景
LaDi-RL具有广泛的应用前景,可应用于代码生成、数学推理、自然语言理解等多个领域。该方法能够提升LLM在复杂推理任务中的性能,并有望应用于智能客服、自动编程、科学研究等场景,提高问题解决效率和智能化水平。未来,该研究或可扩展到其他需要多样性探索的任务中。
📄 摘要(原文)
Recent reinforcement learning (RL) methods improve LLM reasoning by optimizing discrete Chain-of-Thought (CoT) generation; however, exploration in token space often suffers from diversity collapse as policy entropy decreases due to mode elicitation behavior in discrete RL. To mitigate this issue, we propose Latent Diffusion Reasoning with Reinforcement Learning (LaDi-RL), a framework that conducts exploration directly in a continuous latent space, where latent variables encode semantic-level reasoning trajectories. By modeling exploration via guided diffusion, multi-step denoising distributes stochasticity and preserves multiple coexisting solution modes without mutual suppression. Furthermore, by decoupling latent-space exploration from text-space generation, we show that latent diffusion-based optimization is more effective than text-space policy optimization alone, while a complementary text policy provides additional gains when combined with latent exploration. Experiments on code generation and mathematical reasoning benchmarks demonstrate consistent improvements in both pass@1 and pass@k over discrete RL baselines, with absolute pass@1 gains of +9.4% on code generation and +5.7% on mathematical reasoning, highlighting diffusion-based latent RL as a principled alternative to discrete token-level RL for reasoning.