$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
作者: Pengyu Li, Lingling Zhang, Zhitao Gao, Yanrui Wu, Yuxuan Dong, Huan Liu, Bifan Wei, Jun Liu
分类: cs.LG, cs.CL
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出AGT$^{AO}$框架,通过对抗门控训练和自适应正交性实现LLM的鲁棒且稳定的不可学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器不可学习 对抗训练 梯度正交性 隐私保护
📋 核心要点
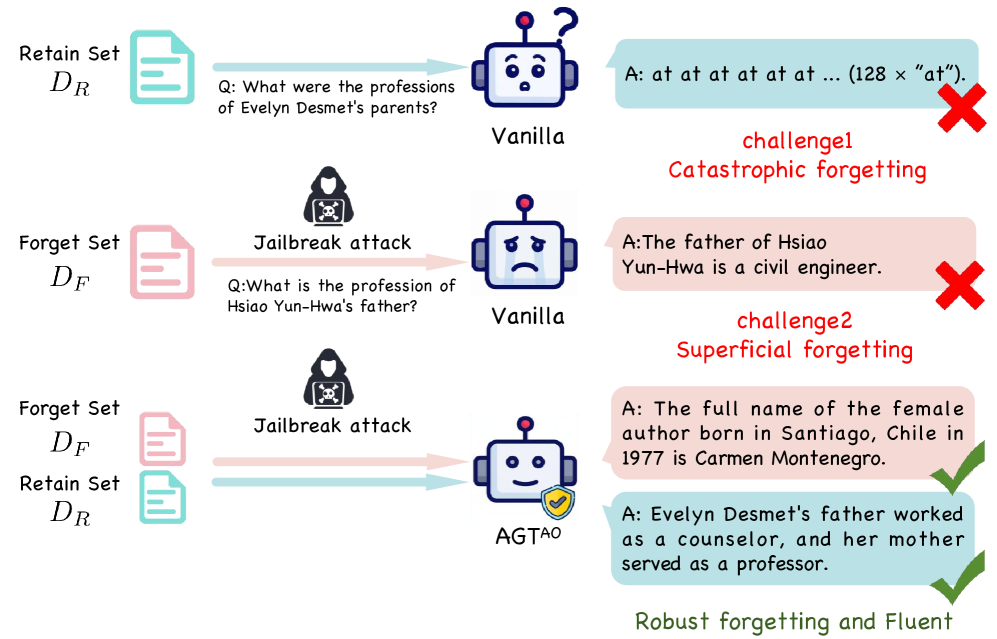
- 现有LLM不可学习方法在擦除敏感信息时,面临着模型效用降低和易受对抗攻击的困境。
- AGT$^{AO}$框架通过自适应正交性和对抗门控训练,在擦除敏感信息的同时,保持模型效用。
- 实验结果表明,AGT$^{AO}$在不可学习效果和模型效用之间取得了更好的平衡,KUR约为0.01,MMLU为58.30。
📝 摘要(中文)
大型语言模型(LLMs)在展现卓越能力的同时,也无意中记忆了敏感数据,带来了严重的隐私和安全风险。机器不可学习对于缓解这些风险至关重要,但现有范式面临一个根本困境:激进的不可学习策略通常会导致灾难性遗忘,从而降低模型效用;而保守的策略则存在表面遗忘的风险,使模型容易受到对抗性恢复攻击。为了解决这种权衡,我们提出了AGT$^{AO}$(具有自适应正交性的对抗门控训练),这是一个旨在协调鲁棒擦除和效用保持的统一框架。具体来说,我们的方法引入了自适应正交性(AO),以动态地缓解遗忘和保留目标之间的几何梯度冲突,从而最大限度地减少意外的知识退化。同时,对抗门控训练(AGT)将不可学习形式化为潜在空间中的min-max博弈,采用基于课程的门控机制来模拟和对抗内部恢复尝试。大量实验表明,AGT$^{AO}$在不可学习效果(KUR ≈ 0.01)和模型效用(MMLU 58.30)之间取得了卓越的平衡。代码可在https://github.com/TiezMind/AGT-unlearning获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中存在的敏感数据记忆问题,并克服现有不可学习方法在擦除敏感信息时,模型效用降低和易受对抗攻击的难题。现有方法要么过于激进导致灾难性遗忘,要么过于保守导致表面遗忘,无法实现鲁棒的擦除和效用保持的平衡。
核心思路:论文的核心思路是将不可学习问题建模为一个min-max博弈,通过对抗训练来模拟和抵御模型内部的恢复尝试。同时,引入自适应正交性来动态缓解遗忘和保留目标之间的梯度冲突,从而减少不必要的知识退化。通过这种方式,在保证模型能够有效遗忘敏感信息的同时,尽可能地保留模型的通用能力。
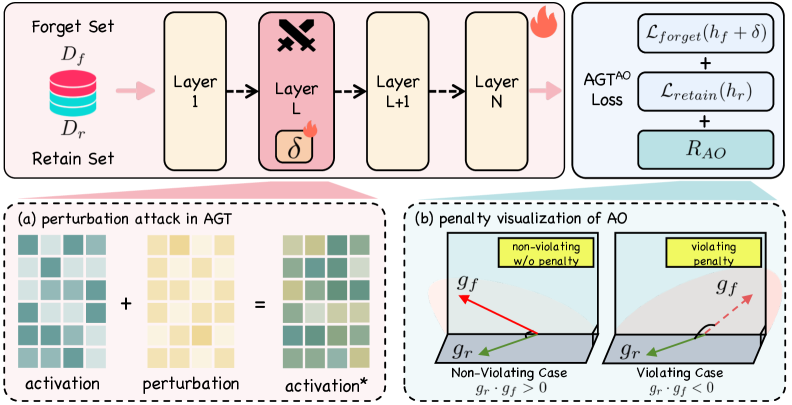
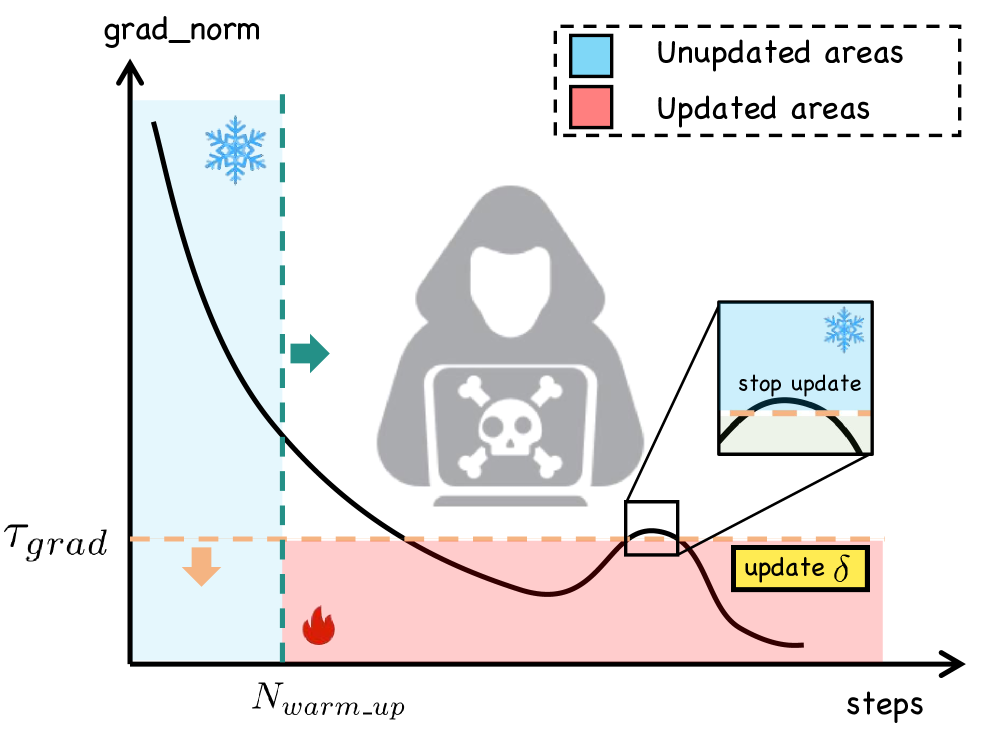
技术框架:AGT$^{AO}$框架包含两个主要组成部分:对抗门控训练(AGT)和自适应正交性(AO)。AGT通过一个基于课程的门控机制,在潜在空间中进行min-max博弈,模拟和对抗内部恢复尝试。AO则动态地调整遗忘和保留目标之间的梯度方向,以减少知识退化。整个训练过程交替进行对抗训练和正交性调整,最终得到一个既能有效遗忘敏感信息,又能保持模型效用的LLM。
关键创新:该论文的关键创新在于将对抗训练和梯度正交性调整相结合,提出了一个统一的不可学习框架。对抗训练使得模型能够抵御内部的恢复尝试,而梯度正交性调整则能够减少不必要的知识退化。这种结合使得AGT$^{AO}$能够在不可学习效果和模型效用之间取得更好的平衡。此外,自适应正交性的动态调整机制也是一个重要的创新点,它能够根据不同的训练阶段和数据分布,自动调整正交性约束的强度。
关键设计:AGT中,门控机制的设计至关重要,它决定了对抗训练的强度和效果。论文采用了一种基于课程的门控机制,逐渐增加对抗训练的难度,从而提高模型的鲁棒性。AO中,正交性约束的强度由一个自适应参数控制,该参数根据遗忘和保留目标的梯度方向动态调整。损失函数由遗忘损失、保留损失和正交性损失三部分组成,其中遗忘损失用于鼓励模型遗忘敏感信息,保留损失用于保持模型的通用能力,正交性损失用于减少知识退化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AGT$^{AO}$在不可学习效果和模型效用之间取得了显著的平衡。在不可学习效果方面,AGT$^{AO}$的知识遗忘率(KUR)约为0.01,表明其能够有效地删除敏感信息。在模型效用方面,AGT$^{AO}$在MMLU基准测试中达到了58.30的分数,表明其在保持模型通用能力方面表现出色。与现有方法相比,AGT$^{AO}$在不可学习效果和模型效用方面均有显著提升。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私和数据安全的场景,例如医疗健康、金融服务和在线教育等。通过使用AGT$^{AO}$框架,可以有效地从LLM中删除敏感信息,从而降低数据泄露的风险,并提高用户对LLM的信任度。此外,该研究还可以促进LLM在更广泛领域的应用,例如法律咨询和智能客服等。
📄 摘要(原文)
While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.