Efficient Adversarial Attacks on High-dimensional Offline Bandits
作者: Seyed Mohammad Hadi Hosseini, Amir Najafi, Mahdieh Soleymani Baghshah
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: Accepted at ICLR 2026 Conference
💡 一句话要点
针对高维离线Bandit算法,提出高效对抗攻击方法,揭示其脆弱性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗攻击 离线Bandit 奖励模型 高维数据 模型评估
📋 核心要点
- 现有Bandit算法在离线评估中,对奖励模型的对抗鲁棒性研究不足,易受攻击。
- 提出一种新的威胁模型,攻击者利用高维离线数据操纵奖励模型,劫持Bandit行为。
- 实验表明,即使微小的扰动也能显著改变Bandit行为,高维输入会加剧脆弱性。
📝 摘要(中文)
Bandit算法作为一种强大的工具,通过高效识别表现最佳的候选者,被广泛应用于评估机器学习模型,包括生成图像模型和大型语言模型。这些方法通常依赖于奖励模型,这些模型通常在Hugging Face等平台上公开发布权重,为bandit提供反馈。虽然在线评估成本高昂且需要重复试验,但使用已记录数据的离线评估已成为一种有吸引力的替代方案。然而,离线bandit评估的对抗鲁棒性在很大程度上仍未被探索,特别是当攻击者在bandit训练之前扰乱奖励模型(而不是训练数据)时。本文通过理论和实证研究,填补了这一空白,研究了离线bandit训练对奖励模型对抗性操纵的脆弱性。我们引入了一种新的威胁模型,其中攻击者利用高维环境中的离线数据来劫持bandit的行为。从线性奖励函数扩展到ReLU神经网络等非线性模型,我们研究了对用于生成模型评估的两个Hugging Face评估器的攻击:一个衡量美学质量,另一个评估组合对齐。我们的结果表明,即使对奖励模型的权重进行微小且难以察觉的扰动,也会极大地改变bandit的行为。从理论角度来看,我们证明了一个惊人的高维效应:随着输入维度的增加,成功攻击所需的扰动范数会减小,这使得图像评估等现代应用尤其容易受到攻击。大量的实验证实,朴素的随机扰动是无效的,而精心设计的针对性扰动可以实现接近完美的攻击成功率。
🔬 方法详解
问题定义:论文旨在解决高维离线Bandit算法在面对奖励模型被恶意篡改时的脆弱性问题。现有方法主要关注训练数据的对抗攻击,而忽略了奖励模型本身的安全性。在实际应用中,奖励模型(例如美学评分模型)通常以预训练权重的形式提供,攻击者可以相对容易地对其进行修改,从而影响Bandit算法的决策。
核心思路:论文的核心思路是研究如何通过对奖励模型施加微小的、难以察觉的扰动,来显著改变离线Bandit算法的行为。这种攻击旨在使Bandit算法选择次优的候选者,从而达到攻击的目的。论文特别关注高维输入的情况,并理论证明了在高维情况下,攻击所需的扰动幅度会显著减小。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义了一个新的威胁模型,其中攻击者可以访问离线数据并修改奖励模型的权重。2) 针对线性奖励函数和非线性奖励函数(ReLU神经网络)分别设计了攻击策略。3) 从理论上分析了攻击的成功率与扰动幅度之间的关系,并证明了高维效应。4) 通过实验验证了攻击的有效性,并评估了不同攻击策略的性能。
关键创新:论文最重要的技术创新点在于发现了高维效应,即随着输入维度的增加,攻击所需的扰动范数会减小。这意味着在高维空间中,即使对奖励模型进行非常微小的修改,也可能导致Bandit算法做出错误的决策。这一发现对高维数据的安全评估具有重要意义。
关键设计:论文的关键设计包括:1) 针对线性奖励函数,设计了一种基于梯度下降的攻击策略,通过迭代更新扰动,最大化攻击目标。2) 针对非线性奖励函数,采用类似的梯度下降方法,但需要考虑ReLU激活函数的非线性特性。3) 在实验中,使用了两个Hugging Face上的预训练奖励模型,分别用于评估生成图像的美学质量和组合对齐,并设计了相应的攻击目标。
🖼️ 关键图片
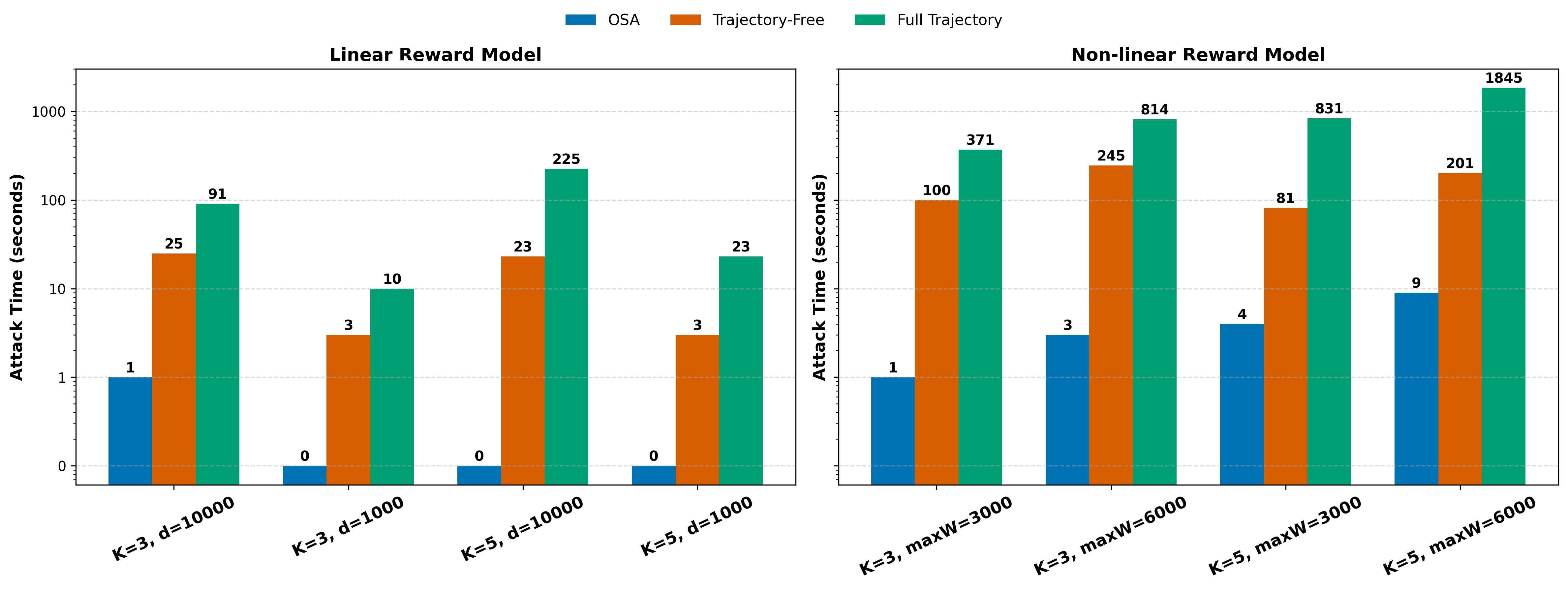
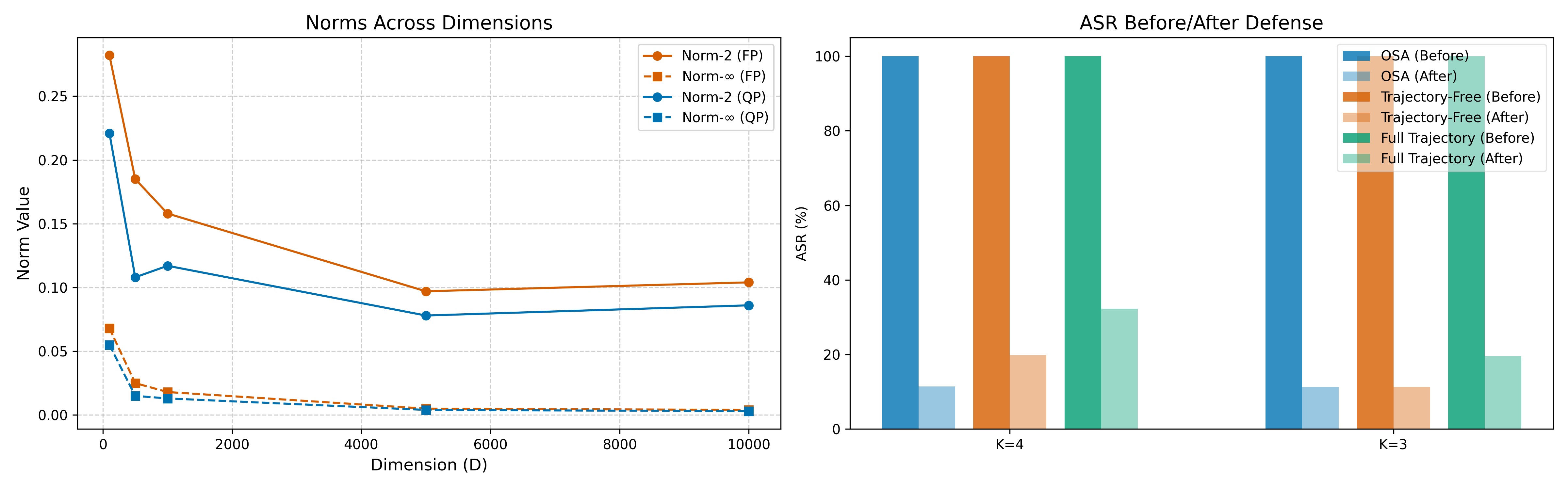

📊 实验亮点
实验结果表明,精心设计的针对性扰动可以实现接近完美的攻击成功率,即使是微小的扰动也能显著改变Bandit的行为。在高维图像评估任务中,论文验证了理论分析,即随着输入维度的增加,攻击所需的扰动幅度会减小,使得攻击更容易成功。朴素的随机扰动则效果不佳,突出了针对性攻击的重要性。
🎯 应用场景
该研究成果可应用于评估和提升机器学习模型,特别是生成模型的安全性。通过模拟对抗攻击,可以发现并修复离线Bandit算法中的潜在漏洞,提高其在实际应用中的鲁棒性。此外,该研究也为奖励模型的安全部署提供了指导,有助于防止恶意用户利用奖励模型进行攻击。
📄 摘要(原文)
Bandit algorithms have recently emerged as a powerful tool for evaluating machine learning models, including generative image models and large language models, by efficiently identifying top-performing candidates without exhaustive comparisons. These methods typically rely on a reward model, often distributed with public weights on platforms such as Hugging Face, to provide feedback to the bandit. While online evaluation is expensive and requires repeated trials, offline evaluation with logged data has become an attractive alternative. However, the adversarial robustness of offline bandit evaluation remains largely unexplored, particularly when an attacker perturbs the reward model (rather than the training data) prior to bandit training. In this work, we fill this gap by investigating, both theoretically and empirically, the vulnerability of offline bandit training to adversarial manipulations of the reward model. We introduce a novel threat model in which an attacker exploits offline data in high-dimensional settings to hijack the bandit's behavior. Starting with linear reward functions and extending to nonlinear models such as ReLU neural networks, we study attacks on two Hugging Face evaluators used for generative model assessment: one measuring aesthetic quality and the other assessing compositional alignment. Our results show that even small, imperceptible perturbations to the reward model's weights can drastically alter the bandit's behavior. From a theoretical perspective, we prove a striking high-dimensional effect: as input dimensionality increases, the perturbation norm required for a successful attack decreases, making modern applications such as image evaluation especially vulnerable. Extensive experiments confirm that naive random perturbations are ineffective, whereas carefully targeted perturbations achieve near-perfect attack success rates ...