On the Spatiotemporal Dynamics of Generalization in Neural Networks
作者: Zichao Wei
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出SEAD架构,通过模拟物理约束实现神经网络的长度泛化能力。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 长度泛化 物理约束 神经元胞自动机 时空演化 吸引子动力学
📋 核心要点
- 传统神经网络在处理序列长度泛化问题时存在困难,无法像人类一样将学习到的规则应用于任意长度的序列。
- 论文提出SEAD架构,通过模拟物理世界的局部性、对称性和稳定性约束,使神经网络具备更好的泛化能力。
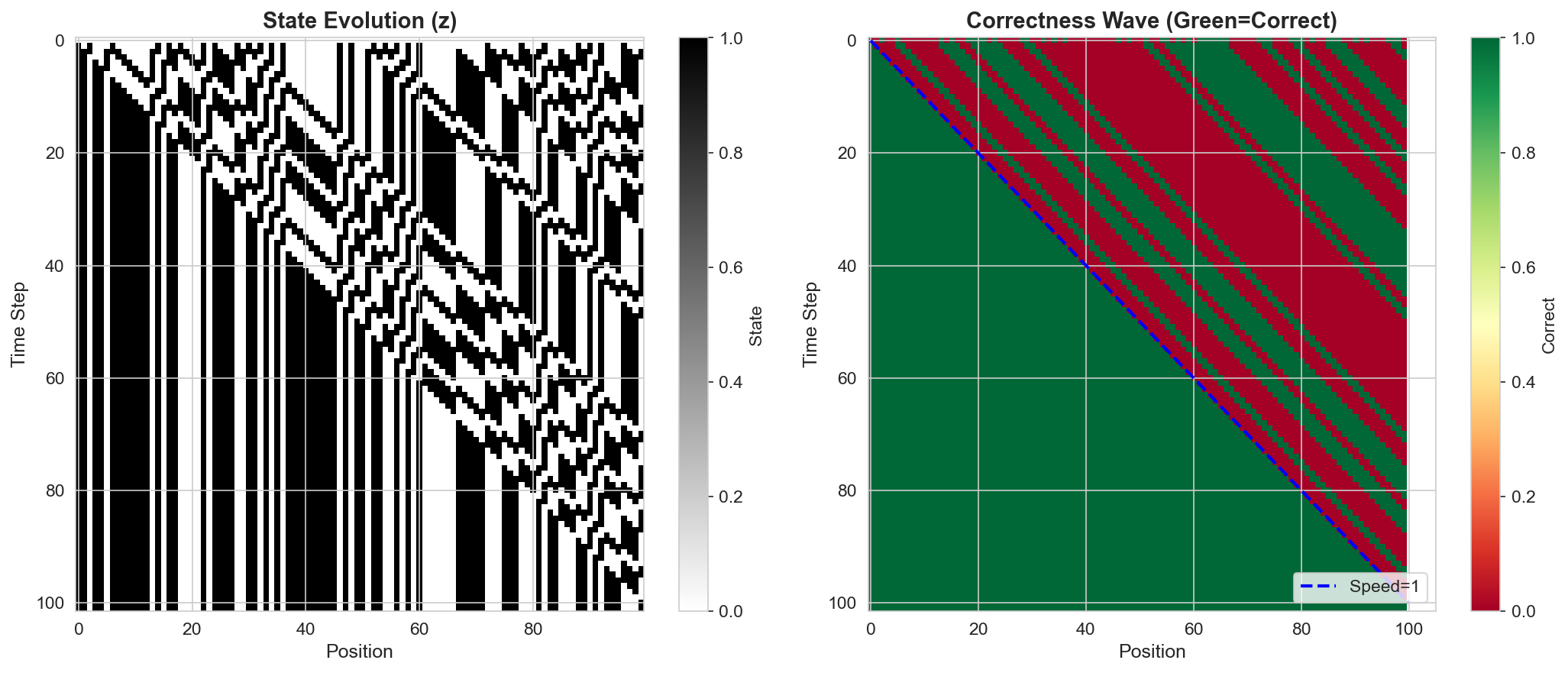
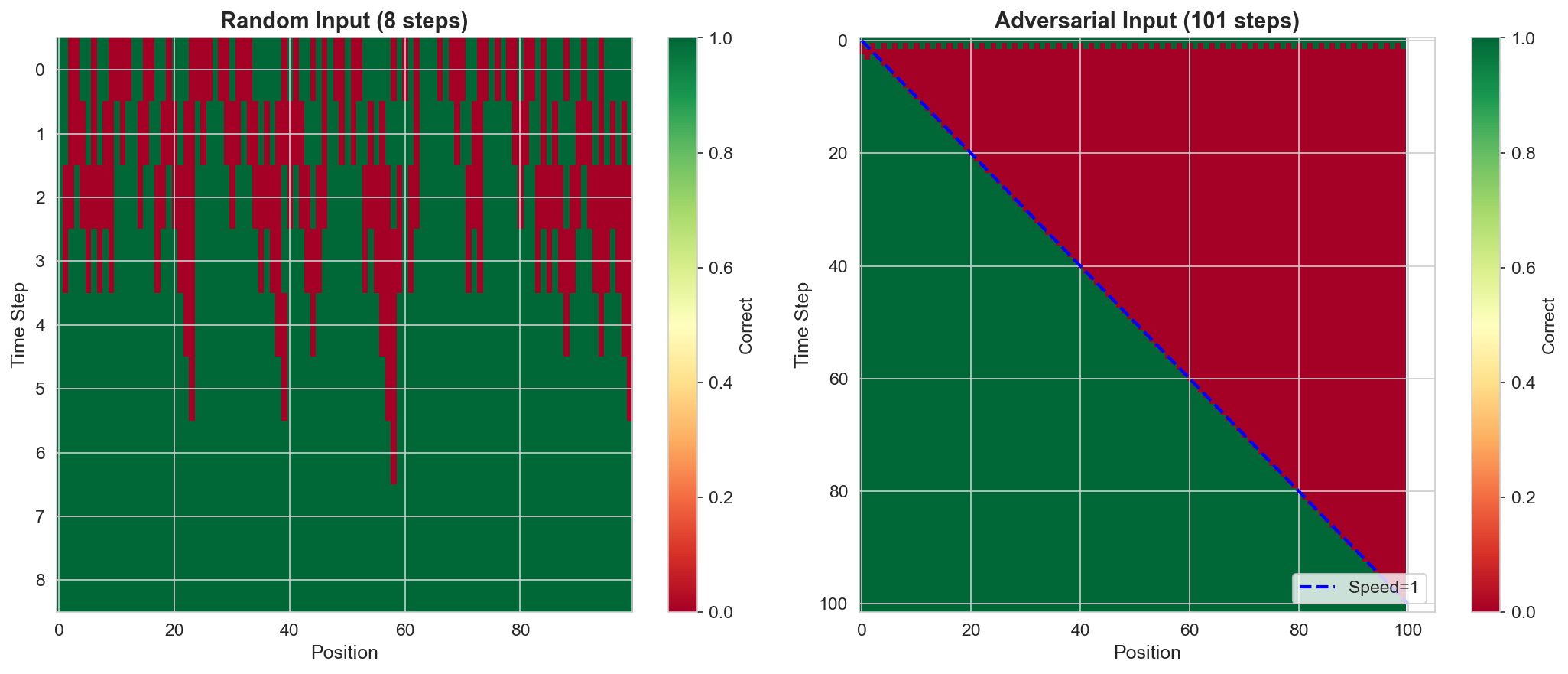
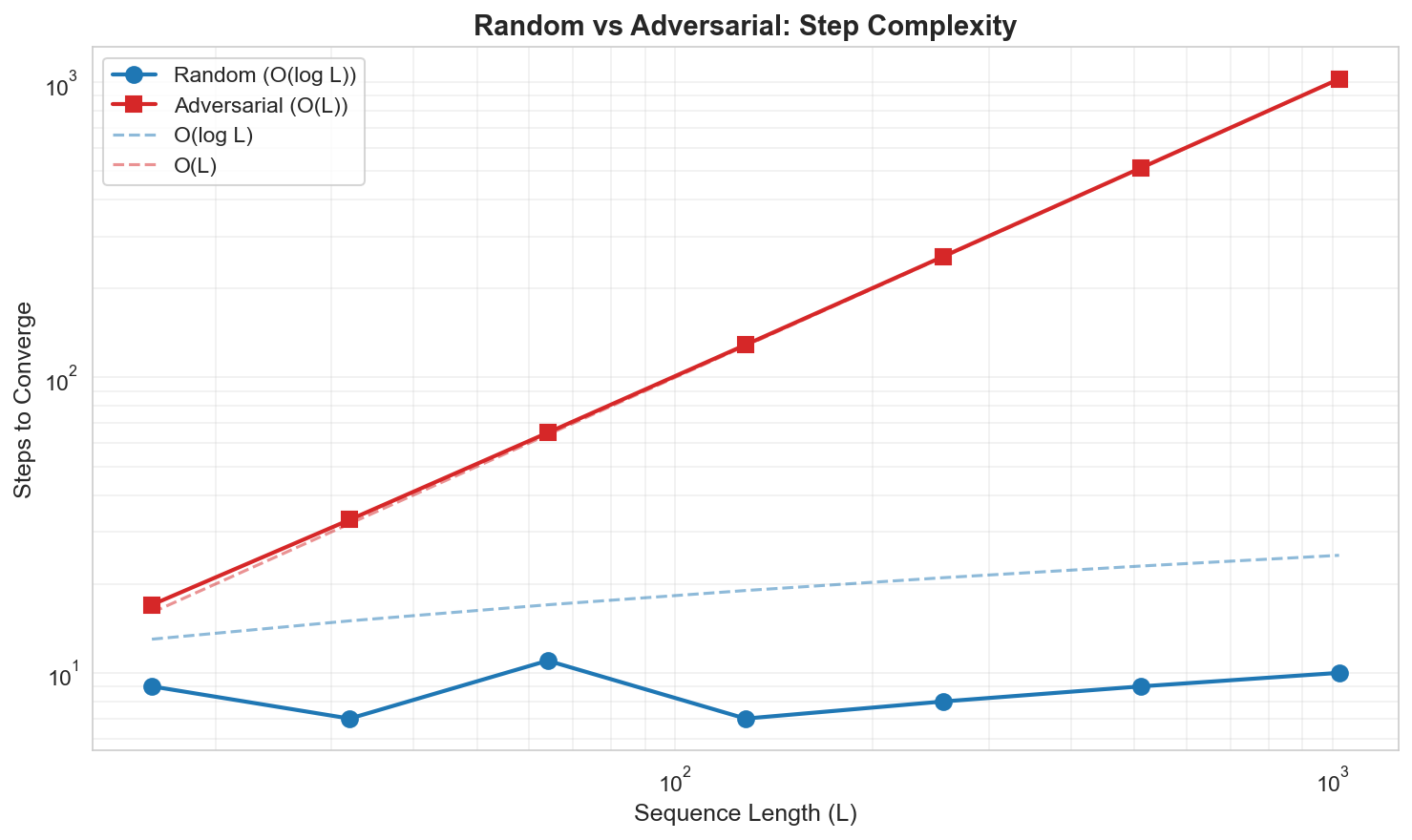
- 实验表明,SEAD架构在奇偶校验、加法和Rule 110等任务上表现出强大的长度泛化能力和输入自适应计算能力。
📝 摘要(中文)
本文探讨了神经网络在从短序列泛化到长序列时失败的原因,认为这并非工程问题,而是违反了物理基本假设。受物理学启发,作者提出了泛化系统必须满足的三个约束:(1) 局部性——信息以有限速度传播;(2) 对称性——计算规律在空间和时间上不变;(3) 稳定性——系统收敛到抵抗噪声累积的离散吸引子。基于这些假设,作者推导出了时空演化与吸引子动力学(SEAD)架构,这是一种神经元胞自动机,其中局部卷积规则被迭代直到收敛。在三个任务上的实验验证了该理论:(1) 奇偶校验——通过光锥传播展示了完美的长度泛化;(2) 加法——实现了从L=16到L=100万的尺度不变推理,准确率达到100%,并表现出输入自适应计算;(3) Rule 110——学习了一个图灵完备的元胞自动机,没有轨迹发散。结果表明,统计学习和逻辑推理之间的差距可以通过尊重计算的物理特性来弥合,而不是通过缩放参数。
🔬 方法详解
问题定义:神经网络在序列长度泛化方面存在根本性缺陷,例如,在短序列上训练的加法模型无法泛化到长序列。现有方法通常依赖于增加模型参数或使用注意力机制,但未能从根本上解决问题,缺乏对计算过程物理约束的考虑。
核心思路:论文的核心思路是借鉴物理学原理,将计算过程视为一种物理过程,并引入局部性、对称性和稳定性这三个物理约束。通过在神经网络架构中显式地体现这些约束,可以提高模型的泛化能力,使其能够处理任意长度的序列。
技术框架:SEAD架构是一种神经元胞自动机,其核心思想是在局部范围内应用卷积规则,并通过迭代更新直到收敛。整体流程包括:(1) 输入序列编码;(2) 局部卷积规则的应用;(3) 迭代更新状态;(4) 收敛判断;(5) 输出结果解码。该架构的关键在于局部卷积规则的设计和迭代更新机制。
关键创新:SEAD架构的关键创新在于其对物理约束的显式建模。与传统的神经网络不同,SEAD架构不是通过学习大量数据来拟合函数,而是通过模拟物理过程来实现计算。这种方法使得模型具有更好的泛化能力和鲁棒性。
关键设计:SEAD架构的关键设计包括:(1) 局部卷积核的设计,用于模拟局部信息传播;(2) 迭代更新规则,用于模拟时间演化;(3) 吸引子动力学,用于保证计算的稳定性。具体的参数设置和网络结构需要根据不同的任务进行调整,但整体框架保持不变。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SEAD架构在奇偶校验任务上实现了完美的长度泛化,在加法任务上实现了从L=16到L=100万的尺度不变推理,准确率达到100%。此外,SEAD架构还成功学习了图灵完备的元胞自动机Rule 110,没有出现轨迹发散现象。这些结果表明,SEAD架构在长度泛化和逻辑推理方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要序列长度泛化的场景,例如自然语言处理、时间序列分析和控制系统。通过模拟物理约束,可以构建更加鲁棒和泛化的神经网络模型,从而提高人工智能系统的性能和可靠性。该方法在需要处理长序列或复杂逻辑推理的任务中具有潜在的应用价值。
📄 摘要(原文)
Why do neural networks fail to generalize addition from 16-digit to 32-digit numbers, while a child who learns the rule can apply it to arbitrarily long sequences? We argue that this failure is not an engineering problem but a violation of physical postulates. Drawing inspiration from physics, we identify three constraints that any generalizing system must satisfy: (1) Locality -- information propagates at finite speed; (2) Symmetry -- the laws of computation are invariant across space and time; (3) Stability -- the system converges to discrete attractors that resist noise accumulation. From these postulates, we derive -- rather than design -- the Spatiotemporal Evolution with Attractor Dynamics (SEAD) architecture: a neural cellular automaton where local convolutional rules are iterated until convergence. Experiments on three tasks validate our theory: (1) Parity -- demonstrating perfect length generalization via light-cone propagation; (2) Addition -- achieving scale-invariant inference from L=16 to L=1 million with 100% accuracy, exhibiting input-adaptive computation; (3) Rule 110 -- learning a Turing-complete cellular automaton without trajectory divergence. Our results suggest that the gap between statistical learning and logical reasoning can be bridged -- not by scaling parameters, but by respecting the physics of computation.