Adaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
作者: Hieu Trung Nguyen, Bao Nguyen, Wenao Ma, Yuzhi Zhao, Ruifeng She, Viet Anh Nguyen
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-02
备注: Accepted at ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出VIP算法,通过自适应rollout分配提升可验证奖励在线强化学习的采样效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 在线学习 采样效率 rollout分配 高斯过程
📋 核心要点
- 现有基于组的策略优化方法采用固定rollout分配,忽略了不同训练提示的信息量差异,导致采样效率低下。
- VIP算法通过预测每个提示的成功概率,并将其转化为方差估计,从而优化rollout分配,最小化策略更新的梯度方差。
- 实验结果表明,VIP算法在多个基准测试中显著提高了采样效率,并优于均匀分配等基线方法。
📝 摘要(中文)
在具有可验证奖励的强化学习中,采样效率是一个关键瓶颈。现有的基于组的策略优化方法(如GRPO)为所有训练提示分配固定数量的rollout。这种均匀分配隐式地将所有提示视为信息量相等,可能导致计算预算使用效率低下并阻碍训练进度。我们提出了VIP算法,这是一种方差感知预测分配策略,它将给定的rollout预算分配给当前批次中的提示,以最小化策略更新的预期梯度方差。在每次迭代中,VIP使用轻量级高斯过程模型来预测基于最近rollout的每个提示的成功概率。这些概率预测被转换为方差估计,然后输入到凸优化问题中,以确定在硬计算预算约束下的最佳rollout分配。经验结果表明,在多个基准测试中,VIP始终提高采样效率,并实现比均匀或启发式分配策略更高的性能。我们的代码将在https://github.com/HieuNT91/VIP上提供。
🔬 方法详解
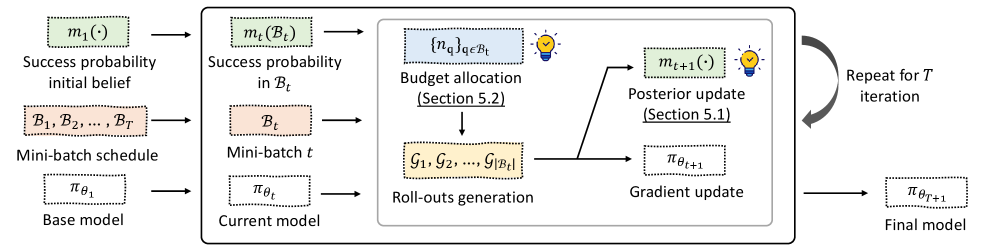
问题定义:在可验证奖励的在线强化学习中,如何高效地利用有限的计算资源进行策略优化是一个关键问题。现有的方法,例如GRPO,对所有训练提示采用统一的rollout分配策略,没有考虑到不同提示所包含的信息量差异。这种做法导致计算资源分配不均,降低了采样效率,最终影响了策略的学习效果。
核心思路:VIP算法的核心思想是根据每个训练提示所包含的信息量动态地分配rollout。具体来说,算法预测每个提示的成功概率,并将其转化为方差估计,然后通过求解一个凸优化问题,在满足计算预算约束的前提下,找到最优的rollout分配方案。这样可以确保更多计算资源被分配给信息量更大的提示,从而提高采样效率和策略学习速度。
技术框架:VIP算法的整体框架包括以下几个主要步骤:1. 成功概率预测:使用轻量级高斯过程模型,基于最近的rollout数据,预测每个训练提示的成功概率。2. 方差估计:将预测的成功概率转化为方差估计,用于衡量每个提示的信息量。3. Rollout分配优化:构建一个凸优化问题,以最小化策略更新的预期梯度方差为目标,同时满足计算预算约束。通过求解该优化问题,得到每个提示的最优rollout分配数量。4. 策略更新:根据分配的rollout数量,执行策略更新。
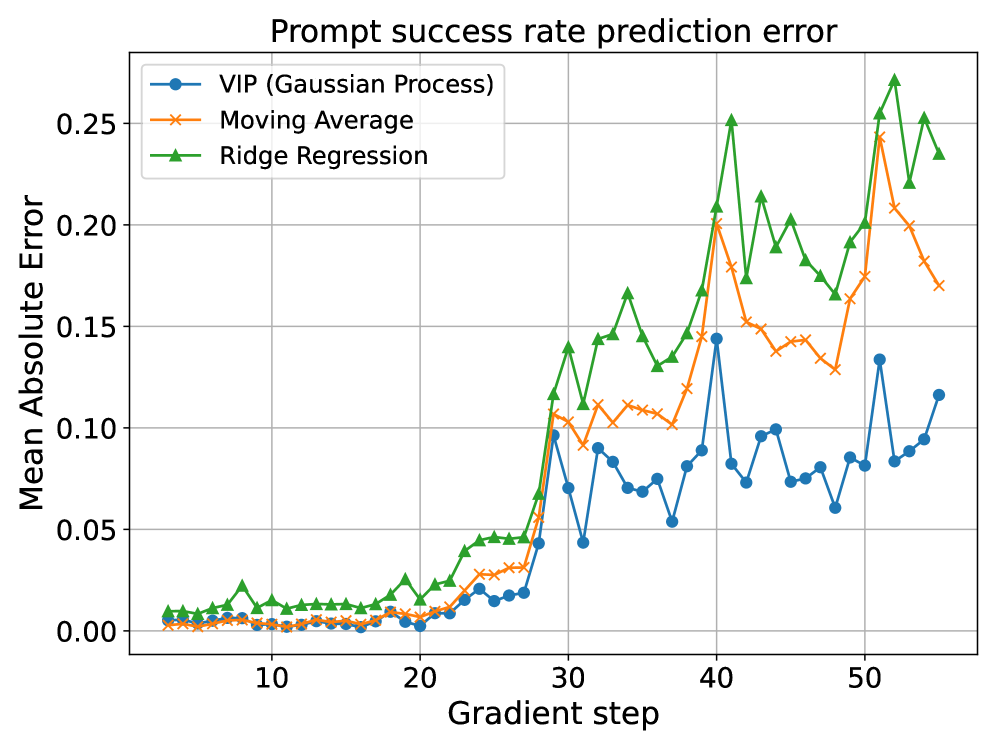
关键创新:VIP算法的关键创新在于提出了一种方差感知的rollout分配策略。与现有方法采用的固定分配策略不同,VIP算法能够根据每个训练提示的信息量动态地调整rollout分配,从而更有效地利用计算资源。此外,VIP算法使用轻量级高斯过程模型进行成功概率预测,降低了计算复杂度。
关键设计:VIP算法的关键设计包括:1. 高斯过程模型:用于预测每个提示的成功概率,采用高斯核函数。2. 凸优化问题:目标函数为最小化策略更新的预期梯度方差,约束条件为计算预算约束。3. 计算预算约束:限制总的rollout数量,确保算法在有限的计算资源下运行。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VIP算法在多个基准测试中显著提高了采样效率,并优于均匀分配等基线方法。例如,在某个任务中,VIP算法能够以更少的rollout数量达到与基线方法相同的性能水平,或者在相同的rollout数量下,VIP算法能够获得更高的奖励值。具体性能提升幅度取决于具体的任务和环境设置。
🎯 应用场景
VIP算法可应用于各种需要在线强化学习和可验证奖励的场景,例如机器人控制、自动驾驶、游戏AI等。通过提高采样效率,VIP算法能够加速策略学习过程,降低训练成本,并提升最终策略的性能。该算法尤其适用于计算资源有限的场景,例如嵌入式系统或移动设备。
📄 摘要(原文)
Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce \Ours, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, \Ours~uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that \Ours~consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks. Our code will be available at https://github.com/HieuNT91/VIP.