Generative Visual Code Mobile World Models
作者: Woosung Koh, Sungjun Han, Segyu Lee, Se-Young Yun, Jamin Shin
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-02-02
备注: Pre-print (technical report)
💡 一句话要点
提出基于可渲染代码生成的移动GUI世界模型gWorld,提升移动GUI代理性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 移动GUI 世界模型 视觉-语言模型 代码生成 GUI自动化
📋 核心要点
- 现有移动GUI世界模型存在视觉保真度和文本渲染精度之间的权衡,文本模型牺牲视觉效果,视觉模型依赖复杂pipeline。
- 论文提出通过VLM生成可渲染的web代码来表示GUI状态,结合了语言先验知识和结构化代码的视觉生成能力。
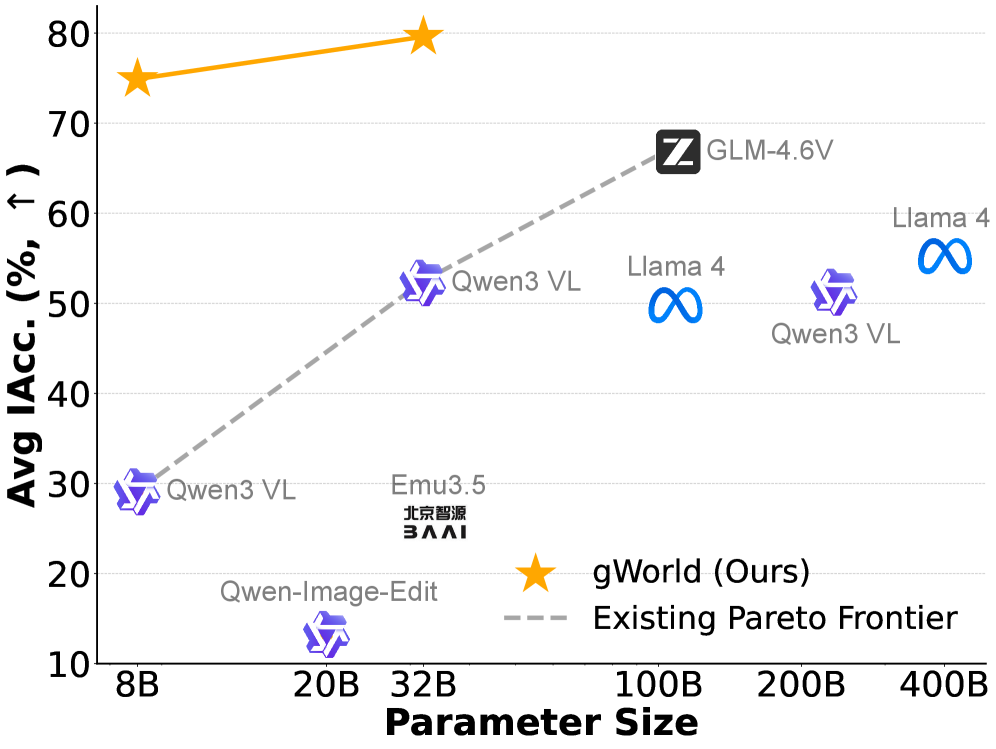
- 实验表明,gWorld在精度和模型大小方面优于现有模型,并且数据规模和pipeline组件对性能有积极影响。
📝 摘要(中文)
本文提出了一种新的视觉世界建模范式:通过可渲染代码生成进行视觉世界建模。该方法使用单个视觉-语言模型(VLM)预测下一个GUI状态,并将其表示为可执行的web代码,然后渲染成像素,而不是直接生成像素。这种方法结合了两种现有方法的优点:VLM保留了其语言先验知识,可以进行精确的文本渲染,同时VLM在结构化web代码上的预训练使其能够进行高保真的视觉生成。我们推出了gWorld (8B, 32B),这是第一个基于此范式的开源视觉移动GUI世界模型,以及一个自动合成基于代码的训练数据的数据生成框架(gWorld)。在对4个分布内和2个分布外基准的广泛评估中,gWorld在精度与模型大小方面设置了新的帕累托前沿,优于8个规模超过其50.25倍的前沿开源模型。进一步的分析表明:(1)通过gWorld扩展训练数据可以产生有意义的收益;(2)我们pipeline的每个组件都提高了数据质量;(3)更强的世界建模能力可以提高下游移动GUI策略的性能。
🔬 方法详解
问题定义:现有移动GUI世界模型在训练和推理时面临性能瓶颈。基于文本的世界模型缺乏视觉保真度,而基于视觉的世界模型在精确文本渲染方面存在困难,导致其依赖于缓慢且复杂的pipeline,需要多个外部模型支持。这限制了移动GUI代理的性能提升。
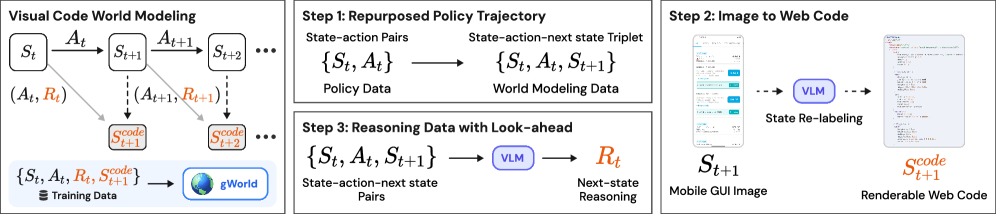
核心思路:论文的核心思路是利用视觉-语言模型(VLM)生成可执行的web代码来表示GUI状态,而不是直接生成像素。这种方法结合了VLM的语言理解能力和结构化代码的视觉生成能力,从而在视觉保真度和文本渲染精度之间取得平衡。通过将GUI状态表示为代码,可以利用VLM在代码上的预训练优势,实现更高效和准确的GUI建模。
技术框架:gWorld的整体框架包含数据生成和模型训练两个主要阶段。首先,使用gWorld数据生成框架自动合成基于代码的训练数据。然后,使用这些数据训练VLM,使其能够预测下一个GUI状态的web代码。在推理阶段,VLM生成web代码,然后将其渲染成像素,用于下游任务,例如移动GUI策略学习。
关键创新:最重要的技术创新点在于使用可渲染代码作为GUI状态的表示形式。与直接生成像素或使用文本描述相比,这种方法能够更好地结合视觉和语言信息,并利用VLM在代码上的预训练优势。此外,gWorld数据生成框架能够自动合成大规模的训练数据,解决了数据稀缺的问题。
关键设计:gWorld模型使用了8B和32B两种不同规模的VLM。数据生成框架包含多个组件,用于提高数据质量,例如布局解析、内容生成和代码优化。损失函数包括代码生成损失和视觉重建损失,用于优化VLM的生成能力和视觉保真度。具体的网络结构和参数设置在论文中有详细描述,但未在此处明确给出。
🖼️ 关键图片

📊 实验亮点
gWorld在4个分布内和2个分布外基准测试中,均优于其他开源模型,尤其是在精度和模型大小的帕累托前沿上取得了显著突破。gWorld在性能上超越了规模大于其50.25倍的模型,证明了其高效性和可扩展性。实验还表明,通过gWorld框架生成更多训练数据可以有效提升模型性能。
🎯 应用场景
该研究成果可应用于移动GUI自动化、智能助手、用户界面设计等领域。通过更精确地模拟GUI环境,可以提高移动代理的决策能力和交互效率。未来,该技术有望应用于更复杂的交互式环境中,例如虚拟现实和增强现实。
📄 摘要(原文)
Mobile Graphical User Interface (GUI) World Models (WMs) offer a promising path for improving mobile GUI agent performance at train- and inference-time. However, current approaches face a critical trade-off: text-based WMs sacrifice visual fidelity, while the inability of visual WMs in precise text rendering led to their reliance on slow, complex pipelines dependent on numerous external models. We propose a novel paradigm: visual world modeling via renderable code generation, where a single Vision-Language Model (VLM) predicts the next GUI state as executable web code that renders to pixels, rather than generating pixels directly. This combines the strengths of both approaches: VLMs retain their linguistic priors for precise text rendering while their pre-training on structured web code enables high-fidelity visual generation. We introduce gWorld (8B, 32B), the first open-weight visual mobile GUI WMs built on this paradigm, along with a data generation framework (gWorld) that automatically synthesizes code-based training data. In extensive evaluation across 4 in- and 2 out-of-distribution benchmarks, gWorld sets a new pareto frontier in accuracy versus model size, outperforming 8 frontier open-weight models over 50.25x larger. Further analyses show that (1) scaling training data via gWorld yields meaningful gains, (2) each component of our pipeline improves data quality, and (3) stronger world modeling improves downstream mobile GUI policy performance.