A Relative-Budget Theory for Reinforcement Learning with Verifiable Rewards in Large Language Model Reasoning
作者: Akifumi Wachi, Hirota Kinoshita, Shokichi Takakura, Rei Higuchi, Taiji Suzuki
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-02
备注: 28 pages
💡 一句话要点
提出相对预算理论以优化大语言模型的强化学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 相对预算 样本效率 推理能力 在线学习 奖励方差
📋 核心要点
- 现有的强化学习方法在不同任务和计算预算下的有效性差异较大,缺乏统一的理论框架来解释这种现象。
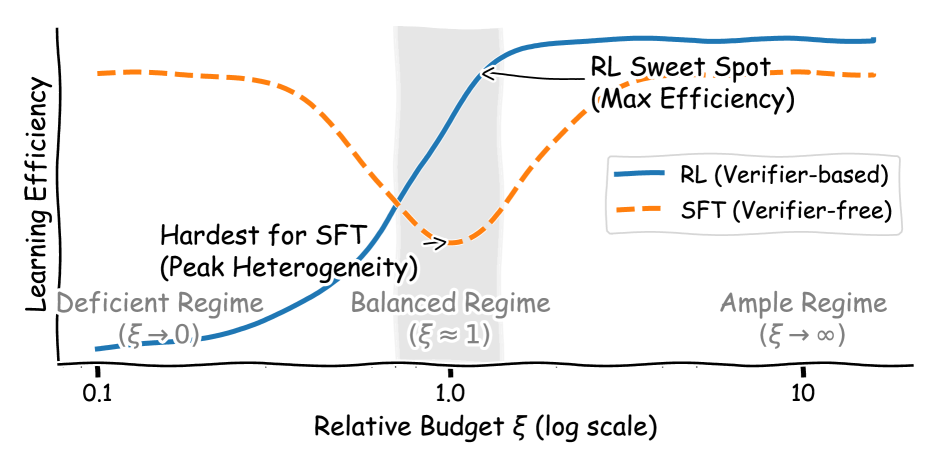
- 本文提出相对预算理论,通过相对预算量$ξ$来分析样本效率与奖励方差之间的关系,从而优化RL的学习过程。
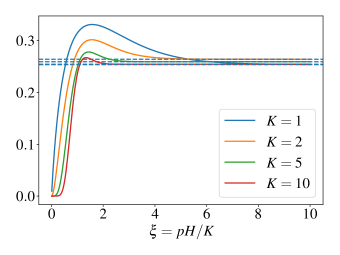
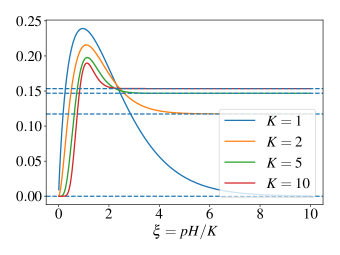
- 实证研究表明,最佳的相对预算范围为$ξ ext{in}[1.5, 2.0]$,在此范围内学习效率最高,推理性能达到峰值。
📝 摘要(中文)
强化学习(RL)是提升大语言模型推理能力的主要方法,但其有效性在不同任务和计算预算下存在差异。本文提出了一种相对预算理论,通过一个名为相对预算的量$ξ:= H/ ext{E}[T]$来解释这种差异,其中$H$是生成视野(token预算),$T$是基策略下第一个正确解决方案所需的token数量。研究表明,$ξ$通过控制奖励方差和信息轨迹的可能性来决定样本效率。分析揭示了三种状态:在不足状态($ξ o 0$)下,信息轨迹稀少,样本复杂度激增;在平衡状态($ξ=Θ(1)$)下,信息轨迹以非忽略概率出现,RL的样本效率最高;在充足状态($ξ o ext{∞}$)下,学习稳定但每次迭代的边际收益减少。实证结果确认了这些预测,识别出一个预算$ξ ext{in}[1.5, 2.0]$,最大化学习效率并与推理性能峰值一致。
🔬 方法详解
问题定义:本文旨在解决强化学习在不同任务和计算预算下效果不均的问题,现有方法未能有效解释和优化这一现象。
核心思路:提出相对预算理论,通过定义相对预算$ξ$来分析样本效率,控制奖励方差和信息轨迹的可能性,从而提升学习效率。
技术框架:整体框架包括三个主要阶段:定义相对预算,分析不同状态下的样本效率,以及提供在线RL的有限样本保证。
关键创新:相对预算理论是本文的核心创新,首次通过单一量$ξ$来统一解释RL的样本效率,揭示了不同状态下的学习特性。
关键设计:关键参数包括生成视野$H$和第一个正确解决方案所需的token数量$T$,通过这些参数的设置,能够有效控制学习过程中的奖励方差和信息轨迹。
🖼️ 关键图片
📊 实验亮点
实验结果表明,最佳的相对预算范围为$ξ ext{in}[1.5, 2.0]$,在此范围内,学习效率显著提高,推理性能达到峰值,验证了理论分析的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能对话系统和自动化推理等。通过优化强化学习的样本效率,能够显著提升大语言模型在复杂任务中的表现,具有重要的实际价值和广泛的未来影响。
📄 摘要(原文)
Reinforcement learning (RL) is a dominant paradigm for improving the reasoning abilities of large language models, yet its effectiveness varies across tasks and compute budgets. We propose a \emph{relative-budget} theory explaining this variation through a single quantity called relative budget $ξ:= H/\mathbb{E}[T]$, where $H$ is the generation horizon (token budget) and $T$ denotes the number of tokens until the first correct solution under a base policy. We show that $ξ$ determines sample efficiency by controlling reward variance and the likelihood of informative trajectories. Our analysis reveals three regimes: in the \emph{deficient} regime ($ξ\to 0$), informative trajectories are rare and the sample complexity explodes; in the \emph{balanced} regime ($ξ=Θ(1)$), informative trajectories occur with non-negligible probability and RL is maximally sample-efficient; and in the \emph{ample} regime ($ξ\to \infty$), learning remains stable but marginal gains per iteration diminish. We further provide finite-sample guarantees for online RL that characterize learning progress across these regimes. Specifically, in a case study under idealized distributional assumptions, we show that the relative budget grows linearly over iterations. Our empirical results confirm these predictions in realistic settings, identifying a budget $ξ\in [1.5, 2.0]$ that maximizes learning efficiency and coincides with peak reasoning performance.