When Is Rank-1 Enough? Geometry-Guided Initialization for Parameter-Efficient Fine-Tuning
作者: Haoran Zhao, Soyeon Caren Han, Eduard Hovy
分类: cs.LG, cs.CV
发布日期: 2026-02-02
💡 一句话要点
提出Gap-Init方法,通过几何引导初始化稳定极低秩LoRA微调,提升多模态大模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 LoRA 多模态学习 视觉语言模型 初始化方法 几何感知 低秩优化
📋 核心要点
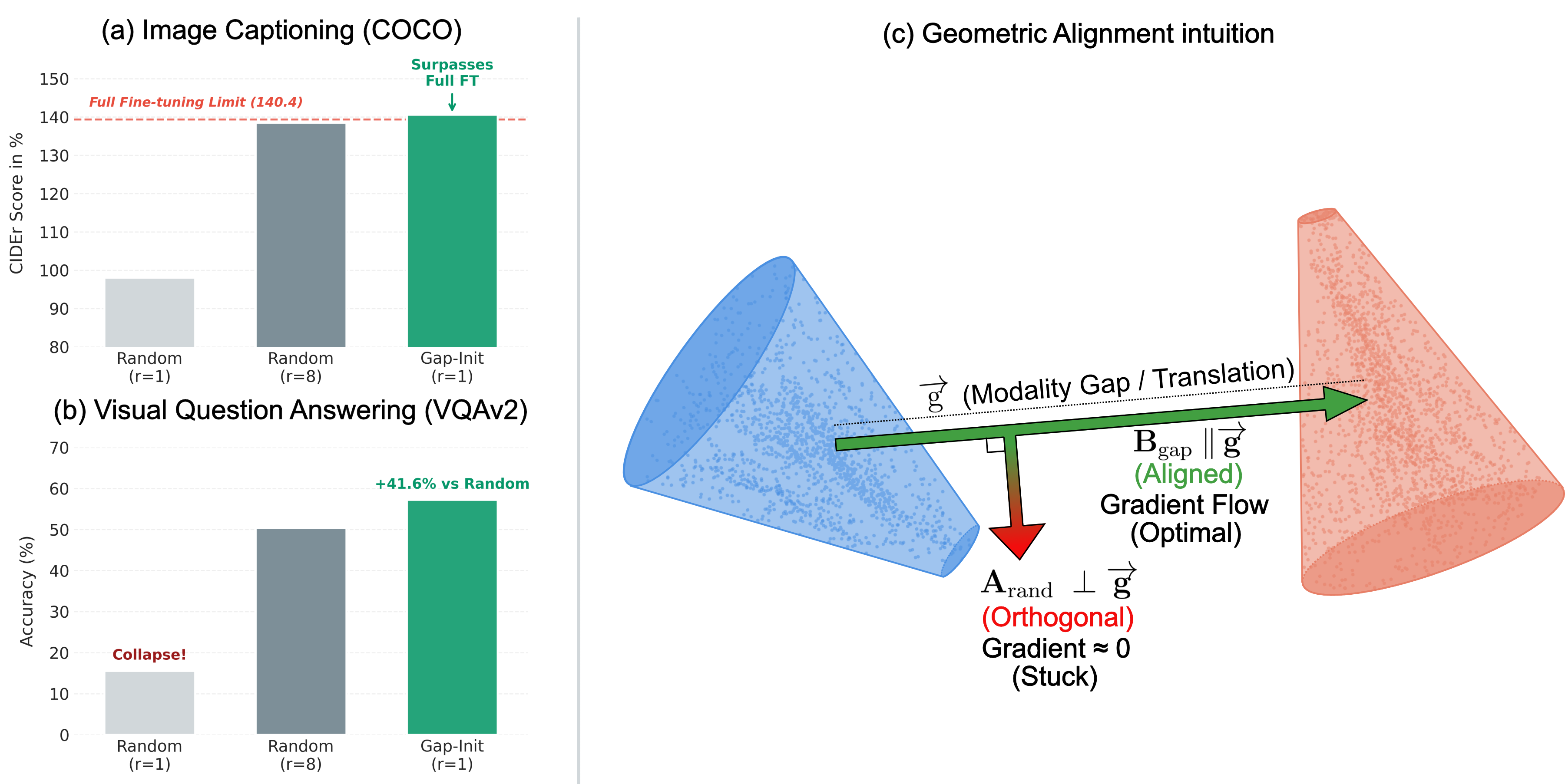
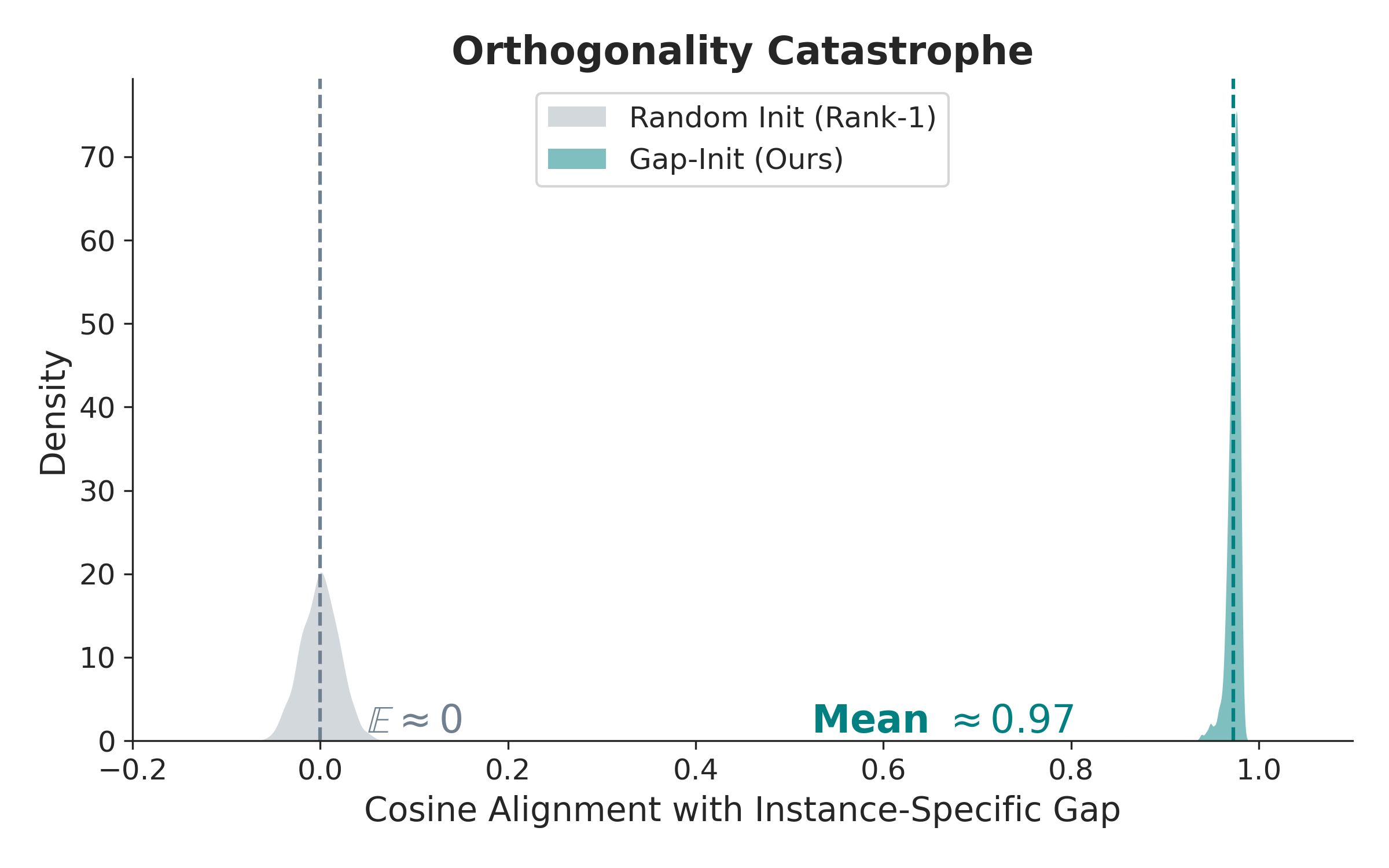
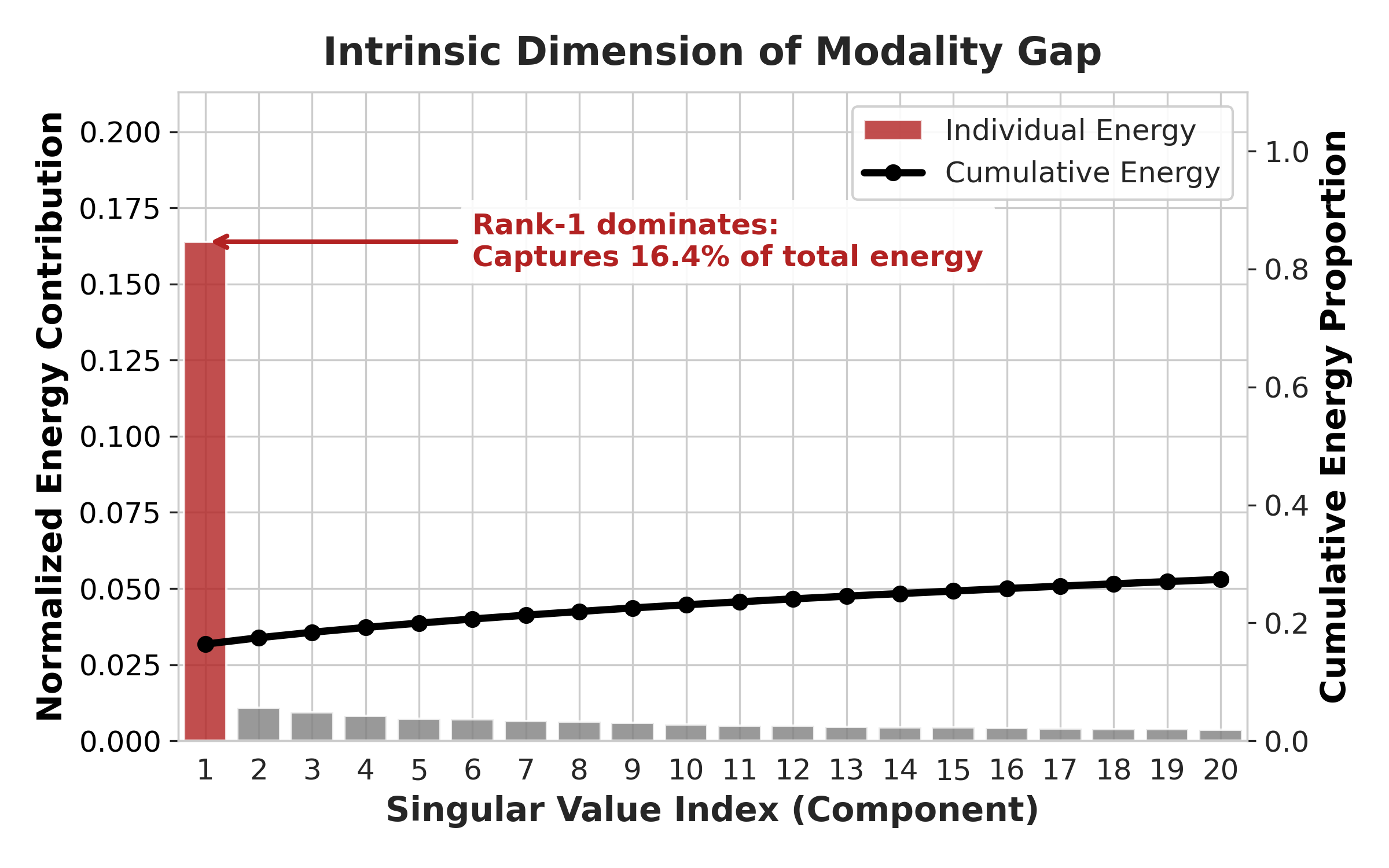
- 极低秩LoRA微调(尤其是秩为1)在多模态大模型中训练不稳定,并非单纯因容量限制,而是对更新方向过于敏感。
- 提出Gap-Init,通过几何感知初始化,将LoRA方向与模态gap向量对齐,避免早期梯度消失,稳定训练。
- 实验表明,Gap-Init能有效稳定秩为1的LoRA训练,性能可媲美甚至超越秩为8的LoRA基线。
📝 摘要(中文)
参数高效微调(PEFT)是调整多模态大型语言模型的标准方法,但极低秩设置(尤其是秩为1的LoRA)通常不稳定。本文表明,这种不稳定性不仅仅是由于容量有限:在秩为1的情况下,优化对更新方向高度敏感。具体而言,预训练的视觉和文本特征形成不匹配的各向异性区域,产生一个主要的“gap”方向,该方向类似于平移分量,并在秩为1的约束下不成比例地引导早期梯度。通过分析预训练的表示,我们识别出一个模态gap轴,该轴主导了早期梯度流,而随机秩为1的初始化不太可能与它对齐,从而导致梯度微弱和训练崩溃。我们提出了Gap-Init,这是一种几何感知初始化方法,它将秩为1的LoRA方向与来自小型校准集的估计模态gap向量对齐,同时保持初始LoRA更新为零。在多个视觉语言任务和骨干网络中,Gap-Init始终稳定秩为1的训练,并且可以匹配或优于强大的秩为8的基线。我们的结果表明,在极低秩限制下,初始对齐与秩本身同样重要。
🔬 方法详解
问题定义:论文旨在解决多模态大模型中,使用极低秩(尤其是秩为1)LoRA进行参数高效微调时,训练过程不稳定的问题。现有的随机初始化方法无法有效利用极低秩LoRA的潜力,导致训练早期梯度消失,模型性能下降。
核心思路:论文的核心思路是,在LoRA初始化时,并非随机初始化,而是通过几何感知的方式,将LoRA的更新方向与预训练的视觉和文本特征之间的“模态gap”方向对齐。这种对齐能够确保LoRA在训练初期就能有效地调整模型,避免梯度消失,从而稳定训练过程。
技术框架:Gap-Init方法主要包含以下几个步骤:1) 使用少量校准数据集,计算预训练的视觉和文本特征之间的模态gap向量。2) 将秩为1的LoRA矩阵的更新方向初始化为与模态gap向量对齐。3) 在训练过程中,保持LoRA的初始更新为零,以确保模型在训练初期不会发生剧烈变化。
关键创新:Gap-Init的关键创新在于其几何感知的初始化策略。与传统的随机初始化方法不同,Gap-Init充分利用了预训练特征的几何信息,通过对齐模态gap向量,实现了更有效的参数初始化。这种初始化方法能够显著提高极低秩LoRA的训练稳定性,并提升模型性能。
关键设计:Gap-Init的关键设计包括:1) 模态gap向量的计算方式,通常采用计算视觉和文本特征均值之间的差值。2) LoRA矩阵的初始化方式,确保其更新方向与模态gap向量对齐,同时保持初始更新为零。3) 校准数据集的大小,需要足够小以保证参数高效性,同时又需要足够大以准确估计模态gap向量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在多个视觉语言任务和骨干网络上,Gap-Init能够显著稳定秩为1的LoRA训练,并且可以匹配甚至超越秩为8的LoRA基线。例如,在VQA任务上,使用Gap-Init的秩为1的LoRA模型可以达到与秩为8的LoRA模型相当的性能,同时参数量减少了8倍。
🎯 应用场景
该研究成果可应用于各种视觉-语言任务,例如图像描述、视觉问答、跨模态检索等。通过使用Gap-Init方法,可以显著降低微调多模态大模型的计算成本和存储需求,使其更容易部署在资源受限的设备上。此外,该方法还有助于提高模型的泛化能力和鲁棒性。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) is a standard way to adapt multimodal large language models, yet extremely low-rank settings -- especially rank-1 LoRA -- are often unstable. We show that this instability is not solely due to limited capacity: in the rank-1 regime, optimization is highly sensitive to the update direction. Concretely, pretrained vision and text features form mismatched anisotropic regions, yielding a dominant "gap" direction that acts like a translation component and disproportionately steers early gradients under rank-1 constraints. Analyzing pretrained representations, we identify a modality-gap axis that dominates early gradient flow, while a random rank-1 initialization is unlikely to align with it, leading to weak gradients and training collapse. We propose Gap-Init, a geometry-aware initialization that aligns the rank-1 LoRA direction with an estimated modality-gap vector from a small calibration set, while keeping the initial LoRA update zero. Across multiple vision-language tasks and backbones, Gap-Init consistently stabilizes rank-1 training and can match or outperform strong rank-8 baselines. Our results suggest that at the extreme low-rank limit, initial alignment can matter as much as rank itself.