FOCUS: DLLMs Know How to Tame Their Compute Bound
作者: Kaihua Liang, Xin Tan, An Zhong, Hong Xu, Marco Canini
分类: cs.LG, cs.AR, cs.CL
发布日期: 2026-01-30
备注: 22 pages, 15 figures
🔗 代码/项目: GITHUB
💡 一句话要点
FOCUS:通过动态计算分配,显著提升扩散语言模型(DLLM)的推理吞吐量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 推理加速 动态计算分配 注意力机制 吞吐量优化
📋 核心要点
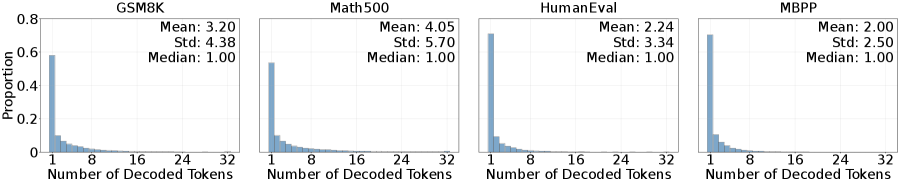
- 扩散语言模型解码计算成本高昂,主要瓶颈在于并行计算中大量算力浪费在不可解码的token上。
- FOCUS通过动态聚焦可解码token并剔除不可解码token,有效提升了计算效率和批处理大小。
- 实验结果表明,FOCUS在多个基准测试中显著提升了吞吐量,最高可达3.52倍,同时保持或提升了生成质量。
📝 摘要(中文)
扩散语言模型(DLLM)为自回归模型提供了一种引人注目的替代方案,但其部署受到高昂解码成本的限制。本文发现DLLM解码中的一个关键低效之处:虽然计算在token块上并行化,但每个扩散步骤中只有一小部分token是可解码的,导致大部分计算浪费在不可解码的token上。进一步观察到,注意力机制导出的token重要性和token级别的解码概率之间存在很强的相关性。基于此,我们提出了FOCUS——一个专为DLLM设计的推理系统。通过动态地将计算集中在可解码的token上,并动态地剔除不可解码的token,FOCUS提高了有效批处理大小,缓解了计算限制,并实现了可扩展的吞吐量。经验评估表明,FOCUS在多个基准测试中实现了高达3.52倍于生产级引擎LMDeploy的吞吐量提升,同时保持或提高了生成质量。FOCUS系统已在GitHub上公开。
🔬 方法详解
问题定义:扩散语言模型(DLLM)的推理成本高,限制了其广泛应用。现有方法在解码过程中,虽然采用并行计算,但由于每个扩散步骤中只有少量token是可解码的,导致大量计算资源被浪费在处理不可解码的token上,效率低下。
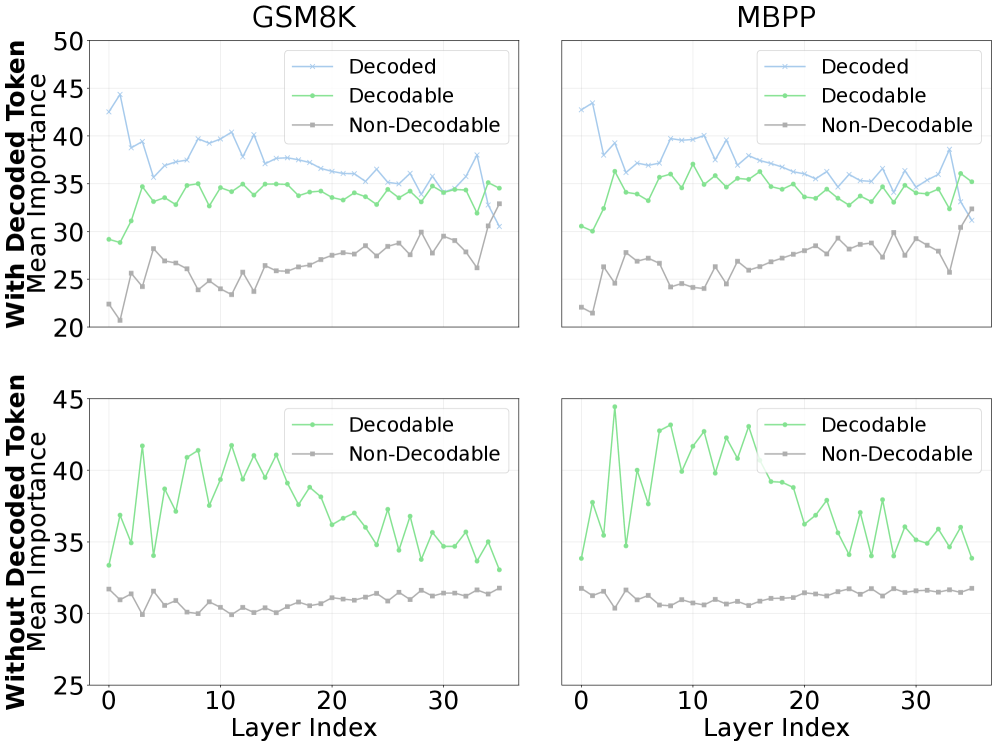
核心思路:论文的核心思路是动态地将计算资源集中在可解码的token上,并及时剔除不可解码的token。通过这种方式,可以有效地利用计算资源,提高有效批处理大小,从而提升整体的推理吞吐量。论文观察到token的重要性(由注意力机制决定)与token的可解码概率之间存在强相关性,为动态聚焦提供了依据。
技术框架:FOCUS推理系统主要包含以下几个阶段:1. Token重要性评估:利用注意力机制计算每个token的重要性得分。2. 可解码性预测:基于token重要性得分预测token的可解码概率。3. 动态计算分配:根据可解码概率,将计算资源优先分配给可解码的token。4. Token剔除:将可解码概率低的token从计算图中剔除,减少无效计算。5. 解码与生成:对剩余的可解码token进行解码,生成最终文本。
关键创新:FOCUS的关键创新在于其动态计算分配机制,它能够根据token的可解码概率自适应地调整计算资源的分配,避免了对所有token进行无差别计算的低效做法。与现有方法相比,FOCUS能够更有效地利用计算资源,从而显著提升推理吞吐量。
关键设计:FOCUS使用注意力得分作为token重要性的代理指标。可解码概率的预测可以通过一个轻量级的神经网络实现,该网络以token重要性得分作为输入,输出token的可解码概率。Token剔除的阈值可以根据实际的计算资源和性能要求进行调整。损失函数的设计需要考虑平衡生成质量和计算效率。
🖼️ 关键图片

📊 实验亮点
FOCUS在多个基准测试中实现了显著的吞吐量提升,最高可达3.52倍于生产级引擎LMDeploy。同时,FOCUS在提升吞吐量的同时,能够保持甚至提高生成质量。这些实验结果充分证明了FOCUS的有效性和优越性。
🎯 应用场景
FOCUS技术可应用于各种需要高性能DLLM推理的场景,例如:实时文本生成、对话系统、机器翻译等。通过降低DLLM的推理成本,可以促进其在资源受限环境中的部署,并加速相关应用的普及。该研究对于推动下一代语言模型的发展具有重要意义。
📄 摘要(原文)
Diffusion Large Language Models (DLLMs) offer a compelling alternative to Auto-Regressive models, but their deployment is constrained by high decoding cost. In this work, we identify a key inefficiency in DLLM decoding: while computation is parallelized over token blocks, only a small subset of tokens is decodable at each diffusion step, causing most compute to be wasted on non-decodable tokens. We further observe a strong correlation between attention-derived token importance and token-wise decoding probability. Based on this insight, we propose FOCUS -- an inference system designed for DLLMs. By dynamically focusing computation on decodable tokens and evicting non-decodable ones on-the-fly, FOCUS increases the effective batch size, alleviating compute limitations and enabling scalable throughput. Empirical evaluations demonstrate that FOCUS achieves up to 3.52$\times$ throughput improvement over the production-grade engine LMDeploy, while preserving or improving generation quality across multiple benchmarks. The FOCUS system is publicly available on GitHub: https://github.com/sands-lab/FOCUS.