TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
作者: Ruijie Zhang, Yequan Zhao, Ziyue Liu, Zhengyang Wang, Dongyang Li, Yupeng Su, Sijia Liu, Zheng Zhang
分类: cs.LG, cs.AI
发布日期: 2026-01-30
💡 一句话要点
TEON:面向大语言模型预训练的张量化正交归一化优化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 优化器 梯度正交化 张量分解
📋 核心要点
- 现有Muon优化器仅在模型每一层独立进行梯度正交化,忽略了层间依赖关系,限制了优化效果。
- TEON将神经网络梯度建模为高阶张量,实现跨层正交化,从而更全面地优化模型参数。
- 实验表明,TEON在不同规模的GPT和LLaMA模型上均能有效降低困惑度,提升模型性能。
📝 摘要(中文)
Muon优化器通过在每一层独立执行矩阵级梯度(或动量)正交化,已在大语言模型预训练中表现出强大的经验性能。本文提出了TEON,它是Muon的一个原则性泛化,通过将神经网络的梯度建模为结构化的高阶张量,将正交化扩展到单个层之外。我们展示了TEON相对于逐层Muon的改进的收敛保证,并基于理论分析开发了TEON的实用实例化以及相应的消融实验。我们在两种广泛采用的架构上评估了我们的方法:参数范围从1.3亿到7.74亿的GPT风格模型,以及参数范围从6000万到10亿的LLaMA风格模型。实验结果表明,TEON在各种模型规模上持续提高训练和验证困惑度,并在各种近似SVD方案下表现出强大的鲁棒性。
🔬 方法详解
问题定义:现有Muon优化器在预训练大型语言模型时,虽然通过矩阵级梯度正交化在每一层都取得了不错的性能,但其正交化过程仅限于单个层内,忽略了不同层之间的梯度依赖关系。这种层间孤立的正交化方式可能导致次优的优化结果,限制了模型的最终性能。因此,如何有效地利用层间梯度信息,实现更全局的正交化,是本文要解决的关键问题。
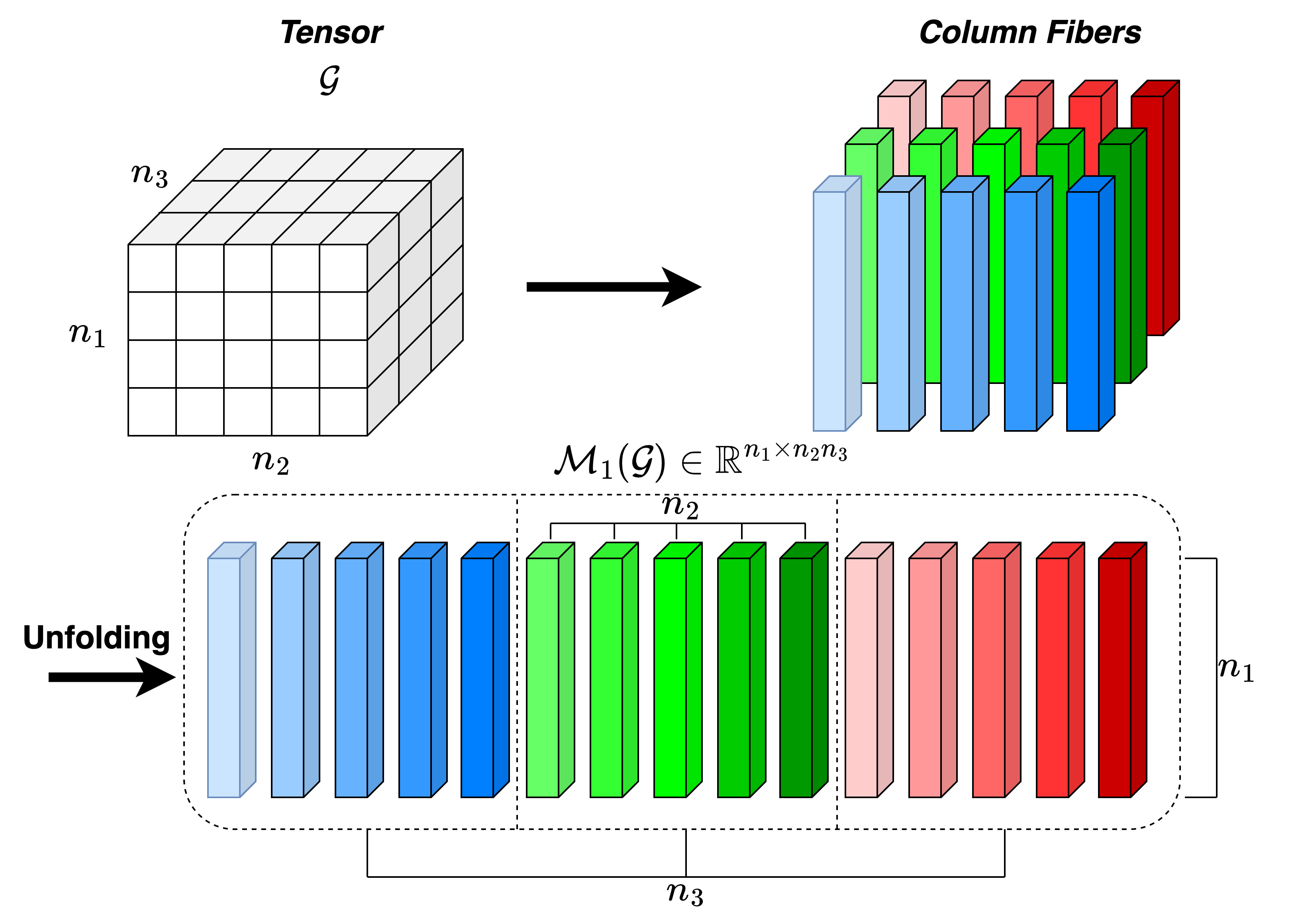
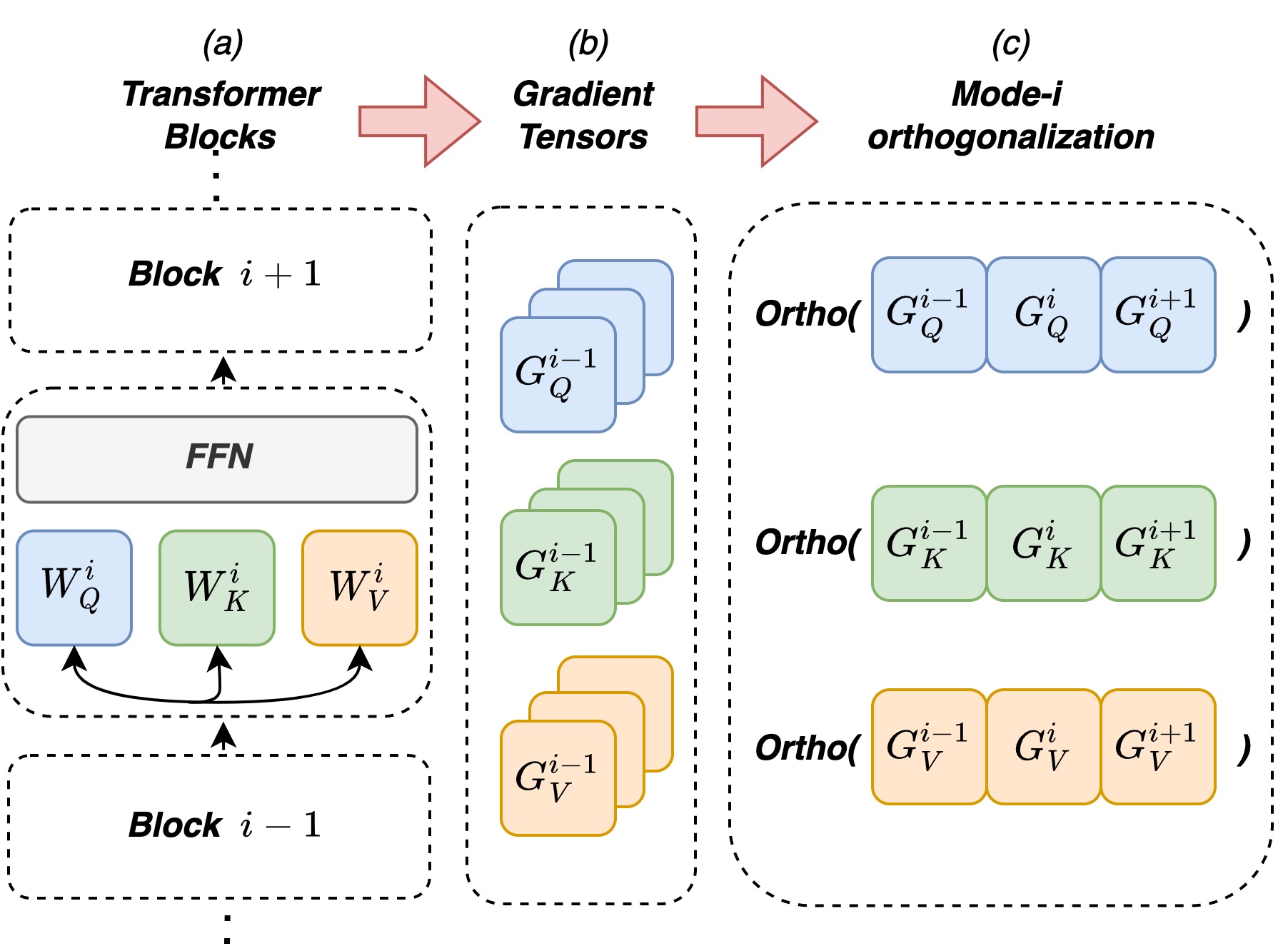
核心思路:TEON的核心思路是将神经网络的梯度视为一个结构化的高阶张量,从而能够对整个网络进行跨层的正交化。通过这种方式,TEON能够捕捉到不同层之间的梯度依赖关系,并利用这些信息来更有效地更新模型参数。这种全局的正交化方法能够避免层间孤立优化带来的问题,从而提高模型的训练效率和最终性能。
技术框架:TEON的技术框架主要包括以下几个步骤:1) 将神经网络的梯度表示为一个高阶张量。2) 对该张量进行张量分解,提取出主要的梯度方向。3) 对提取出的梯度方向进行正交化处理。4) 利用正交化后的梯度方向更新模型参数。整个过程旨在实现跨层的梯度正交化,从而提高模型的训练效率和性能。
关键创新:TEON最重要的技术创新点在于其将神经网络的梯度建模为高阶张量,并在此基础上进行跨层正交化。与传统的逐层正交化方法相比,TEON能够更好地捕捉到不同层之间的梯度依赖关系,从而实现更全局的优化。这种张量化的正交归一化方法是TEON的核心创新之处。
关键设计:TEON的关键设计包括:1) 如何有效地将神经网络的梯度表示为一个高阶张量。2) 如何选择合适的张量分解方法,以提取出主要的梯度方向。3) 如何对提取出的梯度方向进行正交化处理,以保证优化的稳定性。4) 如何将正交化后的梯度方向应用到模型参数的更新中。这些设计细节直接影响着TEON的性能和效率。
🖼️ 关键图片
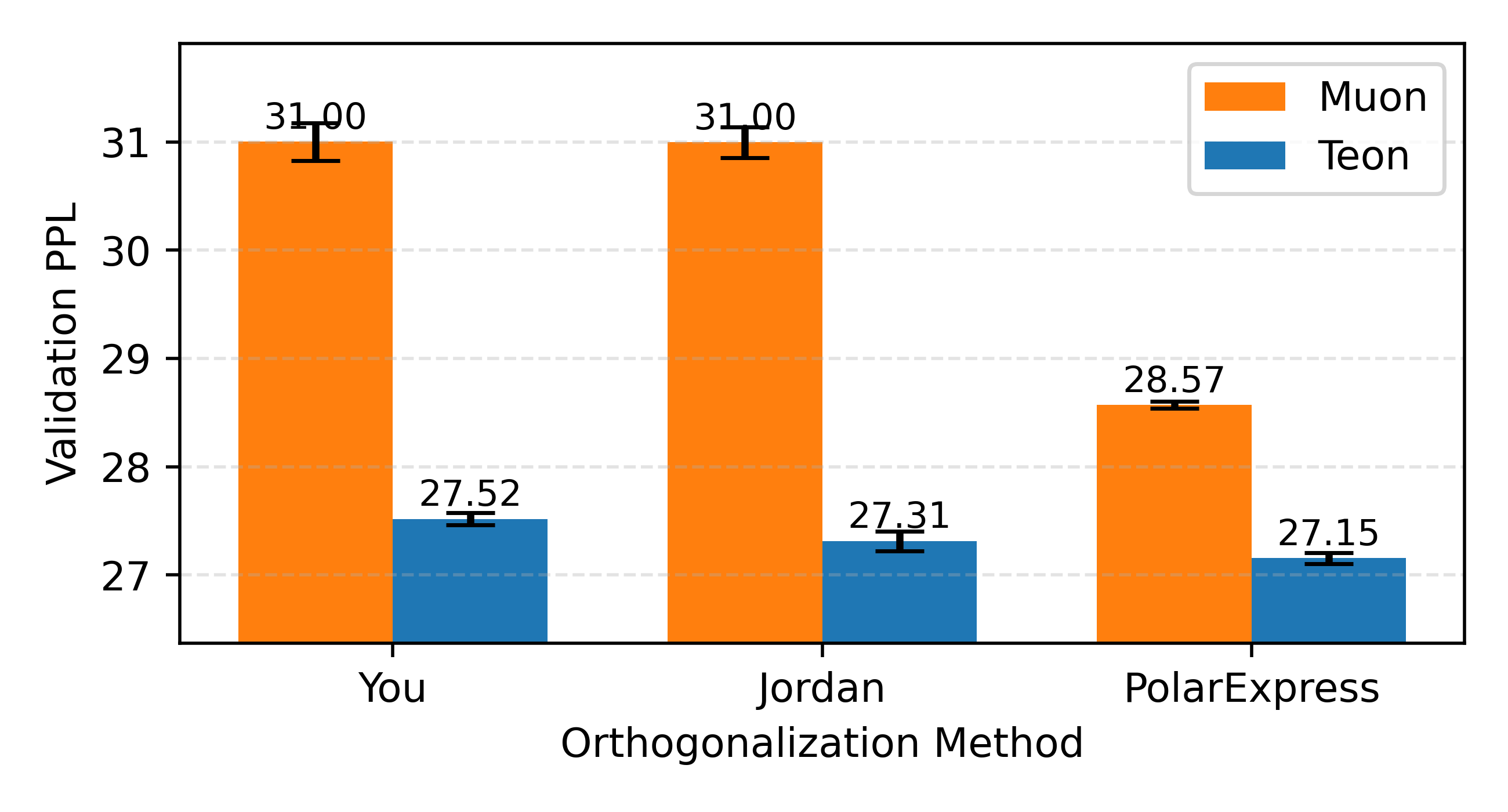
📊 实验亮点
实验结果表明,TEON在GPT风格(130M-774M参数)和LLaMA风格(60M-1B参数)的模型上均取得了显著的性能提升。例如,在相同训练条件下,TEON能够有效降低模型的困惑度,提高验证集的准确率。此外,TEON在不同的近似SVD方案下表现出良好的鲁棒性,证明了其在实际应用中的可靠性。
🎯 应用场景
TEON优化器可广泛应用于各种大语言模型的预训练任务中,尤其适用于需要大规模并行训练的场景。其通过跨层梯度正交化,能够提升模型训练效率和最终性能,降低训练成本。未来,TEON有望成为大模型训练的标准优化方法之一,加速人工智能领域的发展。
📄 摘要(原文)
The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.