Probing the Trajectories of Reasoning Traces in Large Language Models
作者: Marthe Ballon, Brecht Verbeken, Vincent Ginis, Andres Algaba
分类: cs.LG, cs.AI
发布日期: 2026-01-30
备注: 33 pages, 20 figures, 4 tables
💡 一句话要点
提出轨迹探测方法,分析大型语言模型推理过程中的决策演变与信息贡献。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理轨迹 可解释性 轨迹探测 决策演变
📋 核心要点
- 大型语言模型推理过程的透明度不足,难以理解其决策过程中的关键信息和演变。
- 提出一种轨迹探测协议,通过截断和注入部分推理轨迹,分析模型在不同阶段的决策分布。
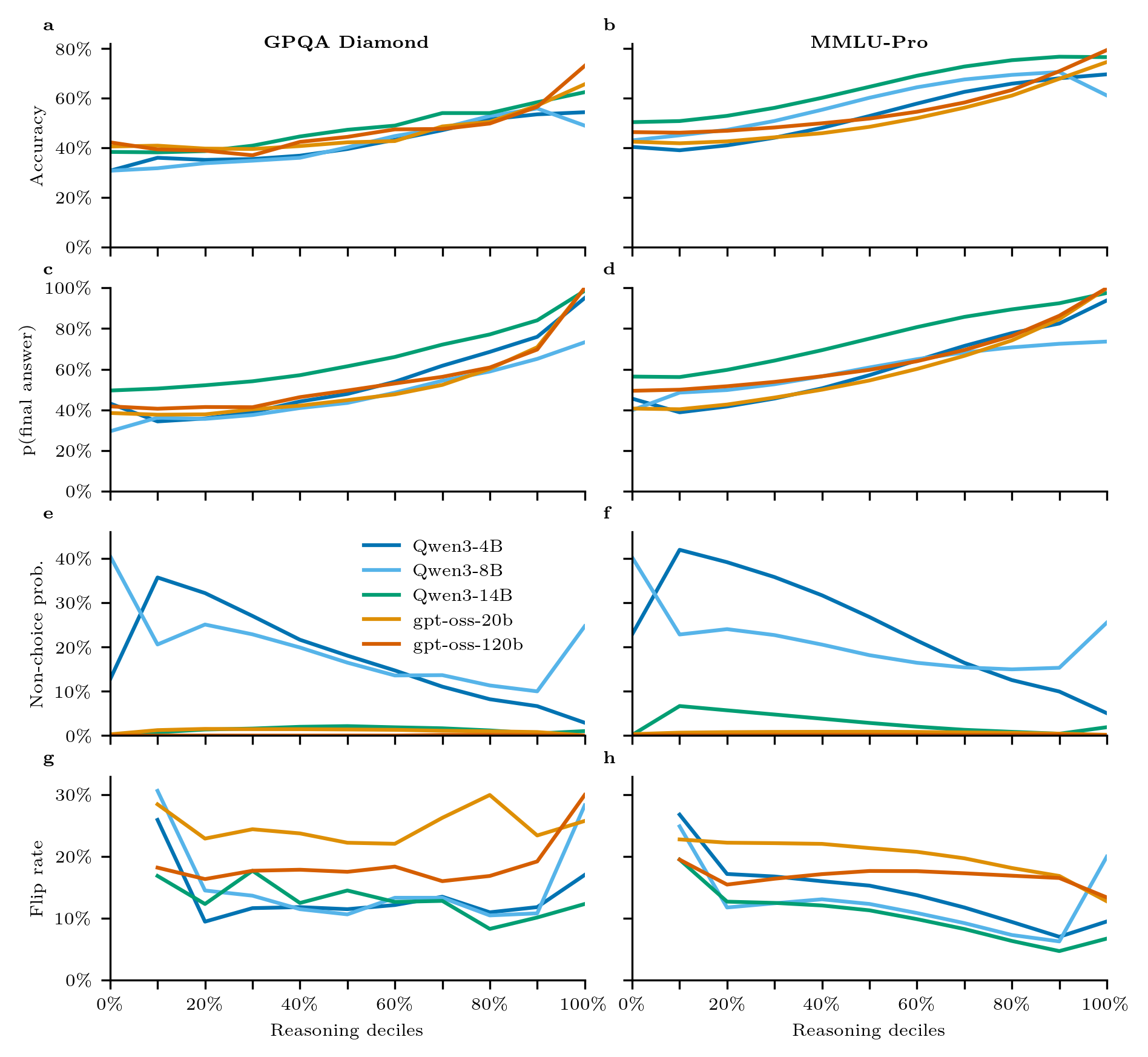
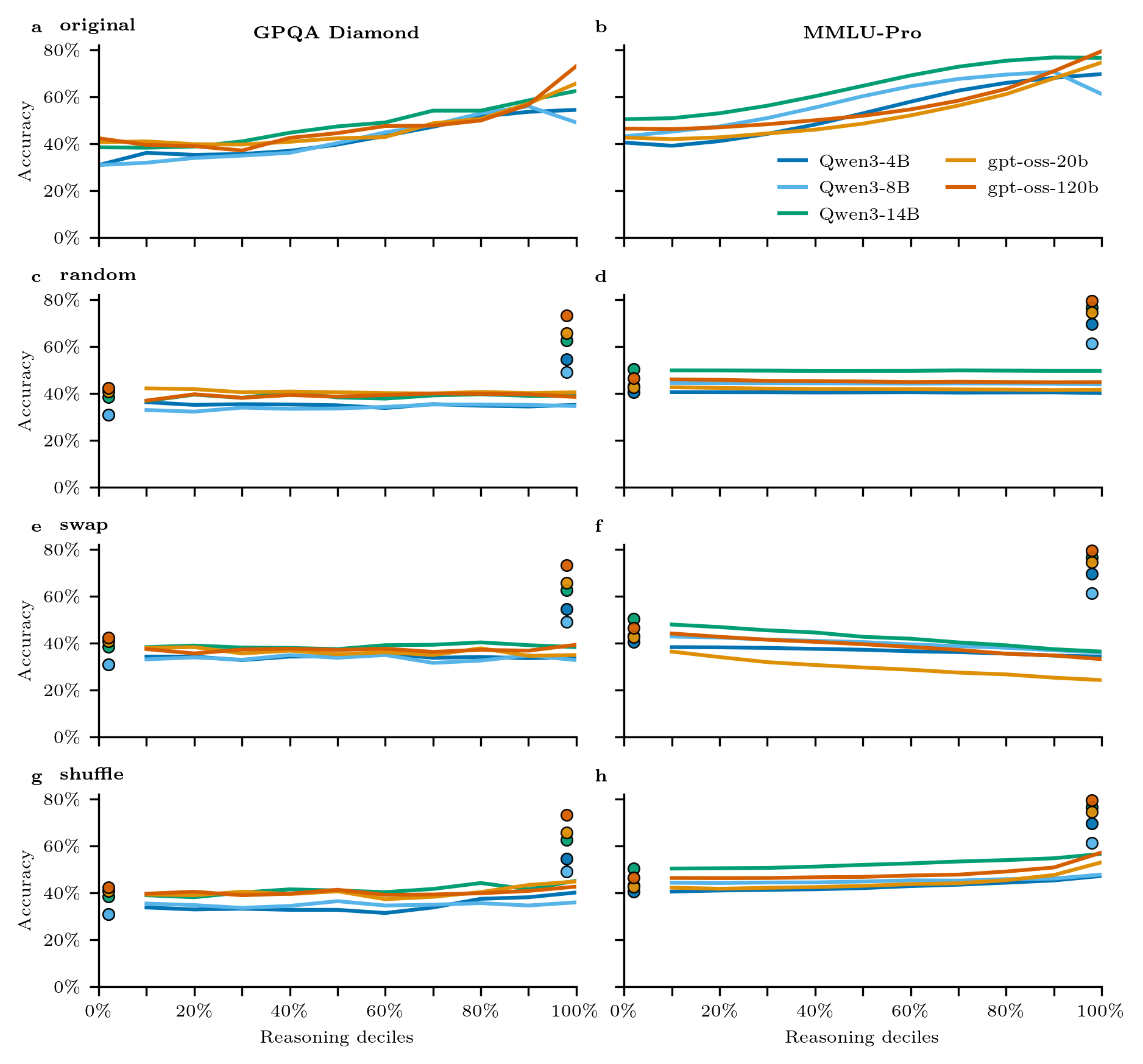
- 实验表明,模型准确性和决策承诺随推理token增长而提高,且内容相关性是主要驱动因素。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地通过生成“推理轨迹”来解决难题,然后再给出最终答案。然而,准确性和决策承诺如何沿着推理轨迹演变,以及中间轨迹段是否提供超出通用长度或风格效果的答案相关信息,仍然不清楚。本文提出了一种协议,通过以下步骤系统地探测LLM中推理轨迹:1)生成模型的推理轨迹;2)在固定的token百分位数截断轨迹;3)将每个部分轨迹注入回模型(或不同的模型),以通过下一个token概率测量答案选择上的诱导分布。我们将此协议应用于开源的Qwen3-4B/-8B/-14B和gpt-oss-20b/-120b模型,跨越多个选择题GPQA Diamond和MMLU-Pro基准。我们发现,随着提供的推理token百分比的增长,准确性和决策承诺持续增加。这些收益主要由模型生成中的相关内容驱动,而不是上下文长度或通用的“推理风格”效果。更强的模型通常可以成功地从不正确的部分轨迹中回溯,但立即的答案通常仍然锚定在较弱模型的不正确响应中。更广泛地说,我们表明轨迹探测为推理模型的有效和更安全的部署提供了诊断,因为这些测量可以为实用的轨迹处理和监控策略提供信息,从而提高可靠性,而无需假设中间token本质上是忠实的解释。
🔬 方法详解
问题定义:现有大型语言模型在解决复杂问题时,通常会生成推理轨迹。然而,我们对这些推理轨迹的理解仍然有限,例如,准确性和决策的确定性是如何随着推理过程演变的?中间步骤是否包含了超出长度和风格之外的、与最终答案相关的信息?现有方法缺乏对推理过程的细粒度分析能力。
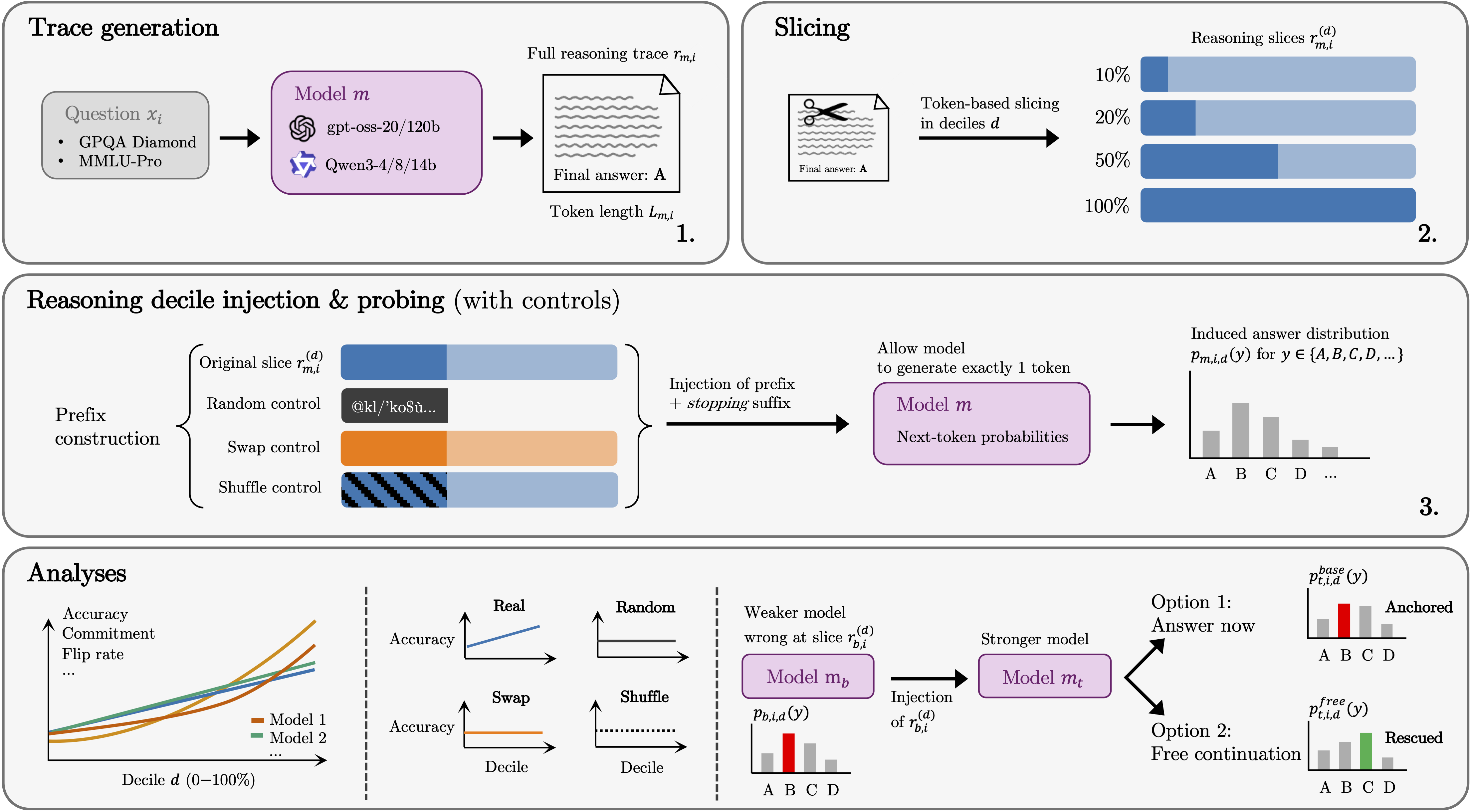
核心思路:本文的核心思路是通过系统性地探测推理轨迹,来理解模型在推理过程中的决策演变。具体来说,通过截断推理轨迹的不同部分,并将这些部分轨迹重新输入模型,观察模型对答案选择的影响,从而推断出不同阶段的推理内容对最终决策的贡献。
技术框架:该方法包含三个主要步骤:1)生成推理轨迹:首先,让模型生成完整的推理轨迹。2)轨迹截断:然后,在不同的token百分位数处截断推理轨迹,得到一系列部分轨迹。3)轨迹注入与概率测量:最后,将每个部分轨迹作为上下文重新输入模型,并测量模型在答案选择上的概率分布。通过比较不同截断点的概率分布,可以分析推理轨迹中不同部分对最终决策的影响。
关键创新:该方法的主要创新在于提出了一种系统性的轨迹探测协议,可以细粒度地分析大型语言模型推理过程中的决策演变。与以往的研究不同,该方法不仅关注最终的答案,更关注推理过程中的中间步骤,从而可以更深入地理解模型的推理机制。此外,该方法可以应用于不同的模型和数据集,具有较强的通用性。
关键设计:在轨迹截断阶段,选择固定的token百分位数作为截断点,例如20%、40%、60%等。在概率测量阶段,使用模型的下一个token预测概率来评估模型对不同答案选择的偏好。实验中使用了Qwen3-4B/-8B/-14B和gpt-oss-20b/-120b等多个模型,以及GPQA Diamond和MMLU-Pro等多个数据集。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随着推理token百分比的增加,模型的准确性和决策承诺持续提高。更强的模型能够从不正确的部分轨迹中成功回溯,但较弱模型的早期错误会影响后续决策。该研究强调了推理轨迹中相关内容的重要性,而非仅仅是上下文长度或推理风格。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和安全性。通过轨迹探测,可以更好地理解模型的推理过程,从而设计更有效的轨迹处理和监控策略。例如,可以识别推理过程中的错误或偏差,并及时进行干预,从而提高模型的准确性和鲁棒性。此外,该方法还可以用于评估不同模型的推理能力,为模型选择和部署提供参考。
📄 摘要(原文)
Large language models (LLMs) increasingly solve difficult problems by producing "reasoning traces" before emitting a final response. However, it remains unclear how accuracy and decision commitment evolve along a reasoning trajectory, and whether intermediate trace segments provide answer-relevant information beyond generic length or stylistic effects. Here, we propose a protocol to systematically probe the trajectories of reasoning traces in LLMs by 1) generating a model's reasoning trace, 2) truncating it at fixed token-percentiles, and 3) injecting each partial trace back into the model (or a different model) to measure the induced distribution over answer choices via next-token probabilities. We apply this protocol to the open-source Qwen3-4B/-8B/-14B and gpt-oss-20b/-120b models across the multiple-choice GPQA Diamond and MMLU-Pro benchmarks. We find that accuracy and decision commitment consistently increase as the percentage of provided reasoning tokens grows. These gains are primarily driven by relevant content in the model generation rather than context length or generic "reasoning style" effects. Stronger models often backtrack successfully from incorrect partial traces, but immediate answers often remain anchored in the weaker model's incorrect response. More broadly, we show that trajectory probing provides diagnostics for efficient and safer deployment of reasoning models as the measurements can inform practical trace-handling and monitoring policies that improve reliability without assuming intermediate tokens are inherently faithful explanations.