On Safer Reinforcement Learning Policies for Sedation and Analgesia in Intensive Care
作者: Joel Romero-Hernandez, Oscar Camara
分类: cs.LG, cs.AI
发布日期: 2026-01-30
备注: Submitted to the 48th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (IEEE EMBC 2026)
💡 一句话要点
提出兼顾镇静镇痛与患者生存的强化学习策略,提升ICU用药安全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 镇静镇痛 重症监护 患者安全 药物剂量
📋 核心要点
- ICU镇静镇痛治疗需要在疗效与患者安全间权衡,现有强化学习方法忽略了长期生存目标。
- 本文提出一种深度强化学习框架,同时优化镇静镇痛效果和患者生存率,提升用药安全性。
- 实验表明,兼顾长期生存目标的策略能有效降低死亡率,验证了该方法的有效性。
📝 摘要(中文)
重症监护中的疼痛管理需要在治疗目标和患者安全之间进行权衡,因为治疗不足或过度都可能导致严重的后遗症。强化学习可以通过从历史数据中学习药物剂量策略来应对这一挑战。然而,以往关于镇静和镇痛的研究通常优化不重视患者生存的目标,并且依赖于不适合不完全信息环境的算法。本文通过实现一个深度强化学习框架,在部分可观察的情况下建议每小时的药物剂量,从而研究了这些设计选择的风险。使用MIMIC-IV数据库中47144个ICU住院数据,我们训练了策略来根据两个目标开具阿片类药物、丙泊酚、苯二氮卓类药物和右美托咪定:减轻疼痛或共同减轻疼痛和死亡率。结果表明,虽然这两种策略都与较低的疼痛相关,但第一种策略的行为与死亡率呈正相关,而第二种策略的行为与死亡率呈负相关。这表明,即使短期目标仍然是主要目标,重视长期结果对于更安全的治疗策略至关重要。
🔬 方法详解
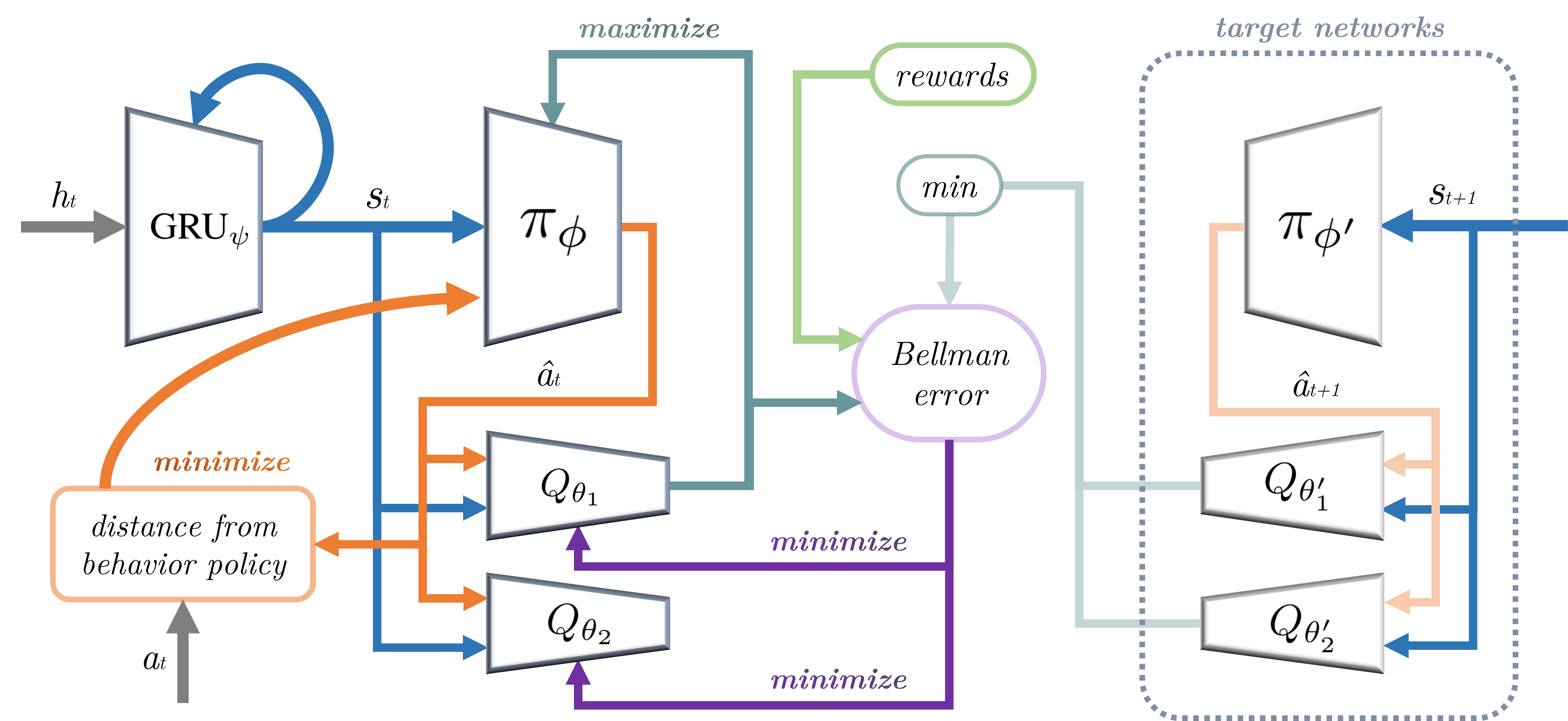
问题定义:现有ICU镇静镇痛的强化学习方法主要关注短期的疼痛缓解,忽略了药物剂量对患者长期生存的影响。此外,ICU环境具有不完全可观测性,现有算法难以有效应对,导致用药策略可能增加患者死亡风险。
核心思路:本文的核心思路是在强化学习的目标函数中同时考虑镇静镇痛效果和患者生存率,通过优化长期回报来学习更安全的用药策略。通过这种方式,模型能够权衡短期的疼痛缓解和长期的生存概率,从而避免过度用药或用药不足。
技术框架:本文采用深度强化学习框架,使用MIMIC-IV数据库中的ICU患者数据进行训练。该框架包括以下主要模块:1) 状态表示:将患者的生理指标、用药历史等信息编码为状态向量。2) 动作空间:定义可选择的药物剂量,包括阿片类药物、丙泊酚、苯二氮卓类药物和右美托咪定。3) 奖励函数:设计奖励函数,同时考虑镇静镇痛效果(例如,疼痛评分的降低)和患者生存率(例如,生存时间)。4) 深度强化学习算法:使用深度强化学习算法(具体算法未知)训练策略网络,该网络根据当前状态输出最佳的药物剂量。
关键创新:本文的关键创新在于将患者生存率纳入强化学习的目标函数中,从而学习更安全的用药策略。与以往只关注短期疼痛缓解的方法相比,本文的方法能够更好地权衡短期疗效和长期生存,降低患者死亡风险。
关键设计:奖励函数的设计是关键。奖励函数需要平衡镇静镇痛效果和患者生存率之间的权重。具体参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与只关注疼痛缓解的策略相比,同时优化疼痛缓解和患者生存率的策略能够显著降低患者死亡率。具体而言,只关注疼痛缓解的策略与死亡率呈正相关,而同时优化疼痛缓解和患者生存率的策略与死亡率呈负相关。这表明,在ICU镇静镇痛治疗中,重视长期生存目标至关重要。
🎯 应用场景
该研究成果可应用于开发智能化的ICU用药决策支持系统,辅助医生制定更安全有效的镇静镇痛方案。通过结合患者的实时生理数据和历史数据,该系统可以为医生提供个性化的用药建议,降低用药风险,提高患者生存率。未来,该方法还可以扩展到其他需要权衡短期疗效和长期风险的医疗决策场景。
📄 摘要(原文)
Pain management in intensive care usually involves complex trade-offs between therapeutic goals and patient safety, since both inadequate and excessive treatment may induce serious sequelae. Reinforcement learning can help address this challenge by learning medication dosing policies from retrospective data. However, prior work on sedation and analgesia has optimized for objectives that do not value patient survival while relying on algorithms unsuitable for imperfect information settings. We investigated the risks of these design choices by implementing a deep reinforcement learning framework to suggest hourly medication doses under partial observability. Using data from 47,144 ICU stays in the MIMIC-IV database, we trained policies to prescribe opioids, propofol, benzodiazepines, and dexmedetomidine according to two goals: reduce pain or jointly reduce pain and mortality. We found that, although the two policies were associated with lower pain, actions from the first policy were positively correlated with mortality, while those proposed by the second policy were negatively correlated. This suggests that valuing long-term outcomes could be critical for safer treatment policies, even if a short-term goal remains the primary objective.