Behemoth: Benchmarking Unlearning in LLMs Using Fully Synthetic Data
作者: Eugenia Iofinova, Dan Alistarh
分类: cs.LG
发布日期: 2026-01-30
🔗 代码/项目: GITHUB
💡 一句话要点
Behemoth:利用全合成数据基准测试LLM中的模型遗忘能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型编辑 模型遗忘 合成数据 基准测试
📋 核心要点
- 现有模型编辑方法缺乏对训练数据分布与模型存储方式之间关系的深入理解,导致编辑效果不稳定且难以评估。
- Behemoth框架通过生成完全合成的数据,提供了一个可控的环境,用于研究和理解模型编辑与训练数据之间的复杂关系。
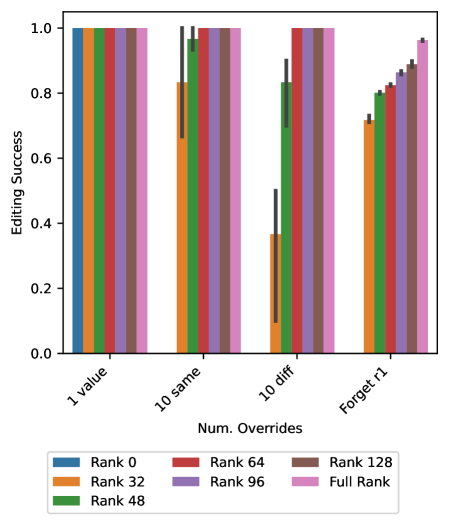
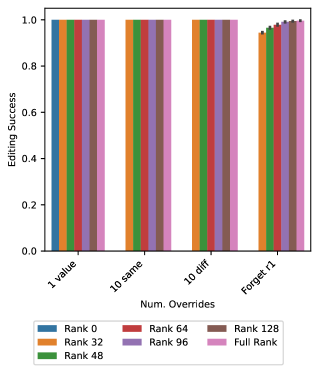
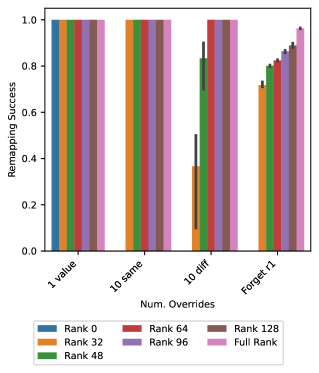
- 实验表明,在合成数据上进行模型编辑研究可以揭示与真实世界结果相符的现象,例如限制更新秩可以提高编辑效果。
📝 摘要(中文)
随着人工神经网络,特别是大型语言模型在能力和质量上的快速提升,它们越来越多地被部署在现实世界的应用中,从客户服务到谷歌搜索,尽管它们经常做出在事实上不正确或不希望出现的陈述。 这种趋势激发了人们对模型编辑的实践和学术兴趣,即调整模型的权重以修改其对于与特定事实或一组事实相关的查询的可能输出。 这可以通过修正一个事实或一组事实来完成,例如,修复训练数据中的常见错误,或者完全抑制一个事实或一组事实,例如,在存在危险知识的情况下。 已经提出了多种方法来进行这种编辑。 然而,与此同时,已经表明这种模型编辑可能是脆弱和不完整的。 此外,任何模型编辑方法的有效性必然取决于模型训练的数据,因此,充分理解训练数据分布及其在网络中的存储方式之间的相互作用对于可靠地执行模型编辑是必要且有帮助的。 然而,使用在真实世界数据上训练的大型语言模型不允许我们理解这种关系或充分衡量模型编辑的效果。 因此,我们提出了Behemoth,一个完全合成的数据生成框架。 为了展示该框架的实际见解,我们探索了简单表格数据中的模型编辑,展示了令人惊讶的发现,在某些情况下,这些发现与真实世界的结果相呼应,例如,在某些情况下,限制更新秩会导致更有效的更新。 代码可在https://github.com/IST-DASLab/behemoth.git获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中模型编辑效果评估的问题。现有方法依赖于真实世界数据,这使得理解训练数据分布与模型内部知识存储方式之间的关系变得困难,进而影响了模型编辑的可靠性和可控性。现有模型编辑方法的痛点在于缺乏可控的实验环境,难以系统性地研究不同因素对编辑效果的影响。
核心思路:论文的核心思路是构建一个完全合成的数据生成框架Behemoth,通过控制数据的生成过程,可以精确地研究训练数据分布对模型编辑的影响。这种方法允许研究人员在可控的环境中探索模型编辑的机制,并更好地理解模型内部知识的存储方式。
技术框架:Behemoth框架的核心是合成数据生成器,它可以生成具有特定属性的表格数据。研究人员可以控制数据的规模、分布和噪声水平等参数。然后,使用这些合成数据训练LLM,并应用不同的模型编辑方法。最后,通过评估编辑后的模型在特定任务上的性能,来衡量编辑效果。整个流程包括数据生成、模型训练、模型编辑和效果评估四个主要阶段。
关键创新:该论文最重要的技术创新点在于提出了一个完全合成的数据生成框架,用于研究LLM中的模型编辑。与使用真实世界数据相比,合成数据提供了更高的可控性和可解释性,使得研究人员可以更深入地理解模型编辑的机制。这种方法为模型编辑的研究提供了一个新的视角和工具。
关键设计:Behemoth框架的关键设计包括:1) 合成数据生成器的参数化设计,允许控制数据的各种属性;2) 模型编辑方法的选择,可以灵活地应用不同的编辑算法;3) 效果评估指标的设计,用于衡量编辑后的模型在特定任务上的性能。此外,论文还探讨了限制更新秩对编辑效果的影响,发现适当的秩约束可以提高编辑效果。
🖼️ 关键图片
📊 实验亮点
该研究通过Behemoth框架,在合成表格数据上进行了模型编辑实验,发现限制更新秩在某些情况下可以提高编辑效果,这与真实世界的结果相呼应。这一发现表明,即使在简单的合成数据上进行研究,也能为理解复杂LLM的编辑机制提供有价值的见解。
🎯 应用场景
该研究成果可应用于提升LLM的可控性和安全性。通过理解训练数据与模型知识存储的关系,可以更有效地进行模型编辑,修复错误知识、抑制有害信息,并提高模型在特定领域的性能。该框架还可用于评估不同模型编辑方法的有效性,指导模型编辑算法的设计和优化。
📄 摘要(原文)
As artificial neural networks, and specifically large language models, have improved rapidly in capabilities and quality, they have increasingly been deployed in real-world applications, from customer service to Google search, despite the fact that they frequently make factually incorrect or undesirable statements. This trend has inspired practical and academic interest in model editing, that is, in adjusting the weights of the model to modify its likely outputs for queries relating to a specific fact or set of facts. This may be done either to amend a fact or set of facts, for instance, to fix a frequent error in the training data, or to suppress a fact or set of facts entirely, for instance, in case of dangerous knowledge. Multiple methods have been proposed to do such edits. However, at the same time, it has been shown that such model editing can be brittle and incomplete. Moreover the effectiveness of any model editing method necessarily depends on the data on which the model is trained, and, therefore, a good understanding of the interaction of the training data distribution and the way it is stored in the network is necessary and helpful to reliably perform model editing. However, working with large language models trained on real-world data does not allow us to understand this relationship or fully measure the effects of model editing. We therefore propose Behemoth, a fully synthetic data generation framework. To demonstrate the practical insights from the framework, we explore model editing in the context of simple tabular data, demonstrating surprising findings that, in some cases, echo real-world results, for instance, that in some cases restricting the update rank results in a more effective update. The code is available at https://github.com/IST-DASLab/behemoth.git.