AscendCraft: Automatic Ascend NPU Kernel Generation via DSL-Guided Transcompilation
作者: Zhongzhen Wen, Shudi Shao, Zhong Li, Yu Ge, Tongtong Xu, Yuanyi Lin, Tian Zhang
分类: cs.DC, cs.LG, cs.PF, cs.SE
发布日期: 2026-01-30
💡 一句话要点
AscendCraft:通过DSL引导的转译自动生成昇腾NPU内核
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 昇腾NPU 内核生成 领域特定语言 自动代码生成 深度学习加速
📋 核心要点
- 为NPU生成高性能内核面临领域编程模型复杂、示例少、文档不足等挑战,直接使用LLM生成AscendC内核正确率极低。
- AscendCraft提出一种DSL引导的自动内核生成方法,通过轻量级DSL抽象复杂性,并显式建模Ascend执行语义。
- 实验表明,AscendCraft在编译成功率、功能正确性以及性能上均表现出色,甚至超越PyTorch eager执行。
📝 摘要(中文)
深度学习模型的性能关键依赖于高效的内核实现,但为专用加速器开发高性能内核仍然耗时且需要专业知识。虽然最近的研究表明,大型语言模型(LLM)可以生成正确且高性能的GPU内核,但由于特定领域的编程模型、有限的公开示例和稀疏的文档,用于神经处理单元(NPU)的内核生成在很大程度上仍未被探索。因此,直接使用LLM生成AscendC内核的正确率极低,突出了GPU和NPU内核生成之间的巨大差距。我们提出了AscendCraft,一种DSL引导的自动AscendC内核生成方法。AscendCraft引入了一种轻量级DSL,它抽象了非必要的复杂性,同时显式地建模了Ascend特定的执行语义。首先使用特定类别的专家示例在DSL中生成内核,然后通过结构化的、约束驱动的LLM降级过程将其转译为AscendC。在MultiKernelBench上对七个算子类别进行评估,AscendCraft实现了98.1%的编译成功率和90.4%的功能正确性。此外,46.2%生成的内核匹配或超过了PyTorch eager执行的性能,表明DSL引导的转译可以使LLM生成正确且具有竞争力的NPU内核。除了基准测试之外,AscendCraft还通过为新提出的mHC架构成功生成两个正确的内核来进一步证明其通用性,实现了大大超过PyTorch eager执行的性能。
🔬 方法详解
问题定义:论文旨在解决为昇腾NPU自动生成高性能内核的问题。现有方法,特别是直接使用LLM生成AscendC内核,由于NPU编程模型的特殊性、公开示例的缺乏以及文档的稀疏性,导致生成的内核正确率极低,难以满足实际需求。
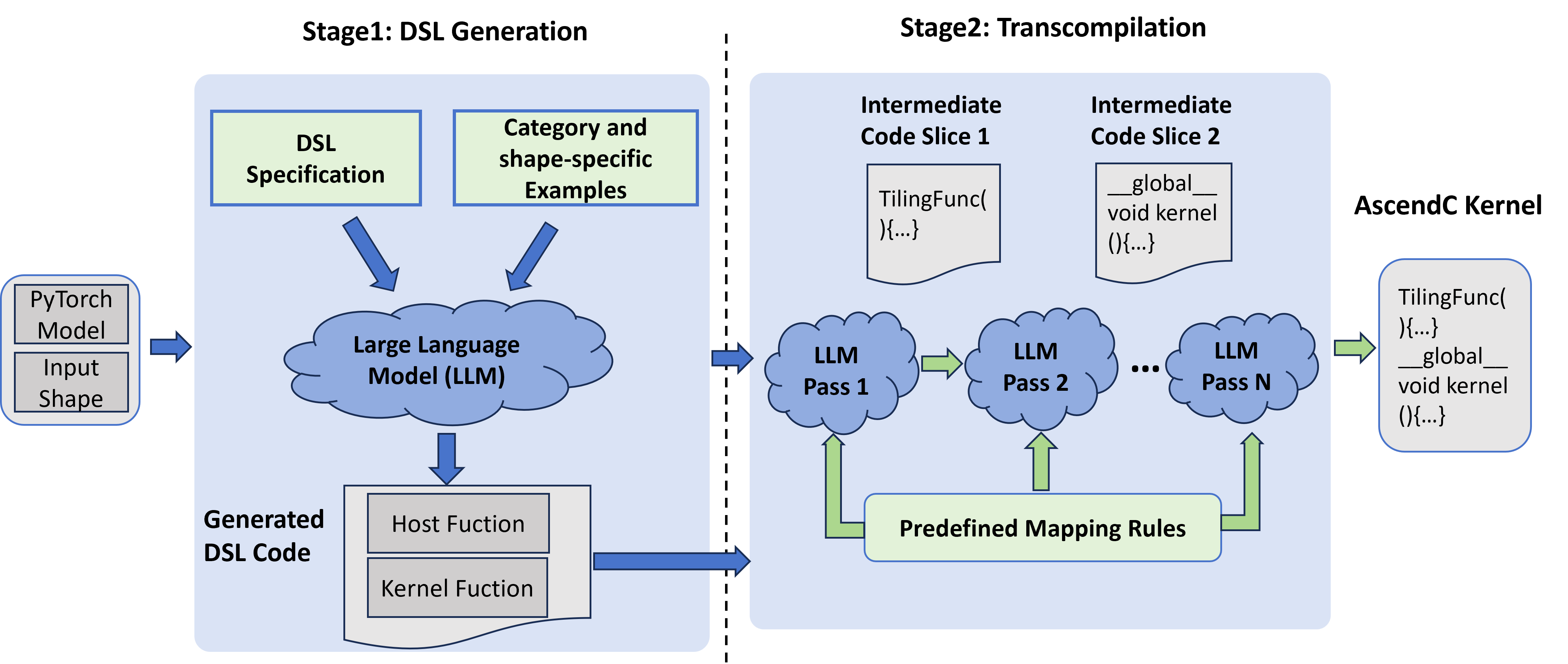
核心思路:论文的核心思路是引入一个轻量级的领域特定语言(DSL),该DSL能够抽象掉不必要的复杂性,同时显式地建模昇腾NPU特定的执行语义。通过DSL作为中间表示,降低了LLM直接生成AscendC代码的难度,并提高了生成内核的正确性和性能。
技术框架:AscendCraft的整体框架包含两个主要阶段:首先,使用特定类别的专家示例,利用LLM在DSL中生成内核;然后,通过结构化的、约束驱动的LLM降级过程,将DSL代码转译为AscendC代码。这个转译过程包含多个pass,每个pass负责将DSL中的特定结构转换为对应的AscendC代码。
关键创新:AscendCraft的关键创新在于DSL的设计和DSL引导的转译过程。DSL的设计使得LLM更容易理解和生成NPU内核的逻辑,而转译过程则利用LLM的代码生成能力,将DSL代码转换为高效的AscendC代码。这种DSL引导的转译方法显著提高了NPU内核生成的正确性和性能。
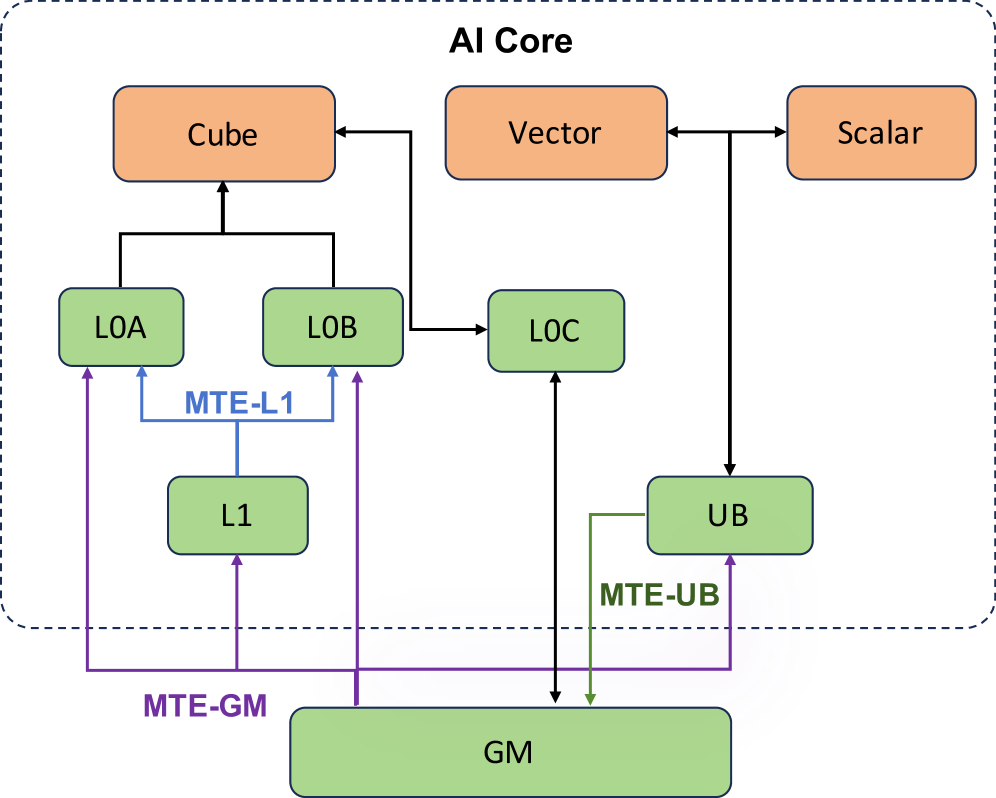
关键设计:DSL的设计需要仔细考虑昇腾NPU的硬件特性和编程模型,例如,需要支持NPU的张量计算、数据搬运等操作。转译过程中的约束条件也需要精心设计,以确保生成的AscendC代码满足NPU的硬件约束和性能要求。此外,论文还使用了特定类别的专家示例来指导LLM生成DSL代码,从而提高了生成内核的质量。
🖼️ 关键图片

📊 实验亮点
AscendCraft在MultiKernelBench的七个算子类别上实现了98.1%的编译成功率和90.4%的功能正确性。更重要的是,46.2%生成的内核匹配或超过了PyTorch eager执行的性能。此外,AscendCraft还成功为新提出的mHC架构生成了两个正确的内核,性能显著优于PyTorch eager执行,验证了其通用性。
🎯 应用场景
AscendCraft可应用于加速深度学习模型在昇腾NPU上的部署和优化。通过自动生成高性能内核,可以降低开发成本,缩短开发周期,并提升模型在NPU上的推理和训练性能。该研究对于推动国产AI芯片的生态建设具有重要意义,并有望加速AI技术在各行业的落地应用。
📄 摘要(原文)
The performance of deep learning models critically depends on efficient kernel implementations, yet developing high-performance kernels for specialized accelerators remains time-consuming and expertise-intensive. While recent work demonstrates that large language models (LLMs) can generate correct and performant GPU kernels, kernel generation for neural processing units (NPUs) remains largely underexplored due to domain-specific programming models, limited public examples, and sparse documentation. Consequently, directly generating AscendC kernels with LLMs yields extremely low correctness, highlighting a substantial gap between GPU and NPU kernel generation. We present AscendCraft, a DSL-guided approach for automatic AscendC kernel generation. AscendCraft introduces a lightweight DSL that abstracts non-essential complexity while explicitly modeling Ascend-specific execution semantics. Kernels are first generated in the DSL using category-specific expert examples and then transcompiled into AscendC through structured, constraint-driven LLM lowering passes. Evaluated on MultiKernelBench across seven operator categories, AscendCraft achieves 98.1% compilation success and 90.4% functional correctness. Moreover, 46.2% of generated kernels match or exceed PyTorch eager execution performance, demonstrating that DSL-guided transcompilation can enable LLMs to generate both correct and competitive NPU kernels. Beyond benchmarks, AscendCraft further demonstrates its generality by successfully generating two correct kernels for newly proposed mHC architecture, achieving performance that substantially surpasses PyTorch eager execution.