Pushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
作者: Chuxue Cao, Jinluan Yang, Haoran Li, Kunhao Pan, Zijian Zhao, Zhengyu Chen, Yuchen Tian, Lijun Wu, Conghui He, Sirui Han, Yike Guo
分类: cs.LG
发布日期: 2026-01-30
💡 一句话要点
提出形式逻辑验证引导的框架,提升LLM在自然推理任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 形式逻辑验证 神经符号推理 自然推理 监督微调
📋 核心要点
- 现有LLM在推理过程中存在逻辑不一致和奖励利用问题,缺乏形式符号系统的严谨性。
- 提出一种形式逻辑验证引导的框架,在生成过程中实时检测和纠正错误,主动惩罚中间谬误。
- 实验结果表明,该方法在多个推理基准上显著优于现有技术,验证了形式验证的有效性。
📝 摘要(中文)
大型语言模型(LLMs)展现了卓越的能力,但其随机的token预测导致了逻辑不一致和奖励利用等问题,而形式符号系统可以避免这些问题。为了弥合这一差距,我们引入了一种形式逻辑验证引导的框架,该框架将形式符号验证与自然语言生成过程动态地交织在一起,提供实时的反馈来检测和纠正错误。与以往受限于被动后验验证的神经符号方法不同,我们的方法在推理链中主动惩罚中间谬误。我们通过一种新颖的两阶段训练流程来实现这个框架,该流程协同了形式逻辑验证引导的监督微调和策略优化。在涵盖数学、逻辑和一般推理的六个基准上的广泛评估表明,我们的7B和14B模型分别以平均10.4%和14.2%的优势优于最先进的基线。这些结果验证了形式验证可以作为一种可扩展的机制,显著地推动先进LLM推理的性能边界。
🔬 方法详解
问题定义:大型语言模型在自然推理任务中表现出潜力,但由于其基于概率的生成方式,容易产生逻辑错误和不一致性,导致推理结果不可靠。现有神经符号方法通常采用后验验证,无法在推理过程中及时纠正错误,效率较低。
核心思路:论文的核心思路是将形式逻辑验证与自然语言生成过程紧密结合,通过形式逻辑验证模块对LLM的中间推理步骤进行实时评估和反馈,从而引导LLM生成更符合逻辑的推理路径。这种主动干预的方式能够有效避免谬误的产生,提高推理的准确性和可靠性。
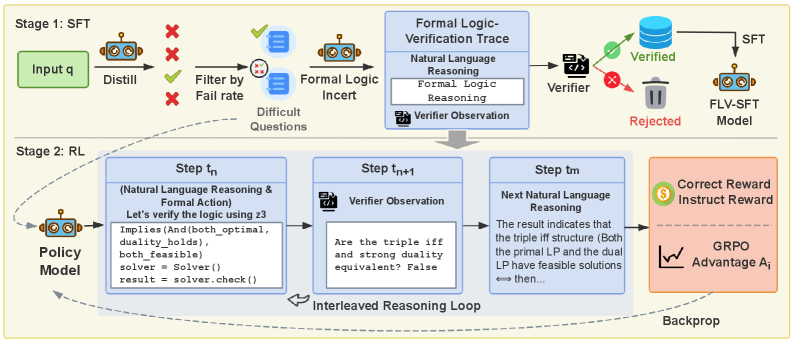
技术框架:该框架采用两阶段训练流程。第一阶段是形式逻辑验证引导的监督微调(SFT),利用形式逻辑验证模块生成的反馈信号,对LLM进行微调,使其初步具备逻辑推理能力。第二阶段是策略优化(Policy Optimization),通过强化学习的方式,进一步优化LLM的推理策略,使其能够更好地利用形式逻辑验证的反馈,生成更准确的推理结果。整体框架包含LLM、形式逻辑验证模块和反馈机制。
关键创新:该方法最重要的创新点在于将形式逻辑验证融入到LLM的推理过程中,实现了实时错误检测和纠正。与传统的后验验证方法相比,该方法能够更有效地避免谬误的产生,提高推理的准确性和可靠性。此外,两阶段训练流程的设计也保证了模型能够充分利用形式逻辑验证的反馈信号。
关键设计:形式逻辑验证模块的具体实现方式取决于具体的推理任务。例如,在数学推理任务中,可以使用符号计算引擎来验证数学公式的正确性。反馈机制的设计也至关重要,需要根据不同的错误类型,设计不同的惩罚策略,以引导LLM生成更符合逻辑的推理路径。具体的损失函数和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

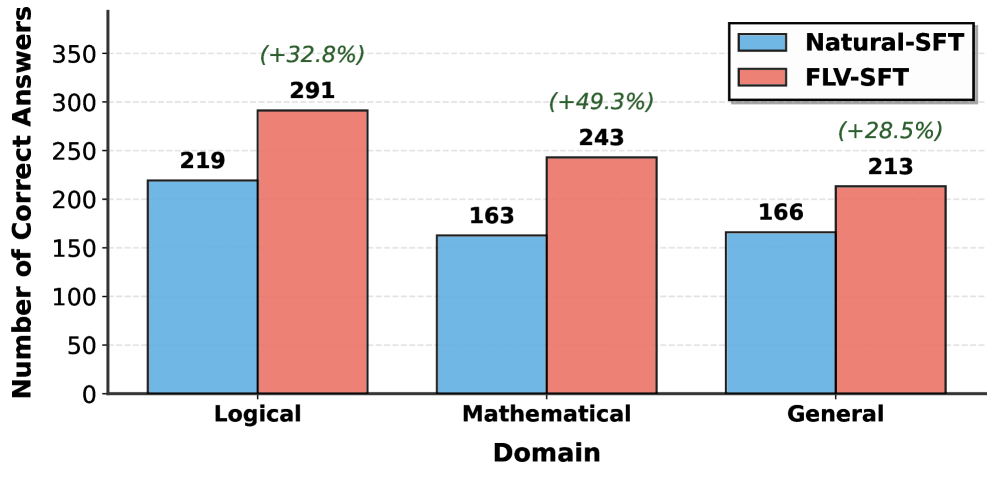
📊 实验亮点
该研究在六个基准测试中进行了广泛的评估,涵盖数学、逻辑和一般推理。结果表明,7B和14B模型分别以平均10.4%和14.2%的优势超越了最先进的基线模型。这些显著的性能提升验证了形式验证作为一种可扩展机制,能够显著提高LLM在复杂推理任务中的性能。
🎯 应用场景
该研究成果可应用于需要高可靠性和准确性的自然推理场景,例如自动定理证明、智能问答、代码生成和机器人控制等。通过将形式逻辑验证与LLM相结合,可以提高这些应用场景的智能化水平和安全性,并有望推动人工智能技术在更广泛领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.