TTCS: Test-Time Curriculum Synthesis for Self-Evolving
作者: Chengyi Yang, Zhishang Xiang, Yunbo Tang, Zongpei Teng, Chengsong Huang, Fei Long, Yuhan Liu, Jinsong Su
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-30
备注: 10 pages, 4 figures, Our code and implementation details are available at https://github.com/XMUDeepLIT/TTCS
🔗 代码/项目: GITHUB
💡 一句话要点
TTCS:面向自进化的测试时课程合成,提升大语言模型推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时训练 课程学习 协同进化 大型语言模型 推理能力
📋 核心要点
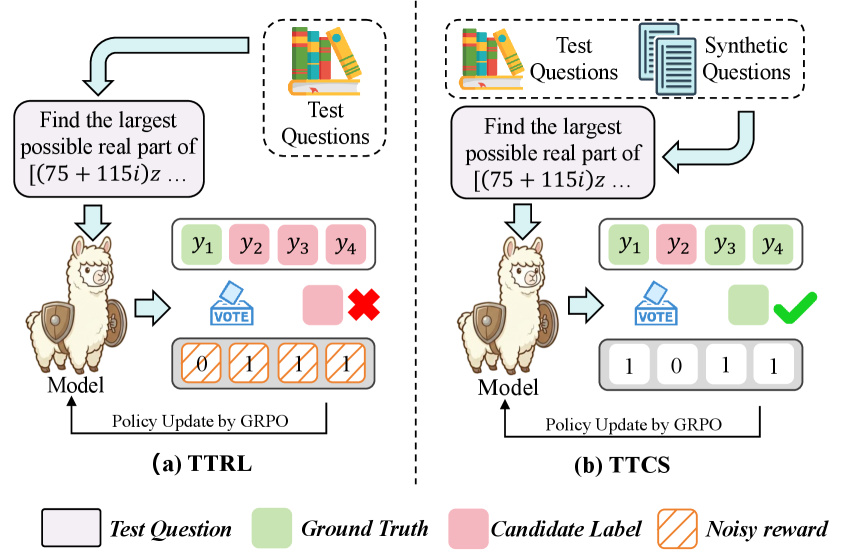
- 现有测试时训练方法难以处理困难推理问题,主要原因是原始测试问题难度过高,且测试集规模小导致训练不稳定。
- TTCS框架通过协同进化问题合成器和推理求解器,动态生成难度递增的课程,并利用自洽性奖励进行模型更新。
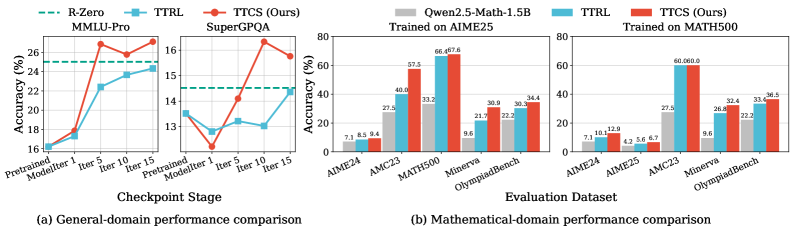
- 实验结果表明,TTCS在数学推理和通用领域任务上均能有效提升LLMs的推理能力,具有良好的可扩展性。
📝 摘要(中文)
本文提出了一种名为TTCS的协同进化测试时训练框架,旨在提升大型语言模型(LLMs)的推理能力。现有测试时训练方法在处理困难推理问题时面临挑战,因为原始测试问题难以产生高质量的伪标签,且测试集规模有限导致在线更新不稳定。TTCS通过初始化一个问题合成器和一个推理求解器来解决这些问题,这两个策略通过迭代优化进行进化。合成器生成逐渐具有挑战性的问题变体,为求解器定制结构化课程。求解器利用在原始测试和合成问题上的自洽性奖励进行自我更新。求解器的反馈指导合成器生成与模型当前能力相符的问题,而生成的变体则稳定求解器的测试时训练。实验表明,TTCS能够持续增强LLMs在数学基准测试中的推理能力,并能迁移到通用领域任务,为动态构建测试时课程以实现自进化提供了一条可扩展的路径。
🔬 方法详解
问题定义:现有测试时训练方法在提升大型语言模型推理能力方面面临挑战,尤其是在处理复杂推理问题时。主要痛点在于,直接使用原始测试集进行训练,由于问题难度过高,难以生成高质量的伪标签,导致模型难以有效学习。此外,测试集规模通常较小,持续在线更新容易导致模型不稳定,出现过拟合或灾难性遗忘等问题。
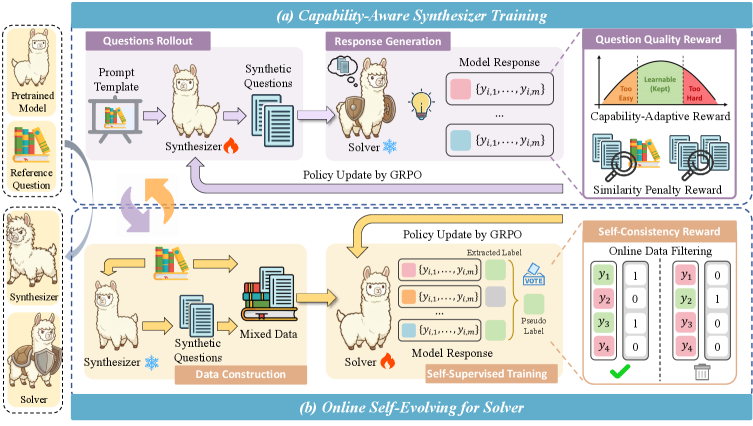
核心思路:TTCS的核心思路是通过协同进化两个策略:问题合成器和推理求解器,来构建一个动态的、自适应的测试时课程。问题合成器负责生成难度逐渐增加的问题变体,模拟一个由易到难的课程。推理求解器则利用这些合成的问题以及原始测试问题进行训练,并根据自洽性奖励进行更新。这种协同进化的方式使得问题合成器能够根据求解器的能力生成更合适的问题,而求解器则能够通过合成的问题来稳定训练,从而提升整体的推理能力。
技术框架:TTCS框架包含两个主要模块:问题合成器和推理求解器。两个模块都基于预训练的大型语言模型进行初始化。框架的整体流程如下:1) 使用问题合成器根据原始测试问题生成一系列难度递增的问题变体;2) 使用推理求解器对原始测试问题和合成问题进行推理,并生成多个答案样本;3) 根据答案样本的自洽性计算奖励,并使用该奖励来更新推理求解器;4) 使用推理求解器的反馈来更新问题合成器,使其能够生成更符合求解器能力的问题。这个过程迭代进行,直到达到预定的训练轮数或收敛条件。
关键创新:TTCS的关键创新在于协同进化的问题合成器和推理求解器。与传统的测试时训练方法不同,TTCS不是直接使用原始测试问题进行训练,而是通过问题合成器动态生成难度可控的问题变体,从而构建一个定制化的课程。这种课程学习的方式能够更好地引导模型学习,并避免了直接使用高难度问题带来的训练不稳定问题。此外,通过求解器的反馈来指导合成器的生成,使得合成的问题更符合模型当前的能力,从而实现了自适应的课程学习。
关键设计:问题合成器可以使用不同的方法来生成问题变体,例如,可以通过改变问题的某些参数、增加问题的复杂度或引入新的约束条件等方式。推理求解器可以使用自洽性奖励来评估答案的质量,例如,可以计算多个答案样本之间的相似度或一致性,并将其作为奖励信号。在训练过程中,可以使用强化学习或梯度下降等方法来更新问题合成器和推理求解器的参数。具体损失函数的设计需要根据具体的任务和模型进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TTCS在多个具有挑战性的数学推理基准测试中取得了显著的性能提升。例如,在MATH数据集上,TTCS相较于基线方法取得了超过10%的绝对提升。此外,TTCS还能够迁移到通用领域任务,例如常识推理和文本蕴含等,表明其具有良好的泛化能力。实验还验证了TTCS在不同LLM backbone上的有效性,证明了其具有良好的可扩展性。
🎯 应用场景
TTCS具有广泛的应用前景,可用于提升大型语言模型在各种推理任务中的性能,例如数学问题求解、代码生成、逻辑推理等。该方法可以应用于教育领域,为学生提供个性化的学习课程,帮助他们更好地掌握知识。此外,TTCS还可以用于开发更智能的对话系统和智能助手,使其能够更好地理解用户的问题并给出准确的答案。未来,该研究有望推动人工智能技术在各个领域的应用。
📄 摘要(原文)
Test-Time Training offers a promising way to improve the reasoning ability of large language models (LLMs) by adapting the model using only the test questions. However, existing methods struggle with difficult reasoning problems for two reasons: raw test questions are often too difficult to yield high-quality pseudo-labels, and the limited size of test sets makes continuous online updates prone to instability. To address these limitations, we propose TTCS, a co-evolving test-time training framework. Specifically, TTCS initializes two policies from the same pretrained model: a question synthesizer and a reasoning solver. These policies evolve through iterative optimization: the synthesizer generates progressively challenging question variants conditioned on the test questions, creating a structured curriculum tailored to the solver's current capability, while the solver updates itself using self-consistency rewards computed from multiple sampled responses on both original test and synthetic questions. Crucially, the solver's feedback guides the synthesizer to generate questions aligned with the model's current capability, and the generated question variants in turn stabilize the solver's test-time training. Experiments show that TTCS consistently strengthens the reasoning ability on challenging mathematical benchmarks and transfers to general-domain tasks across different LLM backbones, highlighting a scalable path towards dynamically constructing test-time curricula for self-evolving. Our code and implementation details are available at https://github.com/XMUDeepLIT/TTCS.