Continual Policy Distillation from Distributed Reinforcement Learning Teachers
作者: Yuxuan Li, Qijun He, Mingqi Yuan, Wen-Tse Chen, Jeff Schneider, Jiayu Chen
分类: cs.LG
发布日期: 2026-01-30
备注: 19 pages (8 pages main text)
💡 一句话要点
提出基于分布式强化学习教师模型的持续策略蒸馏框架,解决终身学习智能体的灾难性遗忘问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续强化学习 策略蒸馏 分布式强化学习 混合专家模型 灾难性遗忘
📋 核心要点
- 持续强化学习面临稳定性和可塑性之间的权衡,直接应用强化学习到顺序任务流难以实现可扩展的性能。
- 提出教师-学生框架,利用分布式强化学习训练单任务教师模型,再通过策略蒸馏将知识迁移到中心化的通用模型。
- 实验结果表明,该框架能够有效缓解灾难性遗忘,恢复教师模型的大部分性能,并在Meta-World基准测试上取得了显著成果。
📝 摘要(中文)
本文提出了一种新颖的教师-学生框架,用于解决持续强化学习(CRL)中的灾难性遗忘问题,旨在开发终身学习智能体,使其能够在不同任务中持续获取知识。该框架将CRL分解为两个独立的过程:通过分布式强化学习训练单任务教师模型,并将它们持续地蒸馏到一个中心化的通用模型中。这种设计基于强化学习擅长解决单个任务,而策略蒸馏与大型基础模型和多任务学习相契合的观察。此外,采用混合专家(MoE)架构和基于回放的方法来增强持续策略蒸馏过程的可塑性和稳定性。在Meta-World基准测试上的大量实验表明,该框架能够实现高效的持续强化学习,恢复超过85%的教师性能,同时将任务遗忘限制在10%以内。
🔬 方法详解
问题定义:持续强化学习(CRL)旨在训练智能体在连续的任务流中学习,但面临着灾难性遗忘的问题,即在学习新任务时忘记之前学习的任务。现有的方法难以在稳定性和可塑性之间取得平衡,并且直接将强化学习应用于顺序任务流时,性能难以扩展。
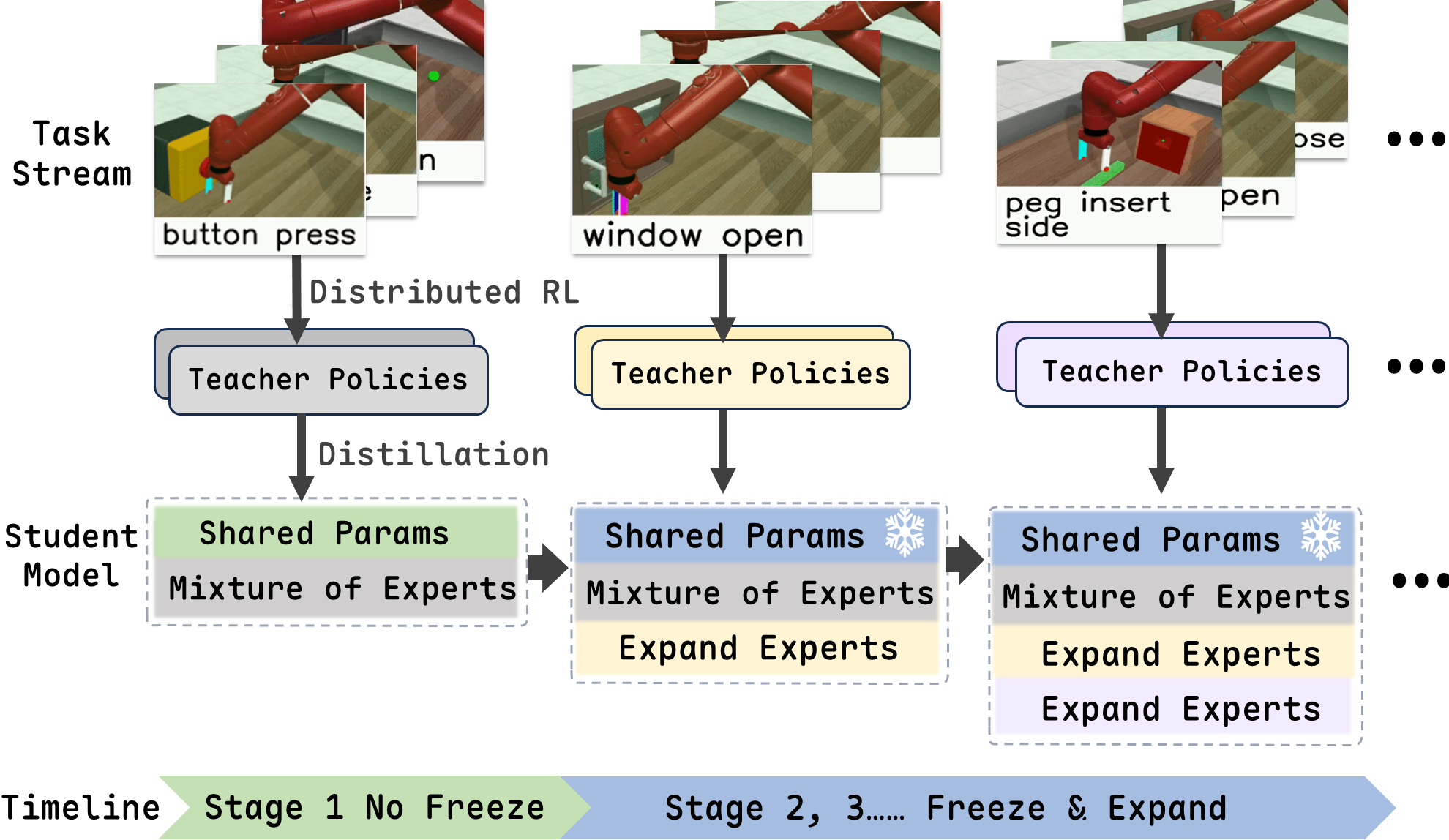
核心思路:论文的核心思路是将CRL分解为两个阶段:首先,利用分布式强化学习训练多个擅长解决单个任务的教师模型;然后,通过策略蒸馏将这些教师模型的知识迁移到一个中心化的学生模型。策略蒸馏是一个相对稳定的监督学习过程,更适合处理多任务学习和大型模型。
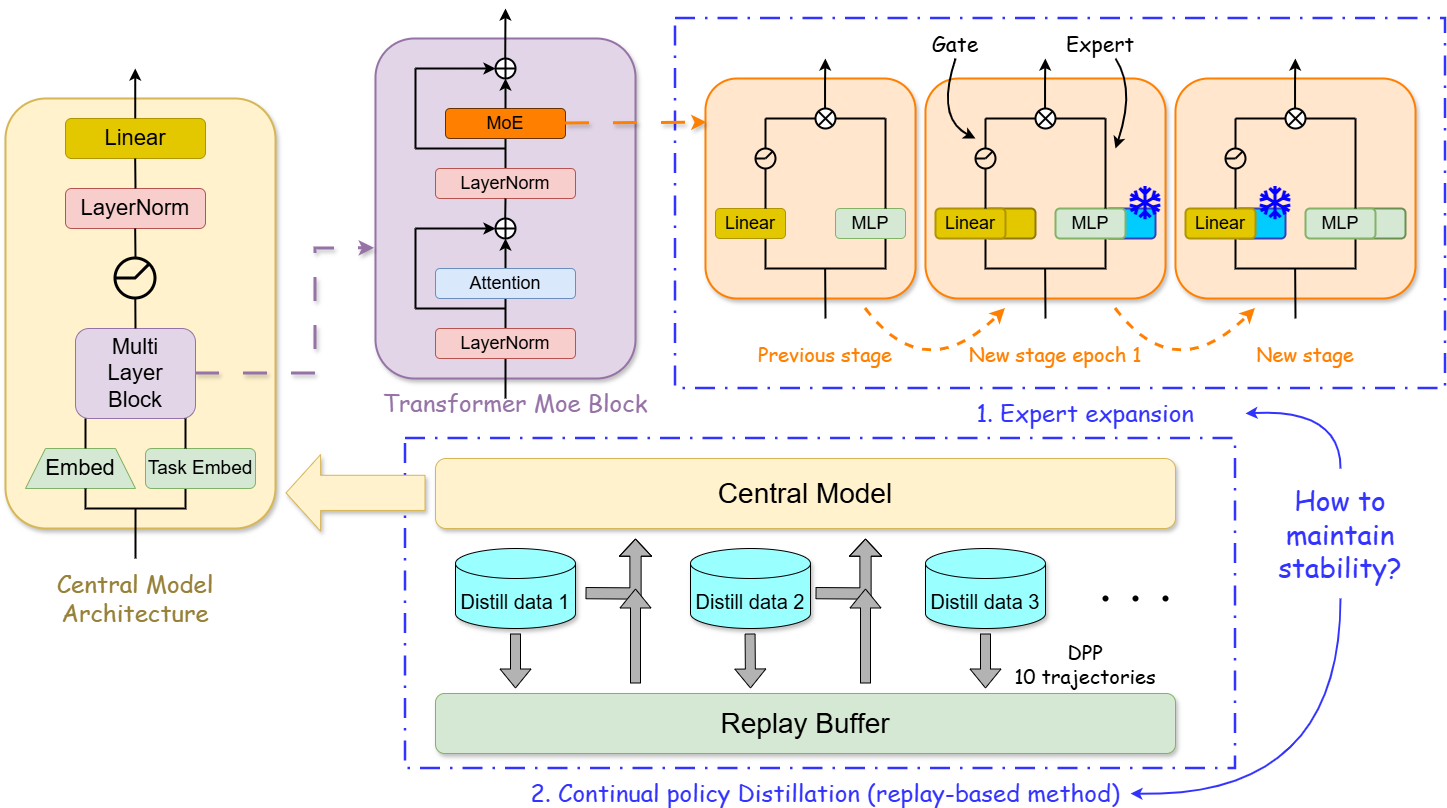
技术框架:该框架包含两个主要阶段:1) 分布式教师训练:使用分布式强化学习算法(具体算法未知)并行训练多个教师模型,每个教师模型专门解决一个特定的任务。2) 持续策略蒸馏:将训练好的教师模型作为专家,利用策略蒸馏技术将它们的知识迁移到一个中心化的学生模型。学生模型采用混合专家(MoE)架构,以便更好地学习和存储不同任务的知识。同时,使用基于回放的方法来缓解灾难性遗忘。
关键创新:该方法的主要创新在于将CRL分解为分布式教师训练和持续策略蒸馏两个独立的过程。这种解耦使得可以充分利用强化学习在解决单任务方面的优势,同时利用策略蒸馏的稳定性来缓解灾难性遗忘。此外,MoE架构和回放机制进一步增强了学生模型的可塑性和稳定性。
关键设计:关于分布式强化学习的具体算法未知。MoE架构的具体实现细节未知,包括专家数量、路由机制等。回放机制的具体实现细节未知,包括回放缓冲区的大小、采样策略等。策略蒸馏的损失函数未知,可能包括行为克隆损失、KL散度损失等。
🖼️ 关键图片

📊 实验亮点
在Meta-World基准测试中,该框架能够恢复超过85%的教师模型性能,同时将任务遗忘限制在10%以内。这些结果表明,该方法能够有效缓解灾难性遗忘,并在持续强化学习任务中取得显著的性能提升。具体的基线对比和消融实验结果未知。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、游戏AI等领域,帮助智能体在不断变化的环境中持续学习和适应。通过将知识从多个专家模型迁移到单个通用模型,可以降低部署成本,提高泛化能力,并促进终身学习智能体的发展。
📄 摘要(原文)
Continual Reinforcement Learning (CRL) aims to develop lifelong learning agents to continuously acquire knowledge across diverse tasks while mitigating catastrophic forgetting. This requires efficiently managing the stability-plasticity dilemma and leveraging prior experience to rapidly generalize to novel tasks. While various enhancement strategies for both aspects have been proposed, achieving scalable performance by directly applying RL to sequential task streams remains challenging. In this paper, we propose a novel teacher-student framework that decouples CRL into two independent processes: training single-task teacher models through distributed RL and continually distilling them into a central generalist model. This design is motivated by the observation that RL excels at solving single tasks, while policy distillation -- a relatively stable supervised learning process -- is well aligned with large foundation models and multi-task learning. Moreover, a mixture-of-experts (MoE) architecture and a replay-based approach are employed to enhance the plasticity and stability of the continual policy distillation process. Extensive experiments on the Meta-World benchmark demonstrate that our framework enables efficient continual RL, recovering over 85% of teacher performance while constraining task-wise forgetting to within 10%.