Value-Based Pre-Training with Downstream Feedback
作者: Shuqi Ke, Giulia Fanti
分类: cs.LG, cs.AI
发布日期: 2026-01-29
💡 一句话要点
V-Pretraining:利用下游反馈指导预训练,提升模型下游任务性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练 自监督学习 下游任务 梯度对齐 任务设计 价值函数 持续学习
📋 核心要点
- 传统预训练方法使用固定代理目标,可能导致计算资源分配不当,无法有效提升下游任务性能。
- V-Pretraining通过任务设计器调整预训练任务,使预训练梯度与下游任务梯度对齐,从而引导预训练。
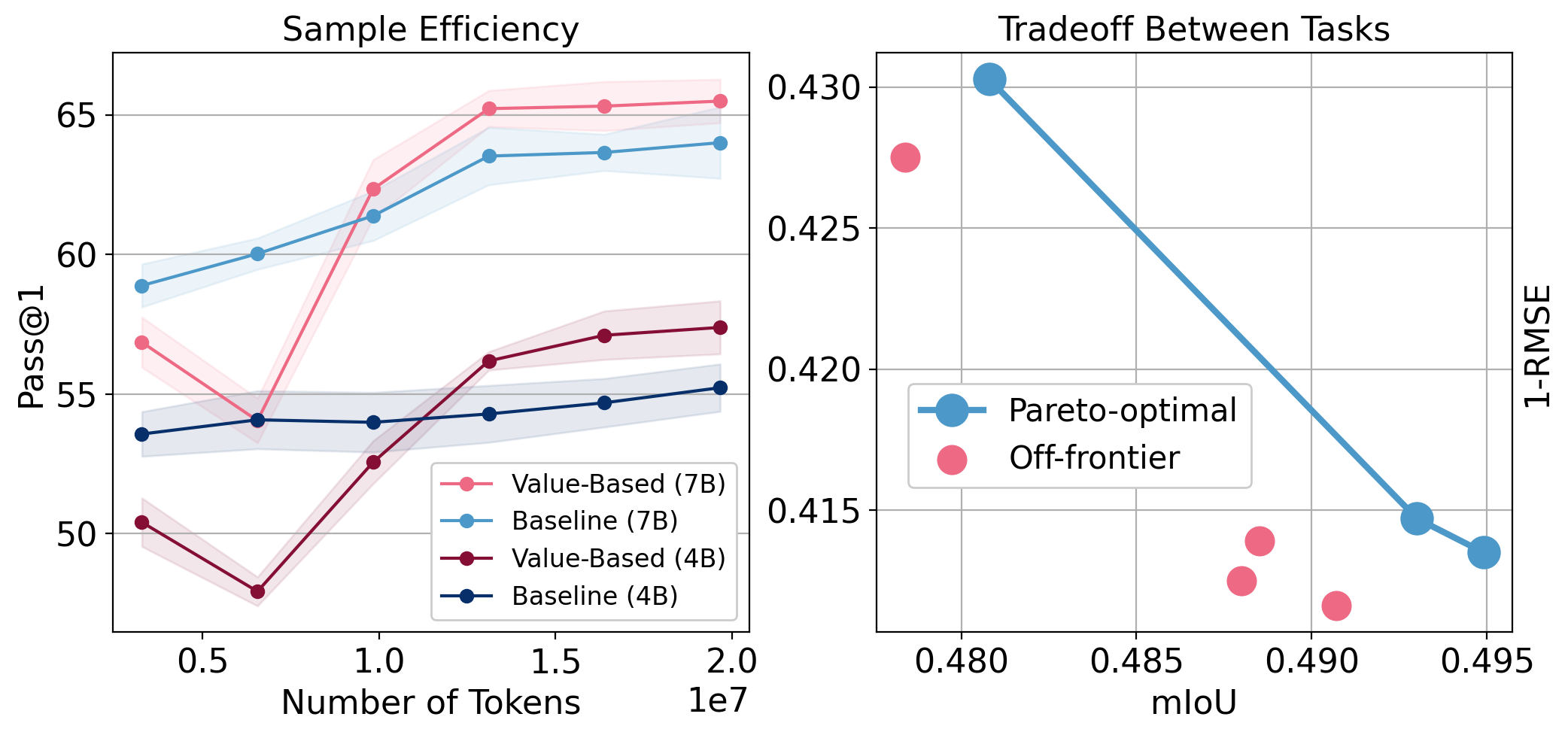
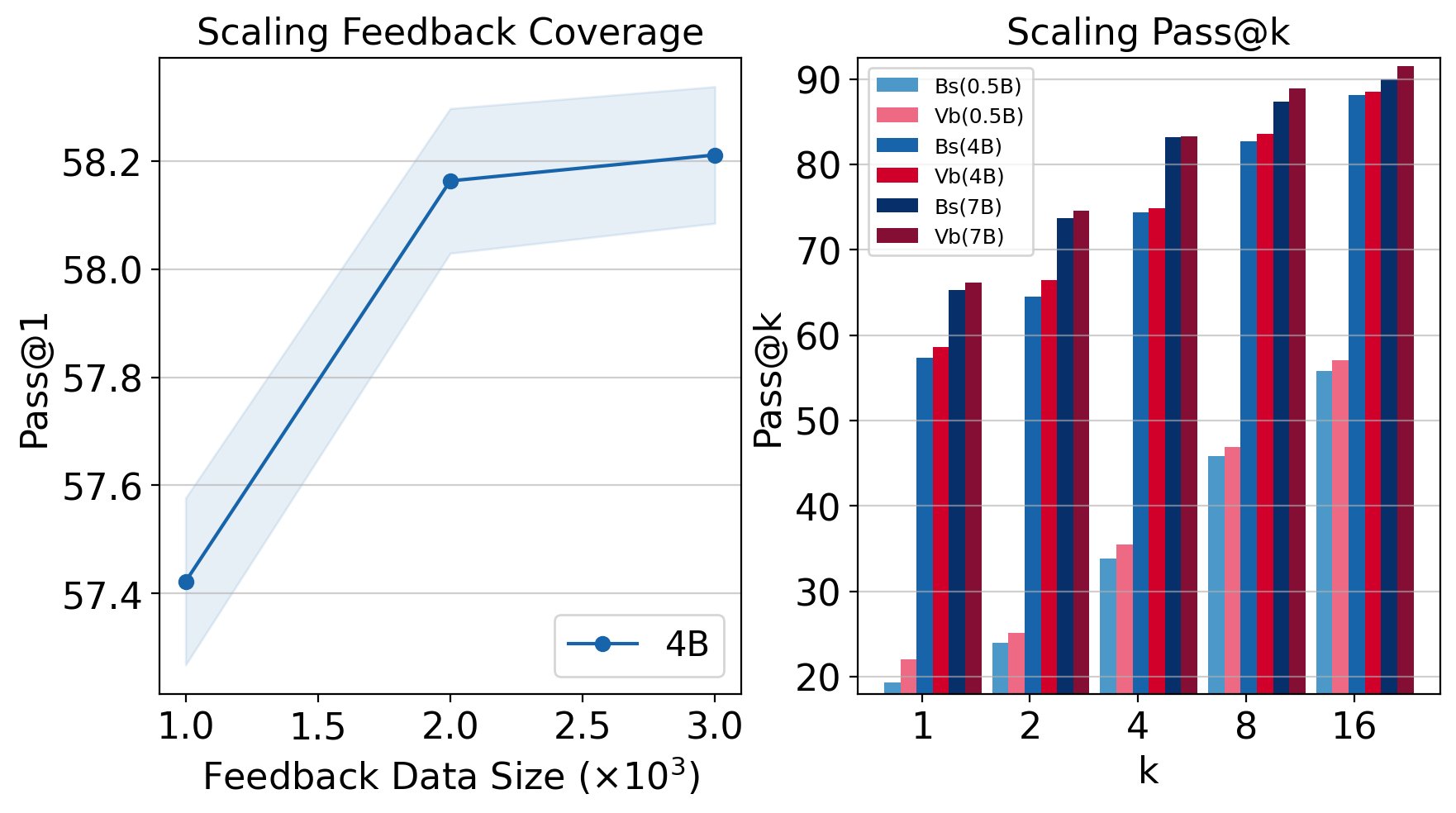
- 实验表明,V-Pretraining在语言和视觉任务上均能显著提升模型性能,并提高token效率。
📝 摘要(中文)
本文提出了一种基于价值的预训练方法(V-Pretraining),旨在利用少量的验证过的目标信息来引导大型基础模型的自监督预训练。与优化固定代理目标(如next-token预测)的标准预训练不同,V-Pretraining是一种模态无关的方法,通过轻量级的任务设计器重塑预训练任务,以最大化每个梯度步骤的价值。例如,在带有样本增强的自监督学习中,任务设计器选择预训练损失梯度与下游任务梯度对齐的预训练任务(如增强方式),从而引导预训练关注相关的下游能力。值得注意的是,预训练模型从不在下游任务标签上更新,这些标签仅用于塑造预训练任务。在相同的学习器更新预算下,V-Pretraining将0.5B-7B语言模型的推理能力(GSM8K测试Pass@1)相对于标准next-token预测提高了高达18%,且仅使用了12%的GSM8K训练样本作为反馈。在视觉自监督学习中,我们在ADE20K上将最先进的结果提高了高达1.07 mIoU,并降低了NYUv2的RMSE,同时提高了ImageNet的线性精度。我们还提供了在持续预训练中提高token效率的初步证据。
🔬 方法详解
问题定义:现有的大型预训练模型通常采用自监督学习方法,例如语言模型的next-token预测或图像模型的对比学习。这些方法使用固定的代理目标进行训练,而这些代理目标可能与下游任务的需求不完全一致。因此,模型可能在与下游任务无关的方面投入过多的计算资源,导致下游任务性能提升有限。
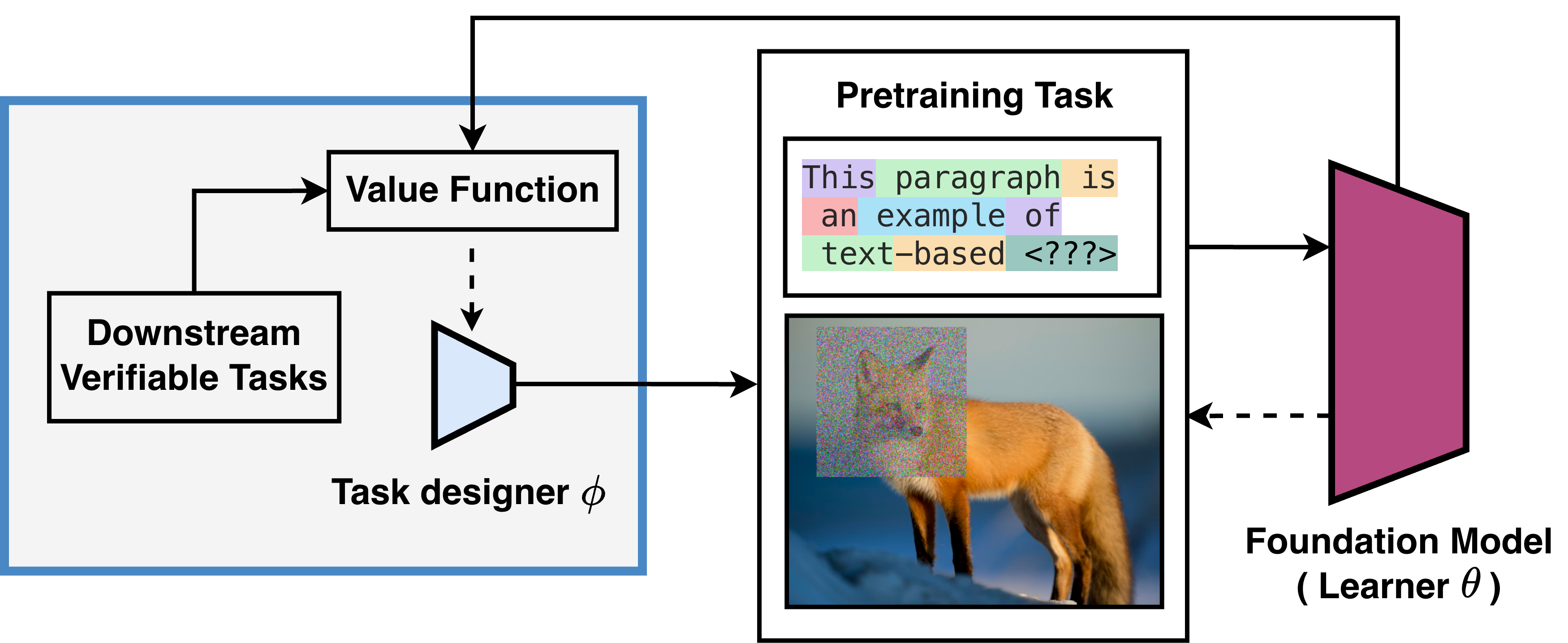
核心思路:V-Pretraining的核心思想是利用下游任务的反馈来指导预训练过程。具体来说,它通过一个任务设计器来选择或调整预训练任务,使得预训练的梯度方向与下游任务的梯度方向尽可能对齐。这样可以确保预训练过程能够有效地提升模型在下游任务上的性能。
技术框架:V-Pretraining的整体框架包括以下几个主要模块:1) 预训练模型:待训练的基础模型。2) 任务设计器:根据下游任务的反馈,选择或调整预训练任务。3) 预训练损失:用于训练预训练模型的损失函数。4) 下游任务损失:用于评估预训练任务与下游任务的相关性。任务设计器根据下游任务损失的梯度信息,调整预训练任务,使得预训练损失的梯度与下游任务损失的梯度对齐。
关键创新:V-Pretraining的关键创新在于它将下游任务的反馈融入到预训练过程中,从而实现了有针对性的预训练。与传统的预训练方法相比,V-Pretraining能够更有效地利用计算资源,提升模型在下游任务上的性能。此外,V-Pretraining是一种模态无关的方法,可以应用于不同的任务和模型。
关键设计:任务设计器的具体实现方式可以根据不同的任务和模型进行调整。例如,在图像自监督学习中,任务设计器可以选择不同的数据增强方式,使得预训练模型能够学习到对下游任务更有用的特征。在语言模型中,任务设计器可以选择不同的文本片段进行预测,或者调整预测的难度。损失函数的设计也至关重要,需要能够有效地衡量预训练梯度和下游任务梯度之间的对齐程度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,V-Pretraining在语言模型和视觉模型上均取得了显著的性能提升。在语言模型方面,V-Pretraining将GSM8K测试的Pass@1指标提高了高达18%。在视觉模型方面,V-Pretraining在ADE20K数据集上将mIoU提高了1.07,并降低了NYUv2数据集的RMSE,同时提高了ImageNet的线性精度。这些结果表明,V-Pretraining是一种有效的预训练方法,可以显著提升模型在下游任务上的性能。
🎯 应用场景
V-Pretraining具有广泛的应用前景,可以应用于各种需要预训练模型的领域,例如自然语言处理、计算机视觉和机器人学习。它可以帮助开发者更有效地训练大型模型,提升模型在各种下游任务上的性能,例如图像分类、目标检测、语义分割、文本生成和机器翻译。此外,V-Pretraining还可以用于持续预训练,提高模型的token效率,降低训练成本。
📄 摘要(原文)
Can a small amount of verified goal information steer the expensive self-supervised pretraining of foundation models? Standard pretraining optimizes a fixed proxy objective (e.g., next-token prediction), which can misallocate compute away from downstream capabilities of interest. We introduce V-Pretraining: a value-based, modality-agnostic method for controlled continued pretraining in which a lightweight task designer reshapes the pretraining task to maximize the value of each gradient step. For example, consider self-supervised learning (SSL) with sample augmentation. The V-Pretraining task designer selects pretraining tasks (e.g., augmentations) for which the pretraining loss gradient is aligned with a gradient computed over a downstream task (e.g., image segmentation). This helps steer pretraining towards relevant downstream capabilities. Notably, the pretrained model is never updated on downstream task labels; they are used only to shape the pretraining task. Under matched learner update budgets, V-Pretraining of 0.5B--7B language models improves reasoning (GSM8K test Pass@1) by up to 18% relative over standard next-token prediction using only 12% of GSM8K training examples as feedback. In vision SSL, we improve the state-of-the-art results on ADE20K by up to 1.07 mIoU and reduce NYUv2 RMSE while improving ImageNet linear accuracy, and we provide pilot evidence of improved token efficiency in continued pretraining.