Making Foundation Models Probabilistic via Singular Value Ensembles
作者: Mehmet Ozgur Turkoglu, Dominik J. Mühlematter, Alexander Becker, Konrad Schindler, Helge Aasen
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出奇异值集成(SVE),通过高效参数调整实现概率化Foundation Model,提升不确定性量化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Foundation Model 不确定性量化 奇异值分解 模型集成 参数高效
📋 核心要点
- 现有Foundation Model预测过度自信,不确定性量化不足,而传统集成方法计算成本过高。
- SVE方法通过调整权重矩阵奇异值,实现参数高效的隐式集成,提升模型不确定性估计能力。
- 实验表明,SVE在NLP和视觉任务上,以极低的参数增加,实现了与深度集成相当的不确定性量化效果。
📝 摘要(中文)
Foundation Model已成为机器学习领域的主导范式,通过大规模预训练在各种任务中取得了显著的性能。然而,这些模型通常会产生过度自信、未校准的预测。量化认知不确定性的标准方法,即训练独立模型的集成,会产生巨大的计算成本,该成本与集成规模呈线性关系,这使得它对于大型Foundation Model来说是不切实际的。我们提出了奇异值集成(SVE),这是一种参数高效的隐式集成方法,它建立在一个简单但强大的核心假设之上:即权重矩阵的奇异向量构成了模型知识的有意义的子空间。预训练的Foundation Model在其权重矩阵中编码了丰富的、可转移的信息。如果奇异向量确实是有意义的(正交的)“知识方向”,为了获得模型集成,我们只调节每个方向对输出的贡献强度。我们冻结奇异向量,只训练每个成员的奇异值,这些奇异值会重新调整该共享知识库中每个方向的贡献,而不是学习全新的参数。集成多样性自然而然地出现,因为联合训练期间的随机初始化和mini-batch的随机抽样导致不同的成员收敛到相同底层知识的不同组合。SVE实现了与显式深度集成相当的不确定性量化,同时将基础模型的参数数量增加不到1%,这使得在资源受限的环境中可以进行有原则的不确定性估计。我们在NLP和视觉任务上使用各种不同的backbone验证了SVE,并表明它在保持预测准确性的同时提高了校准。
🔬 方法详解
问题定义:Foundation Model虽然在各种任务中表现出色,但其预测往往过于自信,缺乏良好的校准。现有的不确定性量化方法,如深度集成,需要训练多个独立的模型,计算成本随模型数量线性增长,对于大型Foundation Model而言,这种方法是不可行的。因此,如何在计算资源有限的情况下,为Foundation Model提供可靠的不确定性估计是一个关键问题。
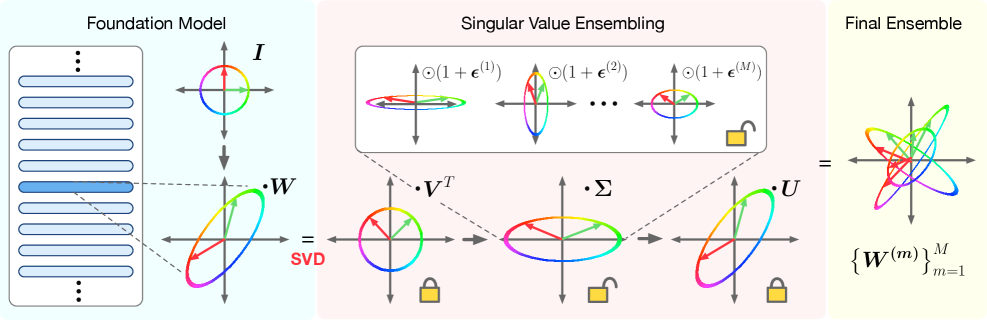
核心思路:SVE的核心思路是利用权重矩阵的奇异值分解,将模型的知识分解为一组正交的奇异向量,并认为这些奇异向量代表了模型学习到的不同“知识方向”。通过调整每个奇异向量对应的奇异值,可以控制该“知识方向”对模型输出的贡献程度。SVE通过训练多个具有不同奇异值的模型,形成一个隐式集成,从而实现不确定性量化。这种方法避免了训练多个完整模型的巨大计算开销。
技术框架:SVE的技术框架主要包含以下几个步骤:1. 对预训练的Foundation Model的权重矩阵进行奇异值分解(SVD)。2. 冻结奇异向量,只保留奇异值作为可训练参数。3. 初始化多个具有不同奇异值的模型成员。4. 使用随机梯度下降等优化算法,联合训练这些模型成员的奇异值。5. 在推理时,将多个模型成员的预测结果进行平均或加权平均,得到最终的预测结果和不确定性估计。
关键创新:SVE的关键创新在于它提出了一种参数高效的隐式集成方法,通过调整权重矩阵的奇异值来实现不确定性量化。与传统的深度集成方法相比,SVE只需要训练少量的参数(奇异值),大大降低了计算成本。此外,SVE利用了预训练模型的知识,避免了从头开始训练多个模型的需要。
关键设计:SVE的关键设计包括:1. 奇异值的初始化方法:可以使用随机初始化或基于预训练模型的奇异值进行初始化。2. 奇异值的优化算法:可以使用随机梯度下降、Adam等优化算法。3. 模型成员的数量:需要根据计算资源和性能要求进行选择。4. 集成方法:可以使用简单的平均或加权平均,也可以使用更复杂的集成方法,如贝叶斯模型平均。
🖼️ 关键图片

📊 实验亮点
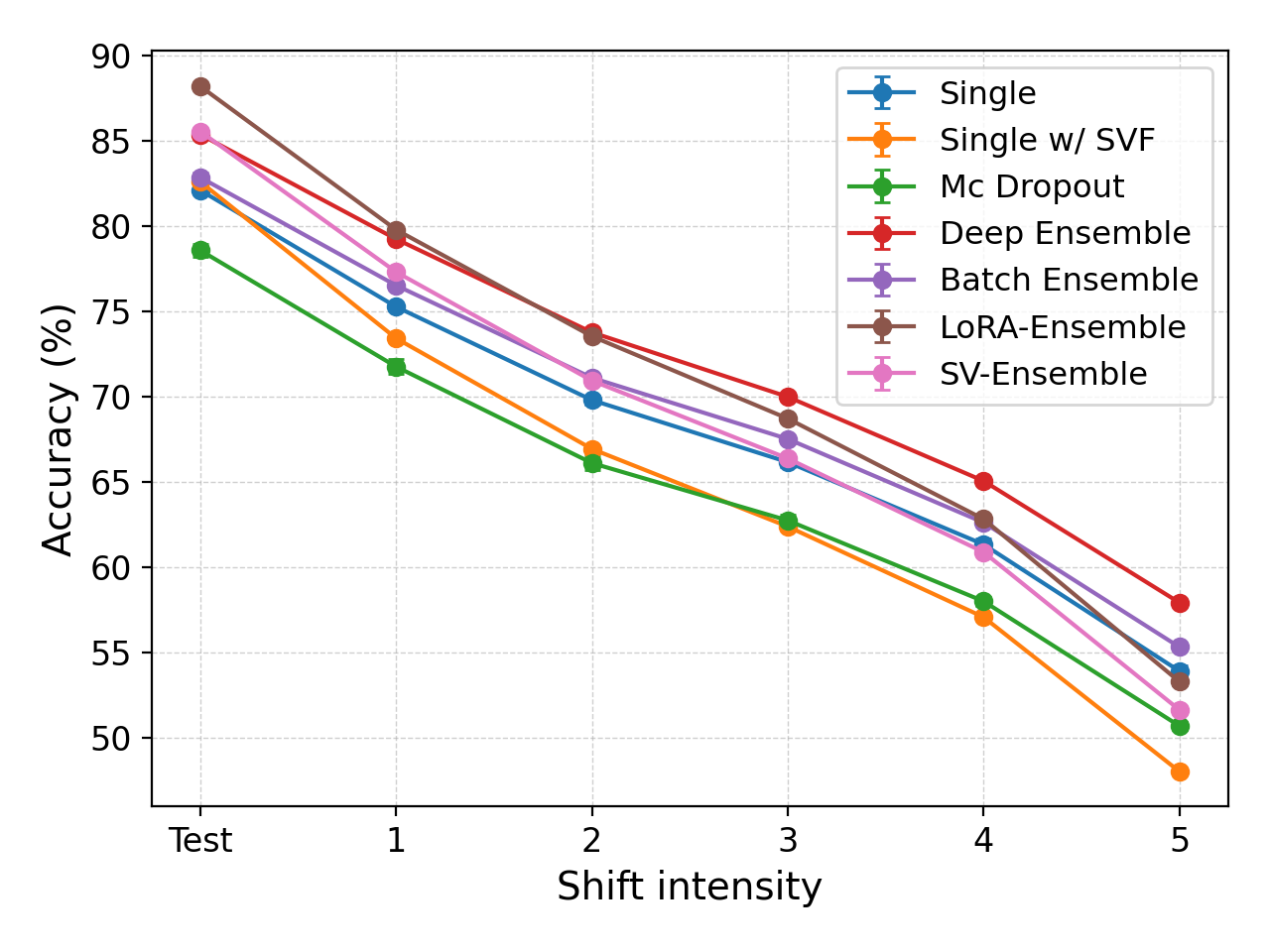
SVE在多个NLP和视觉任务上进行了验证,结果表明,SVE能够以极低的参数增加(小于1%)实现与深度集成相当的不确定性量化效果。例如,在图像分类任务中,SVE在保持预测准确率的同时,显著提高了模型的校准度。与基线方法相比,SVE在不确定性估计方面取得了显著的提升。
🎯 应用场景
SVE方法可广泛应用于需要可靠不确定性估计的Foundation Model应用场景,例如自动驾驶、医疗诊断、金融风控等。在这些领域,模型预测的准确性和可靠性至关重要,SVE可以帮助提高模型的决策质量,降低风险。此外,SVE的参数高效性使其特别适用于资源受限的边缘设备和移动应用。
📄 摘要(原文)
Foundation models have become a dominant paradigm in machine learning, achieving remarkable performance across diverse tasks through large-scale pretraining. However, these models often yield overconfident, uncalibrated predictions. The standard approach to quantifying epistemic uncertainty, training an ensemble of independent models, incurs prohibitive computational costs that scale linearly with ensemble size, making it impractical for large foundation models. We propose Singular Value Ensemble (SVE), a parameter-efficient implicit ensemble method that builds on a simple, but powerful core assumption: namely, that the singular vectors of the weight matrices constitute meaningful subspaces of the model's knowledge. Pretrained foundation models encode rich, transferable information in their weight matrices. If the singular vectors are indeed meaningful (orthogonal) "knowledge directions". To obtain a model ensemble, we modulate only how strongly each direction contributes to the output. Rather than learning entirely new parameters, we freeze the singular vectors and only train per-member singular values that rescale the contribution of each direction in that shared knowledge basis. Ensemble diversity emerges naturally as stochastic initialization and random sampling of mini-batches during joint training cause different members to converge to different combinations of the same underlying knowledge. SVE achieves uncertainty quantification comparable to explicit deep ensembles while increasing the parameter count of the base model by less than 1%, making principled uncertainty estimation accessible in resource-constrained settings. We validate SVE on NLP and vision tasks with various different backbones and show that it improves calibration while maintaining predictive accuracy.