TBDFiltering: Sample-Efficient Tree-Based Data Filtering
作者: Robert Istvan Busa-Fekete, Julian Zimmert, Anne Xiangyi Zheng, Claudio Gentile, Andras Gyorgy
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出TBDFiltering,一种基于树结构的文本数据高效过滤方法,提升LLM训练数据质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据过滤 大型语言模型 分层聚类 文本嵌入 质量评估
📋 核心要点
- 大型语言模型训练依赖高质量数据,但现有方法缺乏高效的质量评估手段,难以处理海量数据。
- 论文提出基于文本嵌入的分层聚类方法,自适应选择文档并查询LLM,估计聚类质量,提升数据筛选效率。
- 理论证明该方法具有查询效率,实验表明其性能优于其他基于分类器的过滤方法,有效提升数据质量。
📝 摘要(中文)
本文提出了一种基于文本嵌入的分层聚类方法,用于自适应地选择文档,并通过查询大型语言模型(LLM)来评估聚类质量,从而为LLM训练选择高质量、多样化的训练集。该方法旨在解决因缺乏廉价且可靠的质量指标而导致的大规模文档质量评估难题。理论分析表明,在分层聚类包含一个叶子簇足够纯净的子树的假设下,该方法能够以高概率正确预测每个文档的质量,且查询的文档数量与最小纯净叶子子树的大小成正比。实验结果表明,与其它基于分类器的过滤方法相比,该算法具有显著优势。
🔬 方法详解
问题定义:大规模语言模型(LLM)的训练需要海量的训练数据,但并非所有数据都具有相同的质量。低质量的数据会损害模型的性能。现有的文档质量评估方法,例如直接查询LLM,成本高昂,无法扩展到数十亿文档的规模。而使用基于稀疏质量信号训练的分类器,其泛化能力有限,效果往往不佳。因此,如何高效地从海量数据中筛选出高质量的训练数据是一个关键问题。
核心思路:论文的核心思路是利用文本嵌入将文档表示为向量,然后进行分层聚类。通过自适应地选择聚类中的代表性文档,并使用LLM评估这些文档的质量,从而推断整个聚类的质量。这种方法避免了对所有文档进行评估,显著降低了计算成本。核心在于假设存在一个“纯净”的子树,即该子树的叶子节点包含的文档质量高度一致。
技术框架:TBDFiltering算法的整体流程如下:1) 使用文本嵌入模型(例如Sentence-BERT)将所有文档转换为向量表示。2) 对这些向量进行分层聚类,构建一棵树状结构。3) 从根节点开始,自适应地选择每个节点中的代表性文档进行LLM质量评估。4) 根据评估结果,判断该节点是否“纯净”。如果纯净,则停止评估该节点下的子树;否则,继续评估子节点。5) 最终,根据评估结果对所有文档进行过滤。
关键创新:该方法最重要的创新点在于其自适应的文档选择策略。传统方法通常需要评估所有文档,而TBDFiltering只评估聚类中的代表性文档,从而显著降低了计算成本。此外,该方法利用分层聚类的结构,可以有效地利用文档之间的相似性信息,提高评估的准确性。与现有方法的本质区别在于,TBDFiltering不是直接训练一个分类器来预测文档质量,而是利用LLM的强大能力来评估聚类质量,并根据聚类结构进行推断。
关键设计:算法的关键设计包括:1) 文本嵌入模型的选择:选择合适的文本嵌入模型对于文档表示的质量至关重要。2) 分层聚类算法的选择:不同的聚类算法可能会影响聚类的质量和效率。3) 代表性文档的选择策略:如何选择能够代表聚类质量的文档是一个关键问题。4) LLM质量评估的标准:如何定义文档的“质量”以及如何使用LLM进行评估需要仔细考虑。论文中可能使用了特定的参数设置来平衡效率和准确性,例如,每个节点选择的代表性文档数量,以及判断节点是否“纯净”的阈值。
🖼️ 关键图片

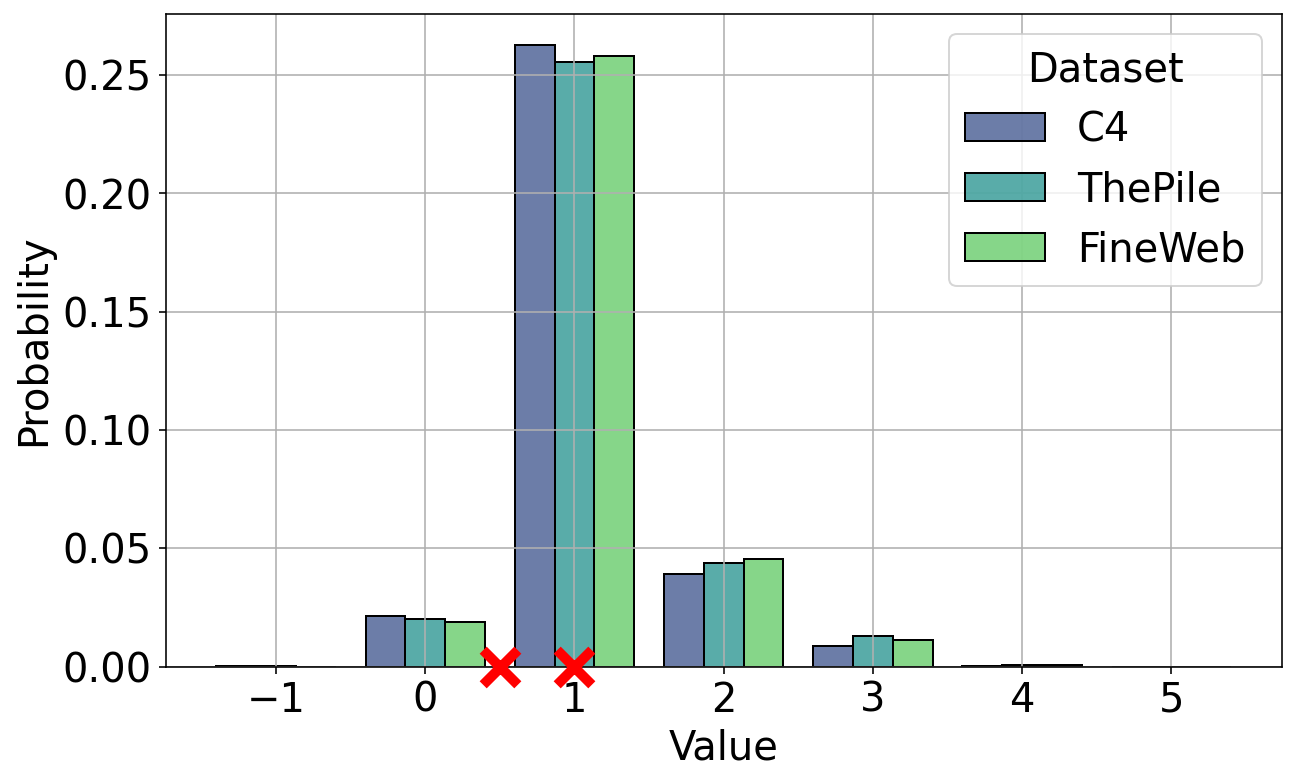
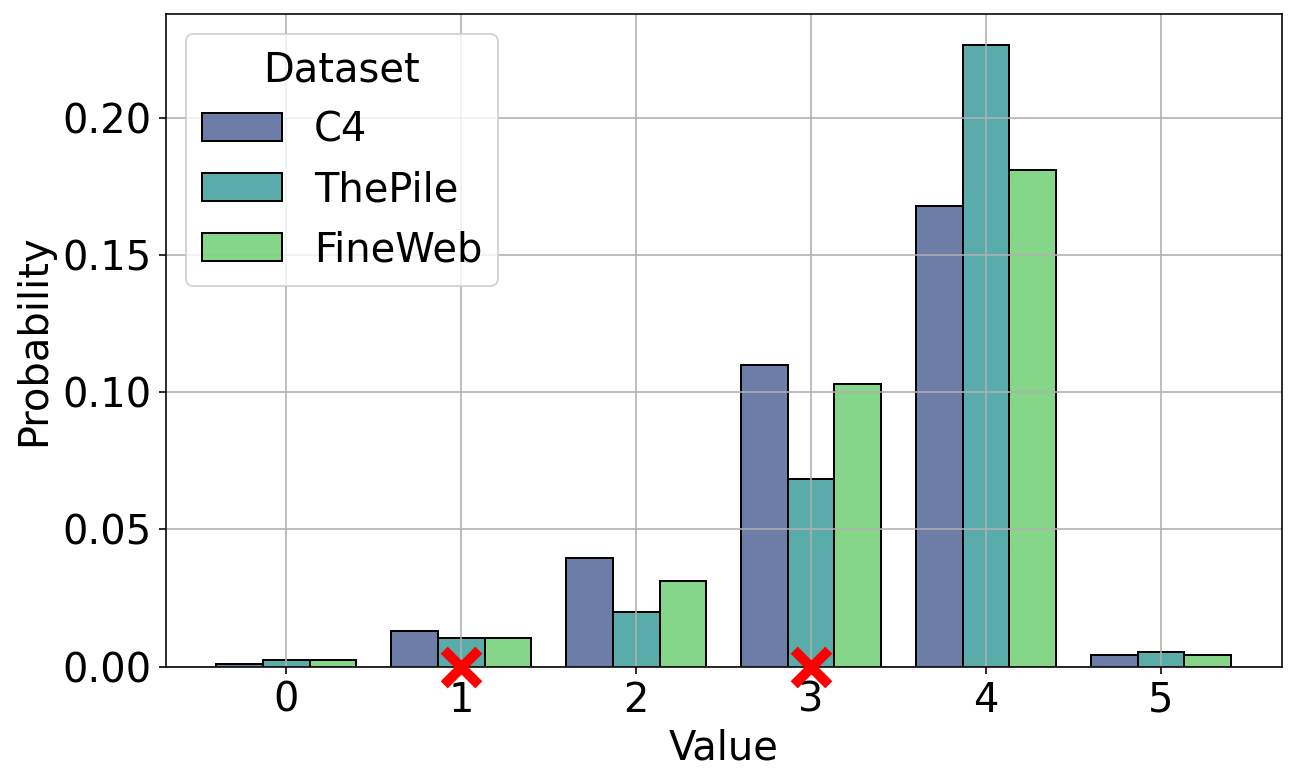
📊 实验亮点
实验结果表明,TBDFiltering算法在数据过滤任务中表现出色,能够以更少的查询次数达到与传统方法相当甚至更好的性能。具体来说,该算法在保证一定准确率的前提下,显著减少了需要人工评估的文档数量,从而降低了数据清洗的成本。与基于分类器的过滤方法相比,TBDFiltering能够更有效地识别和过滤低质量文档,提升了训练数据的整体质量。
🎯 应用场景
TBDFiltering算法可广泛应用于大型语言模型的训练数据清洗、高质量数据集构建、以及信息检索等领域。通过高效地过滤低质量数据,可以显著提升LLM的训练效率和模型性能。该方法还可以用于构建特定领域的高质量数据集,例如医疗、金融等,从而促进相关领域AI应用的发展。未来,该方法有望扩展到其他类型的数据过滤任务中,例如图像、音频等。
📄 摘要(原文)
The quality of machine learning models depends heavily on their training data. Selecting high-quality, diverse training sets for large language models (LLMs) is a difficult task, due to the lack of cheap and reliable quality metrics. While querying existing LLMs for document quality is common, this is not scalable to the large number (billions) of documents used in training. Instead, practitioners often use classifiers trained on sparse quality signals. In this paper, we propose a text-embedding-based hierarchical clustering approach that adaptively selects the documents to be evaluated by the LLM to estimate cluster quality. We prove that our method is query efficient: under the assumption that the hierarchical clustering contains a subtree such that each leaf cluster in the tree is pure enough (i.e., it mostly contains either only good or only bad documents), with high probability, the method can correctly predict the quality of each document after querying a small number of documents. The number of such documents is proportional to the size of the smallest subtree with (almost) pure leaves, without the algorithm knowing this subtree in advance. Furthermore, in a comprehensive experimental study, we demonstrate the benefits of our algorithm compared to other classifier-based filtering methods.