Not All Code Is Equal: A Data-Centric Study of Code Complexity and LLM Reasoning
作者: Lukas Twist, Shu Yang, Hanqi Yan, Jingzhi Gong, Di Wang, Helen Yannakoudakis, Jie M. Zhang
分类: cs.LG
发布日期: 2026-01-29
备注: 16 pages, 5 figures, 3 tables
💡 一句话要点
研究代码复杂度对LLM推理能力的影响,提出数据中心的代码选择策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码复杂度 推理能力 微调 数据中心 圈复杂度 控制流 结构化学习
📋 核心要点
- 现有研究将代码视为通用训练信号,忽略了代码属性对LLM推理能力的影响。
- 论文研究代码的结构复杂度,包括控制流和组合结构,探索其对LLM推理能力的影响。
- 实验表明,特定结构复杂度范围的代码微调优于结构多样化的代码,提升LLM推理能力。
📝 摘要(中文)
大型语言模型(LLM)日益展现出强大的推理能力,这通常归因于它们生成思维链式中间推理的能力。最近的研究表明,接触代码可以进一步增强这些技能,但现有研究大多将代码视为一种通用的训练信号,而忽略了代码的哪些属性实际上有助于提高推理能力。为了弥补这一差距,我们研究了代码的结构复杂度,它捕捉了控制流和组合结构,这些结构可能会影响模型在微调期间如何内化多步推理。我们考察了两种互补的设置:解决方案驱动的复杂性,其中复杂性在同一问题的多个解决方案中变化;以及问题驱动的复杂性,其中复杂性反映了底层任务的变化。我们使用圈复杂度(cyclomatic complexity)和逻辑代码行数来构建受控的微调数据集,并在不同的推理基准上评估了一系列开放权重的LLM。我们的研究结果表明,虽然代码可以提高推理能力,但结构属性强烈决定了它的效用。在83%的实验中,将微调数据限制在特定的结构复杂度范围内,优于在结构多样化的代码上进行训练,这为超越规模化,通过数据中心的方法来提高推理能力指明了方向。
🔬 方法详解
问题定义:现有研究未能充分理解代码的哪些具体属性能够有效提升大型语言模型(LLM)的推理能力。以往的研究通常将代码视为一种通用的训练信号,忽略了代码内部结构复杂度的差异。这种忽略可能导致训练效率低下,并且无法充分挖掘代码在提升LLM推理能力方面的潜力。
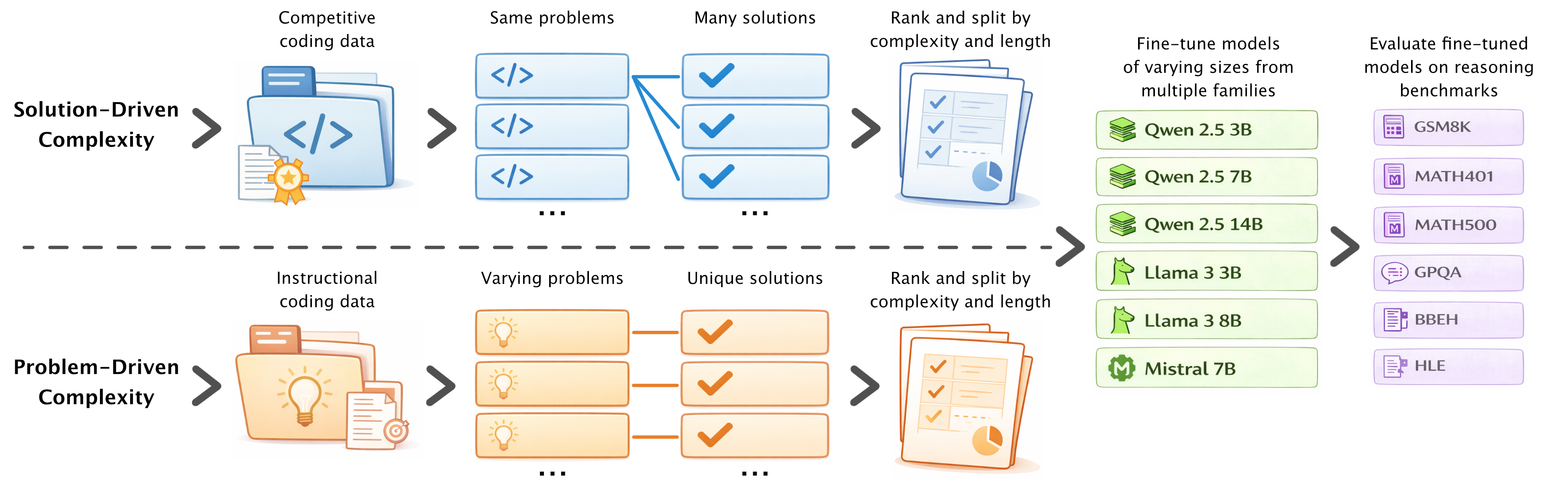
核心思路:论文的核心思路是研究代码的结构复杂度与LLM推理能力之间的关系。通过控制代码的结构复杂度,并观察LLM在不同推理任务上的表现,来确定哪些复杂度的代码更有助于提升LLM的推理能力。这种数据中心的方法旨在通过选择合适的代码数据来优化LLM的训练过程。
技术框架:论文采用了一种实验驱动的方法。首先,定义了两种类型的代码复杂度:解决方案驱动的复杂度和问题驱动的复杂度。然后,使用圈复杂度(cyclomatic complexity)和逻辑代码行数作为衡量代码结构复杂度的指标。接下来,构建了不同复杂度范围的微调数据集,并使用这些数据集对一系列开放权重的LLM进行微调。最后,在多个推理基准上评估了微调后的LLM的性能。
关键创新:论文的关键创新在于提出了数据中心的代码选择策略,即通过控制代码的结构复杂度来优化LLM的训练过程。与以往将代码视为通用训练信号的研究不同,该论文强调了代码结构属性的重要性,并证明了特定复杂度范围的代码更有助于提升LLM的推理能力。
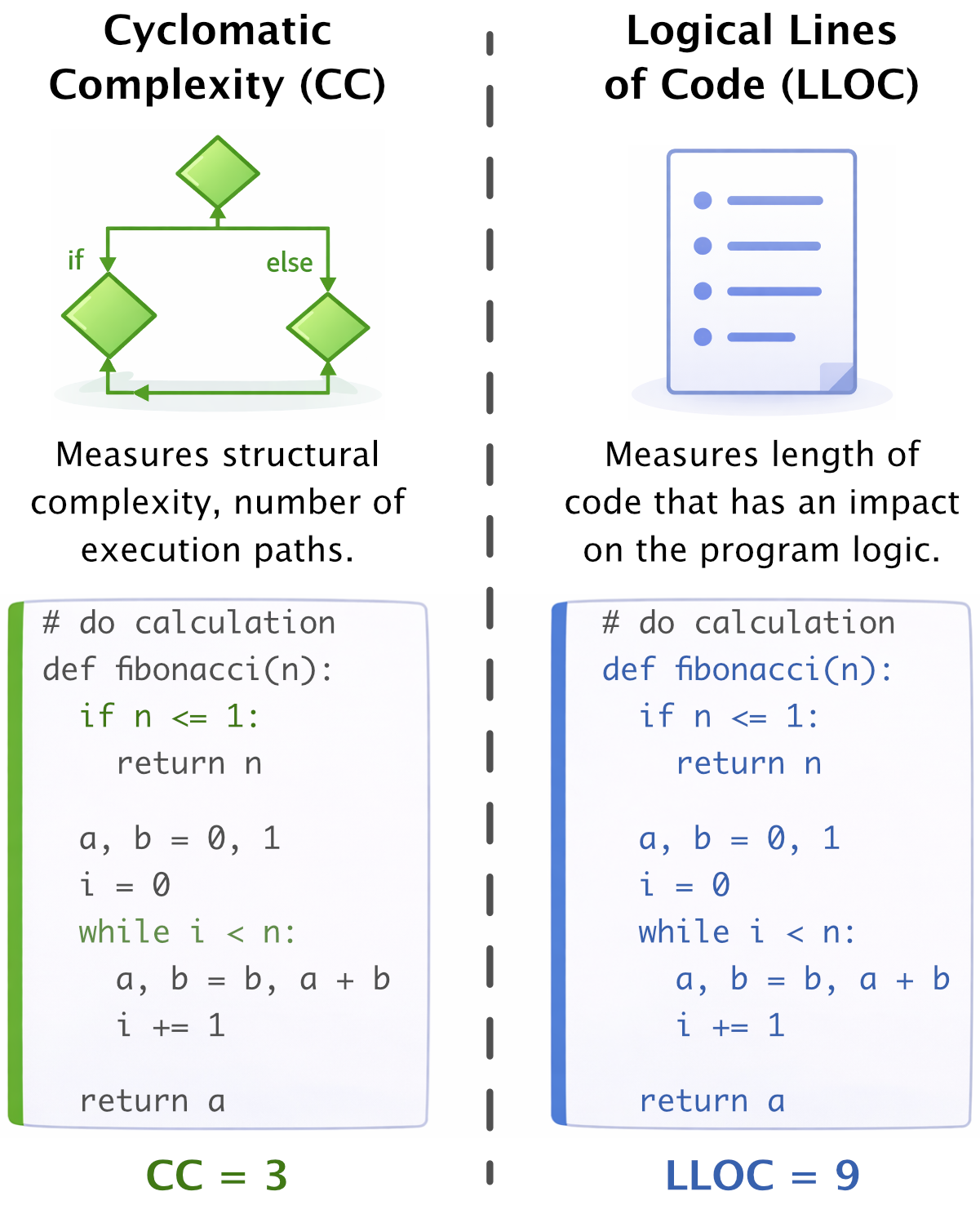
关键设计:论文的关键设计包括:1) 使用圈复杂度和逻辑代码行数作为衡量代码结构复杂度的指标;2) 构建不同复杂度范围的微调数据集;3) 在多个推理基准上评估LLM的性能。具体来说,圈复杂度衡量了代码的控制流复杂度,逻辑代码行数衡量了代码的规模。微调数据集的构建方式是,根据圈复杂度和逻辑代码行数将代码样本划分为不同的复杂度范围,然后选择特定范围内的代码样本作为微调数据。推理基准包括多种类型的推理任务,例如数学推理、逻辑推理和常识推理。
🖼️ 关键图片
📊 实验亮点
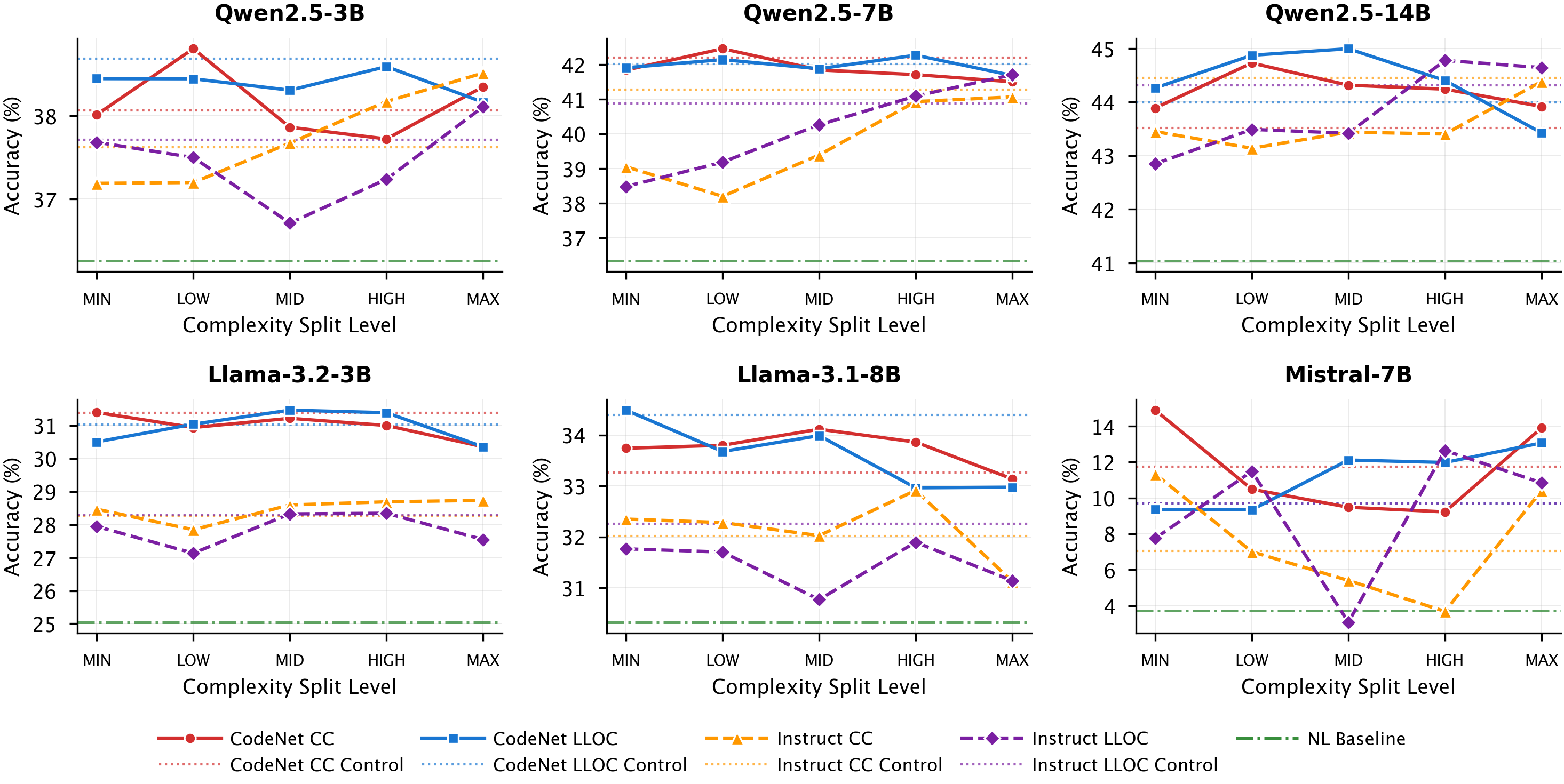
实验结果表明,在83%的实验中,使用特定结构复杂度范围的代码进行微调,优于使用结构多样化的代码进行微调。这表明代码的结构属性对LLM的推理能力有显著影响,并且通过数据中心的方法可以选择更有效的训练数据。具体的性能提升幅度取决于具体的推理基准和LLM模型。
🎯 应用场景
该研究成果可应用于提升LLM在软件开发、问题求解、智能问答等领域的推理能力。通过选择特定复杂度的代码进行训练,可以更有效地提高LLM的性能,降低训练成本。未来,该研究可以扩展到其他类型的代码属性,例如代码风格、代码注释等,以进一步优化LLM的训练过程。
📄 摘要(原文)
Large Language Models (LLMs) increasingly exhibit strong reasoning abilities, often attributed to their capacity to generate chain-of-thought-style intermediate reasoning. Recent work suggests that exposure to code can further enhance these skills, but existing studies largely treat code as a generic training signal, leaving open the question of which properties of code actually contribute to improved reasoning. To address this gap, we study the structural complexity of code, which captures control flow and compositional structure that may shape how models internalise multi-step reasoning during fine-tuning. We examine two complementary settings: solution-driven complexity, where complexity varies across multiple solutions to the same problem, and problem-driven complexity, where complexity reflects variation in the underlying tasks. Using cyclomatic complexity and logical lines of code to construct controlled fine-tuning datasets, we evaluate a range of open-weight LLMs on diverse reasoning benchmarks. Our findings show that although code can improve reasoning, structural properties strongly determine its usefulness. In 83% of experiments, restricting fine-tuning data to a specific structural complexity range outperforms training on structurally diverse code, pointing to a data-centric path for improving reasoning beyond scaling.