Visual Disentangled Diffusion Autoencoders: Scalable Counterfactual Generation for Foundation Models
作者: Sidney Bender, Marco Morik
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出视觉解耦扩散自编码器以解决基础模型的反事实生成问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 基础模型 反事实生成 解耦学习 扩散自编码器 机器学习 公平性 鲁棒性
📋 核心要点
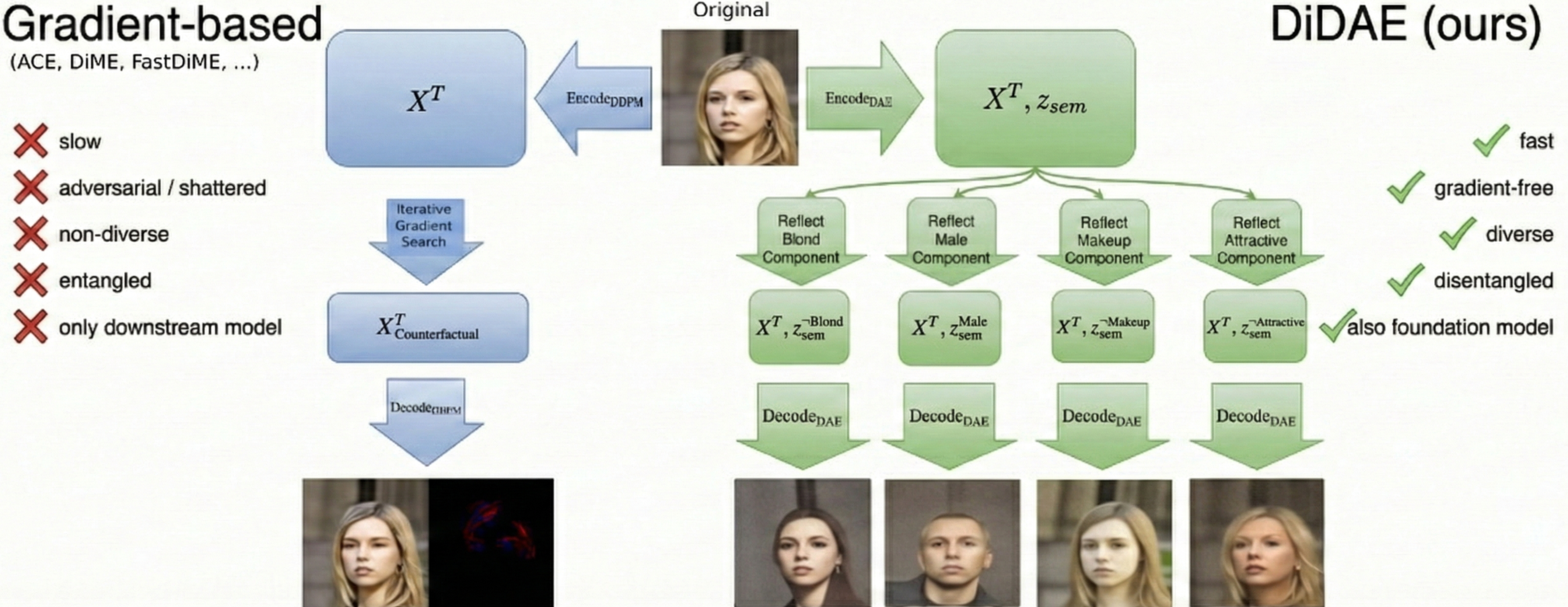
- 现有方法在缓解基础模型的虚假相关性时,往往依赖不可用的组标签或复杂的梯度优化,效率低下。
- 本文提出的DiDAE框架通过解耦字典学习,直接在基础模型上进行高效的反事实生成,避免了梯度计算。
- 实验结果表明,DiDAE-CFKD在缓解快捷学习方面表现优异,显著提升了在不平衡数据集上的下游任务性能。
📝 摘要(中文)
基础模型尽管具备强大的零样本能力,但仍然容易受到虚假相关性和“聪明汉斯”策略的影响。现有的缓解方法通常依赖于不可用的组标签或计算成本高昂的基于梯度的对抗优化。为了解决这些局限性,本文提出了视觉解耦扩散自编码器(DiDAE),这是一个将冻结的基础模型与解耦字典学习相结合的新框架,旨在高效、无梯度地为基础模型生成反事实。DiDAE首先在可解释的解耦方向上编辑基础模型的嵌入,然后通过扩散自编码器进行解码。这使得每个事实生成多个多样化的解耦反事实,速度远快于现有基线,后者仅生成单一的纠缠反事实。与反事实知识蒸馏结合时,DiDAE-CFKD在缓解快捷学习方面达到了最先进的性能,并改善了在不平衡数据集上的下游表现。
🔬 方法详解
问题定义:本文旨在解决基础模型在面对虚假相关性时的脆弱性,现有方法往往依赖于不可用的组标签或复杂的对抗优化,导致效率低下。
核心思路:提出的DiDAE框架通过解耦字典学习,直接在基础模型的嵌入上进行编辑,生成反事实,避免了梯度计算的复杂性。
技术框架:DiDAE的整体架构包括两个主要模块:解耦字典学习模块和扩散自编码器模块。首先,通过解耦字典对基础模型的嵌入进行编辑,然后使用扩散自编码器进行解码,生成多样化的反事实。
关键创新:DiDAE的核心创新在于将解耦字典学习与扩散自编码器相结合,实现了高效的反事实生成,显著提升了生成速度和多样性,与现有方法相比,避免了单一纠缠反事实的生成。
关键设计:在设计中,DiDAE采用了特定的损失函数以优化解耦效果,并在网络结构上进行了调整,以确保生成的反事实具有可解释性和多样性。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果显示,DiDAE-CFKD在缓解快捷学习方面达到了最先进的性能,相较于传统方法,生成速度提高了数倍,同时在不平衡数据集上的下游任务性能提升显著,具体数据在论文中提供。
🎯 应用场景
该研究的潜在应用领域包括机器学习模型的公平性和鲁棒性提升,尤其是在医疗、金融等对决策结果敏感的领域。通过有效生成反事实,DiDAE能够帮助模型更好地理解和消除虚假相关性,从而提高模型的实际应用价值和社会影响力。
📄 摘要(原文)
Foundation models, despite their robust zero-shot capabilities, remain vulnerable to spurious correlations and 'Clever Hans' strategies. Existing mitigation methods often rely on unavailable group labels or computationally expensive gradient-based adversarial optimization. To address these limitations, we propose Visual Disentangled Diffusion Autoencoders (DiDAE), a novel framework integrating frozen foundation models with disentangled dictionary learning for efficient, gradient-free counterfactual generation directly for the foundation model. DiDAE first edits foundation model embeddings in interpretable disentangled directions of the disentangled dictionary and then decodes them via a diffusion autoencoder. This allows the generation of multiple diverse, disentangled counterfactuals for each factual, much faster than existing baselines, which generate single entangled counterfactuals. When paired with Counterfactual Knowledge Distillation, DiDAE-CFKD achieves state-of-the-art performance in mitigating shortcut learning, improving downstream performance on unbalanced datasets.