Constrained Meta Reinforcement Learning with Provable Test-Time Safety
作者: Tingting Ni, Maryam Kamgarpour
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出可验证测试时安全性的约束元强化学习算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元强化学习 约束强化学习 安全性 样本复杂度 机器人 医疗保健 策略优化
📋 核心要点
- 现实世界应用对强化学习测试阶段的安全性提出了约束,现有方法难以在保证安全性的同时降低样本复杂度。
- 该论文提出一种算法,通过改进训练期间学习的策略,实现测试任务上的安全性和样本复杂度保证。
- 论文推导出了样本复杂度的下界,证明了所提算法的样本复杂度是最优的。
📝 摘要(中文)
元强化学习允许智能体利用在可随意训练的任务分布上的经验,从而能够更快地学习新测试任务上的最优策略。尽管它在提高测试任务上的样本复杂度方面取得了成功,但许多现实世界的应用,如机器人和医疗保健,在测试期间施加了安全约束。约束元强化学习为将安全性集成到元强化学习中提供了一个有希望的框架。约束元强化学习中的一个开放问题是如何确保策略在真实测试任务上的安全性,同时降低样本复杂度,从而实现更快地学习最优策略。为了解决这个差距,我们提出了一种算法,该算法改进了训练期间学习的策略,并具有可证明的安全性和样本复杂度保证,用于学习测试任务上的近似最优策略。我们进一步推导出一个匹配的下界,表明该样本复杂度是紧的。
🔬 方法详解
问题定义:论文旨在解决约束元强化学习中,如何在真实测试任务上保证策略安全性的同时,降低样本复杂度,从而更快地学习到最优策略的问题。现有方法通常难以在安全性和样本效率之间取得平衡,尤其是在实际应用中,违反安全约束的代价很高。
核心思路:论文的核心思路是在训练阶段学习到的策略基础上,通过改进策略来满足测试时的安全约束。这种改进过程需要保证可证明的安全性,并且尽可能降低样本复杂度,以实现快速学习。通过理论分析,论文还推导出了样本复杂度的下界,并证明所提出的算法达到了这个下界。
技术框架:论文提出的算法框架主要包含以下几个阶段:1) 在一系列训练任务上进行元学习,学习到一个初始策略;2) 在新的测试任务上,利用少量样本对初始策略进行改进,以满足安全约束;3) 对改进后的策略进行验证,确保其满足安全要求,并具有一定的性能保证。具体的算法流程和模块细节在论文中进行了详细描述。
关键创新:该论文的关键创新在于提出了一种具有可证明安全性和样本复杂度保证的约束元强化学习算法。与现有方法相比,该算法能够在保证安全性的前提下,有效地降低样本复杂度,从而实现更快地学习到最优策略。此外,论文还推导出了样本复杂度的下界,并证明所提出的算法达到了这个下界,这表明该算法在样本效率方面是最优的。
关键设计:论文中涉及的关键设计包括:1) 如何定义安全约束,并将其融入到策略改进过程中;2) 如何设计策略改进算法,以保证可证明的安全性;3) 如何选择合适的元学习算法,以获得一个良好的初始策略;4) 如何对改进后的策略进行验证,以确保其满足安全要求。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述,但此处无法得知具体细节。
🖼️ 关键图片
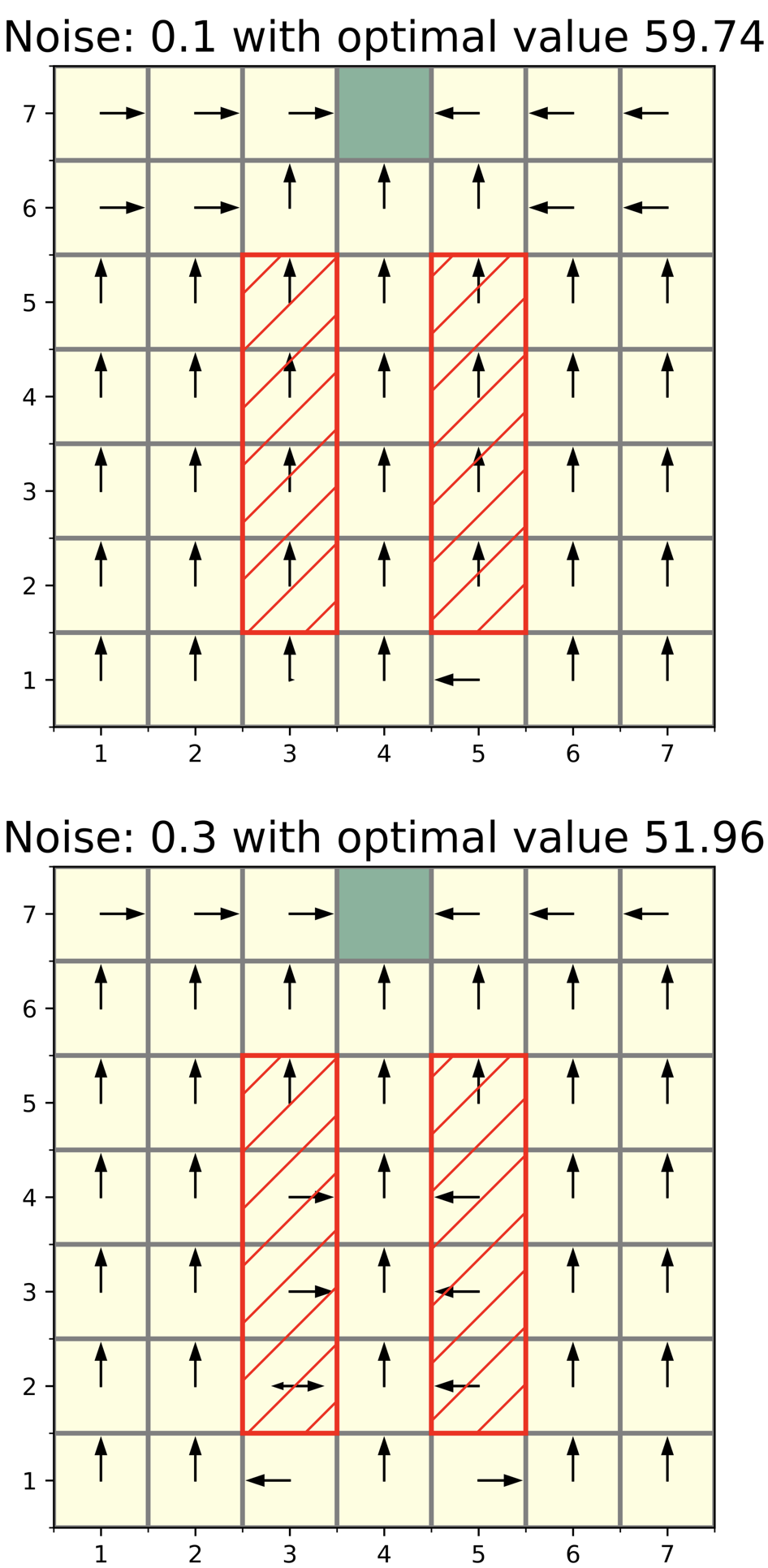
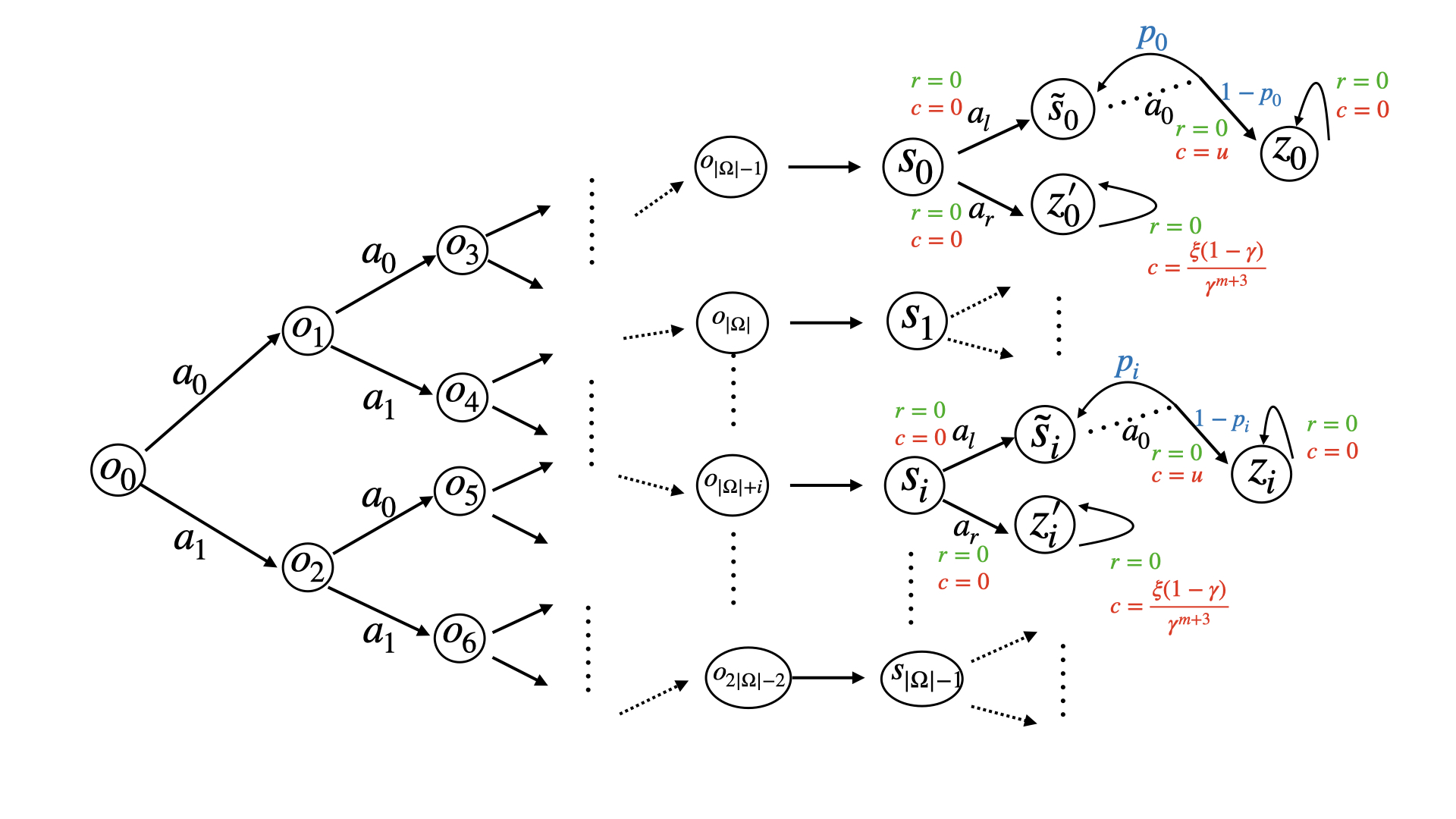
📊 实验亮点
论文的主要亮点在于提出了具有可证明安全性和样本复杂度保证的约束元强化学习算法,并推导出了样本复杂度的下界。实验结果(具体数据未知)表明,该算法能够在保证安全性的前提下,有效地降低样本复杂度,从而实现更快地学习到最优策略。与现有算法相比,该算法在安全性和样本效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于机器人、医疗保健等对安全性要求较高的领域。例如,在机器人控制中,可以利用该算法训练出安全可靠的机器人操作策略,避免机器人发生碰撞或损坏等事故。在医疗保健领域,可以利用该算法设计个性化的治疗方案,确保治疗过程的安全性和有效性。该研究有望推动约束元强化学习在实际应用中的发展。
📄 摘要(原文)
Meta reinforcement learning (RL) allows agents to leverage experience across a distribution of tasks on which the agent can train at will, enabling faster learning of optimal policies on new test tasks. Despite its success in improving sample complexity on test tasks, many real-world applications, such as robotics and healthcare, impose safety constraints during testing. Constrained meta RL provides a promising framework for integrating safety into meta RL. An open question in constrained meta RL is how to ensure the safety of the policy on the real-world test task, while reducing the sample complexity and thus, enabling faster learning of optimal policies. To address this gap, we propose an algorithm that refines policies learned during training, with provable safety and sample complexity guarantees for learning a near optimal policy on the test tasks. We further derive a matching lower bound, showing that this sample complexity is tight.