Nonparametric LLM Evaluation from Preference Data
作者: Dennis Frauen, Athiya Deviyani, Mihaela van der Schaar, Stefan Feuerriegel
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出DMLEval,一种基于偏好数据的非参数化LLM评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 偏好学习 非参数统计 去偏机器学习 排序算法
📋 核心要点
- 现有LLM评估方法依赖参数假设或缺乏不确定性量化,限制了其在复杂偏好数据下的有效性。
- DMLEval通过去偏机器学习和广义平均排序分数,提供非参数化的LLM排序和比较方法。
- 实验表明DMLEval在合成和真实数据集上均表现出优势,并能结合预训练LLM评估器。
📝 摘要(中文)
从人类偏好数据评估大型语言模型(LLM)的性能对于构建LLM排行榜至关重要。然而,许多现有方法要么依赖于严格的参数假设,要么在使用灵活的机器学习方法时缺乏有效的不确定性量化。本文提出了一种非参数统计框架DMLEval,用于使用去偏机器学习(DML)从偏好数据比较和排序LLM。为此,我们引入了广义平均排序分数(GARS),它推广了常用的排序模型,包括Bradley-Terry模型或PageRank/排序中心性,并能处理诸如平局等复杂的人类响应。DMLEval具有以下优点:(i)它产生GARS排序分数的统计有效估计。(ii)它自然地允许结合黑盒机器学习方法进行估计。(iii)它可以与预训练的LLM评估器(例如,使用LLM-as-a-judge)结合使用。(iv)它提出了在预算约束下收集偏好数据的最佳策略。我们通过合成和真实世界的偏好数据集在理论上和经验上证明了这些优点。总而言之,我们的框架为从业者提供了强大、最先进的方法来比较或排序LLM。
🔬 方法详解
问题定义:论文旨在解决如何更准确、更灵活地利用人类偏好数据评估和比较大型语言模型(LLM)的问题。现有方法的痛点在于,要么依赖于强参数假设(如Bradley-Terry模型),限制了模型的表达能力;要么在使用灵活的机器学习方法时,缺乏有效的不确定性量化,导致评估结果的可靠性降低。此外,如何有效地利用有限的预算收集偏好数据也是一个挑战。
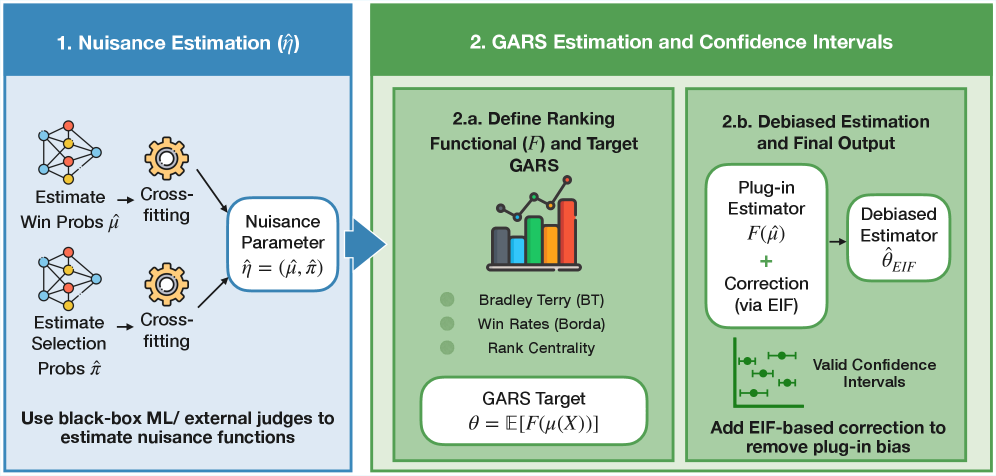
核心思路:论文的核心思路是采用非参数化的统计框架,结合去偏机器学习(DML)来估计LLM的排序分数。通过引入广义平均排序分数(GARS),该方法能够处理更复杂的偏好数据,例如平局。同时,DML的使用可以减少估计偏差,提高排序分数的准确性。此外,论文还提出了在预算约束下收集偏好数据的优化策略。
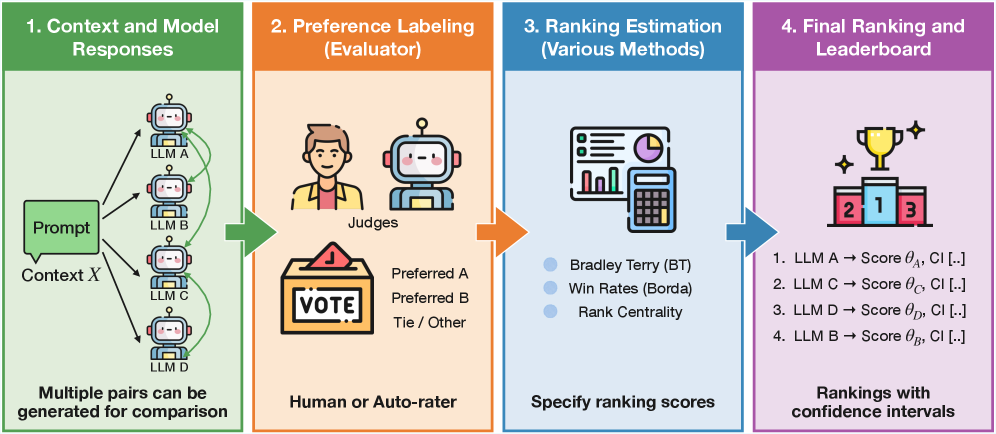
技术框架:DMLEval框架主要包含以下几个阶段:1) 数据收集:收集人类对不同LLM输出的偏好数据。2) 特征工程:提取与LLM输出相关的特征,可以利用预训练的LLM评估器(LLM-as-a-judge)。3) GARS估计:使用DML方法估计广义平均排序分数。4) 排序和比较:基于GARS对LLM进行排序和比较。5) 偏好数据收集策略优化:在预算约束下,优化偏好数据的收集策略,以最大化评估效果。
关键创新:论文的关键创新在于:1) 提出了非参数化的LLM评估框架DMLEval,避免了强参数假设的限制。2) 引入了广义平均排序分数(GARS),能够处理更复杂的偏好数据。3) 利用去偏机器学习(DML)减少估计偏差,提高排序分数的准确性。4) 提出了在预算约束下收集偏好数据的优化策略。
关键设计:GARS的设计允许灵活地结合各种排序模型,例如Bradley-Terry模型或PageRank。DML的实现依赖于将估计问题分解为多个子问题,并使用交叉拟合(cross-fitting)技术来减少偏差。偏好数据收集策略的优化则基于对信息增益的估计,并采用贪心算法或其他优化方法来选择最佳的样本对。
🖼️ 关键图片

📊 实验亮点
论文通过合成和真实世界的数据集验证了DMLEval的有效性。实验结果表明,DMLEval能够产生统计上更有效的排序分数估计,并且能够有效地结合预训练的LLM评估器。此外,论文还展示了DMLEval在预算约束下优化偏好数据收集策略的能力,从而在有限的资源下获得更好的评估效果。
🎯 应用场景
该研究成果可广泛应用于LLM的评估和选择,例如构建LLM排行榜、指导LLM的开发和改进、以及为用户推荐合适的LLM。此外,该方法还可以应用于其他需要基于偏好数据进行排序和比较的场景,例如推荐系统、信息检索等。未来,该研究可以进一步扩展到多模态LLM的评估,以及考虑更复杂的偏好模式。
📄 摘要(原文)
Evaluating the performance of large language models (LLMs) from human preference data is crucial for obtaining LLM leaderboards. However, many existing approaches either rely on restrictive parametric assumptions or lack valid uncertainty quantification when flexible machine learning methods are used. In this paper, we propose a nonparametric statistical framework, DMLEval, for comparing and ranking LLMs from preference data using debiased machine learning (DML). For this, we introduce generalized average ranking scores (GARS), which generalize commonly used ranking models, including the Bradley-Terry model or PageRank/ Rank centrality, with complex human responses such as ties. DMLEval comes with the following advantages: (i) It produces statistically efficient estimates of GARS ranking scores. (ii) It naturally allows the incorporation of black-box machine learning methods for estimation. (iii) It can be combined with pre-trained LLM evaluators (e.g., using LLM-as-a-judge). (iv) It suggests optimal policies for collecting preference data under budget constraints. We demonstrate these advantages both theoretically and empirically using both synthetic and real-world preference datasets. In summary, our framework provides practitioners with powerful, state-of-the-art methods for comparing or ranking LLMs.