Knowledge Vector Weakening: Efficient Training-free Unlearning for Large Vision-Language Models
作者: Yejin Kim, Dongjun Hwang, Sungmin Cha, Junsuk Choe
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出知识向量弱化(KVW),实现大型视觉-语言模型的免训练高效卸载学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 卸载学习 知识向量 免训练 隐私保护
📋 核心要点
- 现有LVLM卸载学习方法依赖梯度优化,计算成本高昂,难以应用于大规模模型。
- KVW通过直接干预模型内部的知识向量,无需梯度计算即可实现高效卸载学习。
- 实验表明,KVW在遗忘性能和保留性能之间取得了良好平衡,并显著提升了计算效率。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)因其强大的多模态能力而被广泛采用,但也引发了隐私泄露和有害内容生成等严重问题。机器卸载学习已成为一种有前景的解决方案,可以消除特定数据对已训练模型的影响。然而,现有方法主要依赖于基于梯度的优化,这给大型LVLMs带来了巨大的计算成本。为了解决这个限制,我们提出了一种免训练的卸载学习方法,即知识向量弱化(KVW),它直接干预整个模型,而无需梯度计算。KVW识别在模型对遗忘集生成输出期间激活的知识向量,并逐步削弱它们的贡献,从而防止模型利用不良知识。在MLLMU和CLEAR基准上的实验表明,KVW实现了稳定的遗忘-保留权衡,同时显著提高了计算效率,优于基于梯度和基于LoRA的卸载学习方法。
🔬 方法详解
问题定义:论文旨在解决大型视觉-语言模型(LVLMs)的卸载学习问题。现有基于梯度优化的卸载学习方法,如微调或LoRA,在处理大规模LVLMs时计算成本过高,难以实际应用。这些方法需要大量的计算资源和时间来更新模型参数,效率低下。
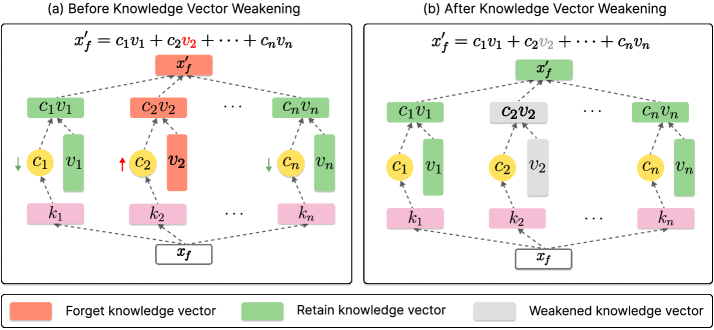
核心思路:论文的核心思路是直接干预模型内部的知识表示,即“知识向量”,而无需进行梯度计算。通过识别并弱化与需要遗忘的数据相关的知识向量,可以有效地消除模型对这些数据的记忆,从而实现卸载学习。这种方法避免了耗时的梯度计算过程,显著提高了卸载学习的效率。
技术框架:KVW方法的整体框架包括以下几个主要步骤:1) 知识向量识别:首先,使用遗忘数据集作为输入,运行LVLM模型,记录模型在生成输出过程中激活的知识向量。激活的知识向量被认为是与遗忘数据相关的。2) 知识向量弱化:然后,对识别出的知识向量进行弱化处理。具体来说,通过降低这些向量的幅度或将其置零,来减少它们对模型输出的影响。3) 模型评估:最后,评估卸载学习后的模型在遗忘数据集和保留数据集上的性能,以验证卸载学习的效果和对模型原有能力的保留程度。
关键创新:KVW方法最重要的创新点在于其免训练的特性。与传统的基于梯度优化的方法不同,KVW直接作用于模型的知识向量,无需进行任何参数更新或梯度计算。这使得KVW能够以极高的效率实现卸载学习,尤其适用于大规模LVLMs。此外,KVW通过选择性地弱化知识向量,避免了对整个模型的全局性修改,从而更好地保留了模型的原有能力。
关键设计:KVW的关键设计包括:1) 知识向量的定义:论文需要明确定义什么是“知识向量”,以及如何从LVLM中提取这些向量。这可能涉及到对模型内部结构的分析和选择。2) 知识向量弱化策略:论文需要设计一种有效的弱化策略,例如,通过设置阈值来选择性地降低知识向量的幅度,或者使用某种正则化方法来约束知识向量的更新。3) 激活函数的选择:激活函数的选择会影响知识向量的激活程度,进而影响KVW的卸载效果。论文可能需要探索不同的激活函数,以找到最适合KVW的配置。
🖼️ 关键图片
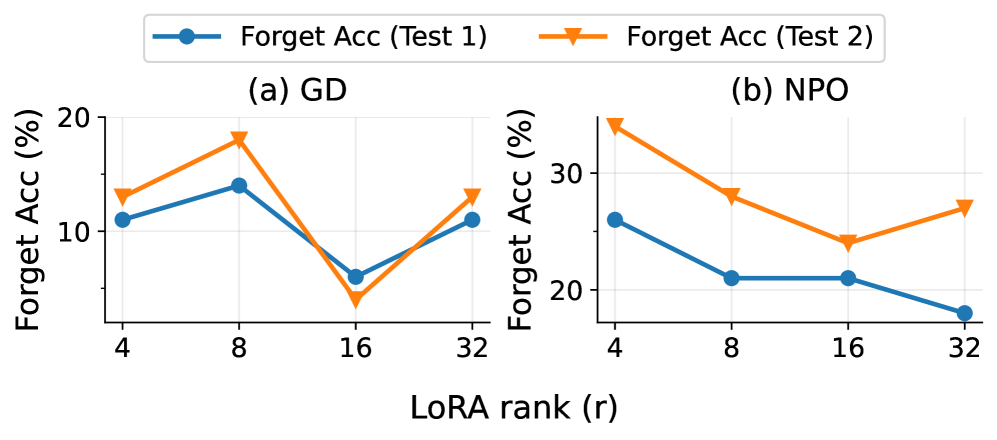

📊 实验亮点
实验结果表明,KVW在MLLMU和CLEAR基准测试中,相较于基于梯度和基于LoRA的卸载学习方法,在计算效率上实现了显著提升,同时保持了可比的遗忘性能和保留性能。具体数据未知,但摘要强调了KVW在计算效率上的优势。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私或消除有害信息的大型视觉-语言模型。例如,在医疗影像分析、自动驾驶、智能客服等领域,可以利用该方法快速移除模型中与特定患者、事故或敏感话题相关的信息,从而避免隐私泄露和不当行为。此外,该方法还可以用于模型的持续学习和知识更新,及时删除过时或错误的信息。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) are widely adopted for their strong multimodal capabilities, yet they raise serious concerns such as privacy leakage and harmful content generation. Machine unlearning has emerged as a promising solution for removing the influence of specific data from trained models. However, existing approaches largely rely on gradient-based optimization, incurring substantial computational costs for large-scale LVLMs. To address this limitation, we propose Knowledge Vector Weakening (KVW), a training-free unlearning method that directly intervenes in the full model without gradient computation. KVW identifies knowledge vectors that are activated during the model's output generation on the forget set and progressively weakens their contributions, thereby preventing the model from exploiting undesirable knowledge. Experiments on the MLLMU and CLEAR benchmarks demonstrate that KVW achieves a stable forget-retain trade-off while significantly improving computational efficiency over gradient-based and LoRA-based unlearning methods.