When does predictive inverse dynamics outperform behavior cloning?
作者: Lukas Schäfer, Pallavi Choudhury, Abdelhak Lemkhenter, Chris Lovett, Somjit Nath, Luis França, Matheus Ribeiro Furtado de Mendonça, Alex Lamb, Riashat Islam, Siddhartha Sen, John Langford, Katja Hofmann, Sergio Valcarcel Macua
分类: cs.LG, cs.AI
发布日期: 2026-01-29
备注: Preprint
💡 一句话要点
提出预测逆动力学模型,在模仿学习中实现更优的偏差-方差权衡
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 行为克隆 逆动力学模型 偏差-方差权衡 状态预测
📋 核心要点
- 行为克隆在数据有限时表现不佳,需要探索更有效的模仿学习方法。
- PIDM通过预测未来状态并以此为基础进行逆动力学建模,实现了偏差-方差的有效权衡。
- 实验表明,PIDM在样本效率上显著优于行为克隆,尤其是在复杂环境中。
📝 摘要(中文)
行为克隆(BC)是一种实用的离线模仿学习方法,但当专家演示数据有限时,其性能往往不佳。最近的研究引入了一类名为预测逆动力学模型(PIDM)的架构,该架构结合了未来状态预测器和逆动力学模型(IDM)。虽然PIDM通常优于BC,但其优势背后的原因尚不清楚。本文提供了一个理论解释:PIDM引入了偏差-方差权衡。虽然预测未来状态会引入偏差,但将IDM建立在预测的基础上可以显著降低方差。我们建立了PIDM实现比BC更低的预测误差和更高的样本效率的状态预测器偏差条件,并且当有额外的数据源可用时,差距会扩大。我们在2D导航任务中验证了理论见解,其中BC需要比PIDM多五倍(平均三倍)的演示才能达到相当的性能;在一个具有高维视觉输入和随机转换的现代视频游戏中,BC需要比PIDM多66%以上的样本。
🔬 方法详解
问题定义:行为克隆(BC)在模仿学习中是一种常用的方法,但当专家演示数据量不足时,其泛化能力会受到限制,导致性能下降。现有的BC方法难以充分利用有限的数据,并且容易受到数据分布偏移的影响。
核心思路:本文的核心思路是利用预测逆动力学模型(PIDM)来改善模仿学习的样本效率。PIDM通过引入未来状态预测器,并将其预测结果作为逆动力学模型的输入,从而在偏差和方差之间进行权衡。预测器引入了偏差,但同时也降低了逆动力学模型的方差,使得模型能够更好地泛化到未见过的数据。
技术框架:PIDM的整体框架包含两个主要模块:未来状态预测器和逆动力学模型。未来状态预测器接收当前状态和动作作为输入,预测未来的状态。逆动力学模型接收当前状态和预测的未来状态作为输入,预测执行的动作。整个流程可以看作是利用预测信息来约束逆动力学模型的学习,从而提高模型的稳定性和泛化能力。
关键创新:PIDM的关键创新在于将未来状态预测与逆动力学建模相结合,从而在模仿学习中实现了更优的偏差-方差权衡。与传统的行为克隆方法相比,PIDM能够更好地利用数据中的信息,并且对数据分布偏移具有更强的鲁棒性。此外,该论文还从理论上分析了PIDM的优势,并给出了PIDM优于BC的条件。
关键设计:PIDM的关键设计包括未来状态预测器的选择、逆动力学模型的结构以及损失函数的设计。未来状态预测器可以使用各种模型,例如神经网络或高斯过程。逆动力学模型通常使用神经网络,其输入是当前状态和预测的未来状态,输出是预测的动作。损失函数通常包括预测状态的误差和预测动作的误差。论文中具体使用的网络结构和损失函数细节未知。
🖼️ 关键图片

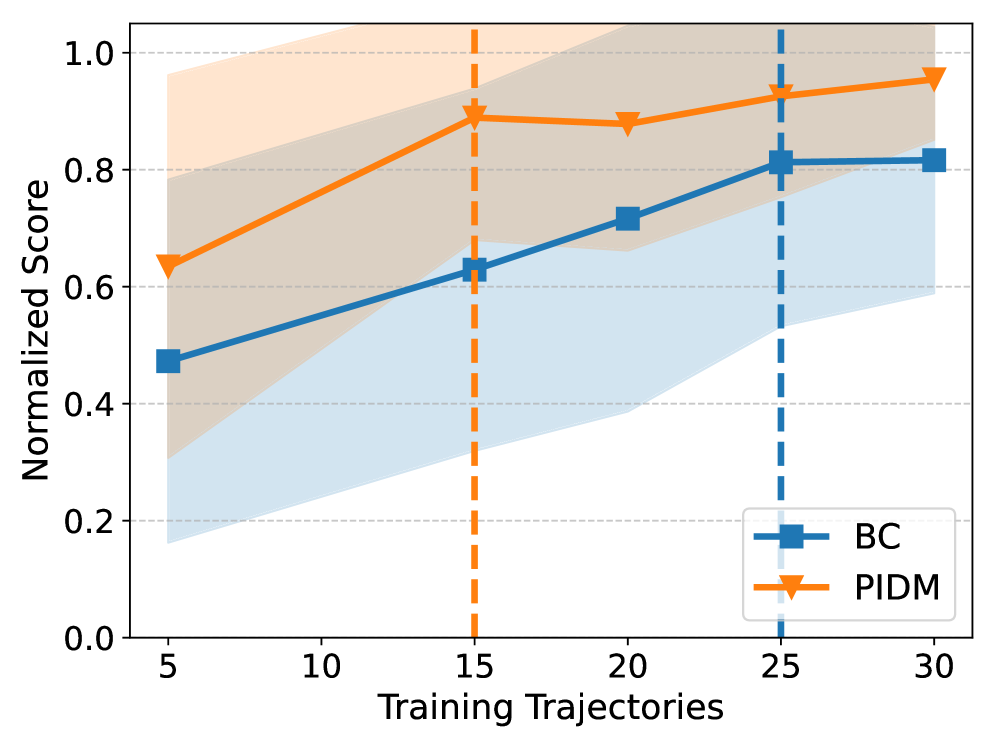

📊 实验亮点
实验结果表明,在2D导航任务中,PIDM达到与BC相当的性能所需的演示数据量平均少三倍,最多少五倍。在复杂的3D视频游戏环境中,PIDM所需的样本量比BC少66%以上。这些结果验证了PIDM在样本效率方面的优势,尤其是在高维、随机环境中。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过模仿学习,智能体可以从人类或其他专家的演示数据中学习复杂的行为策略,从而实现自主导航、物体操作等任务。PIDM的优势在于其更高的样本效率,这意味着在数据有限的情况下,智能体也能学习到高质量的策略。未来,该方法有望在更多实际场景中得到应用,例如在医疗机器人、工业自动化等领域。
📄 摘要(原文)
Behavior cloning (BC) is a practical offline imitation learning method, but it often fails when expert demonstrations are limited. Recent works have introduced a class of architectures named predictive inverse dynamics models (PIDM) that combine a future state predictor with an inverse dynamics model (IDM). While PIDM often outperforms BC, the reasons behind its benefits remain unclear. In this paper, we provide a theoretical explanation: PIDM introduces a bias-variance tradeoff. While predicting the future state introduces bias, conditioning the IDM on the prediction can significantly reduce variance. We establish conditions on the state predictor bias for PIDM to achieve lower prediction error and higher sample efficiency than BC, with the gap widening when additional data sources are available. We validate the theoretical insights empirically in 2D navigation tasks, where BC requires up to five times (three times on average) more demonstrations than PIDM to reach comparable performance; and in a complex 3D environment in a modern video game with high-dimensional visual inputs and stochastic transitions, where BC requires over 66\% more samples than PIDM.