Curriculum Learning for LLM Pretraining: An Analysis of Learning Dynamics
作者: Mohamed Elgaar, Hadi Amiri
分类: cs.LG, cs.AI
发布日期: 2026-01-29
💡 一句话要点
课程学习提升LLM预训练稳定性,通过控制梯度方差优化模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 课程学习 大型语言模型 预训练 梯度方差 优化稳定性 语言学特征 Pythia模型
📋 核心要点
- 现有研究对课程学习是否改变LLM的学习轨迹,还是仅重新排序数据暴露存在争议。
- 论文核心思想是通过语言学驱动的课程学习,控制梯度方差,从而稳定LLM预训练过程。
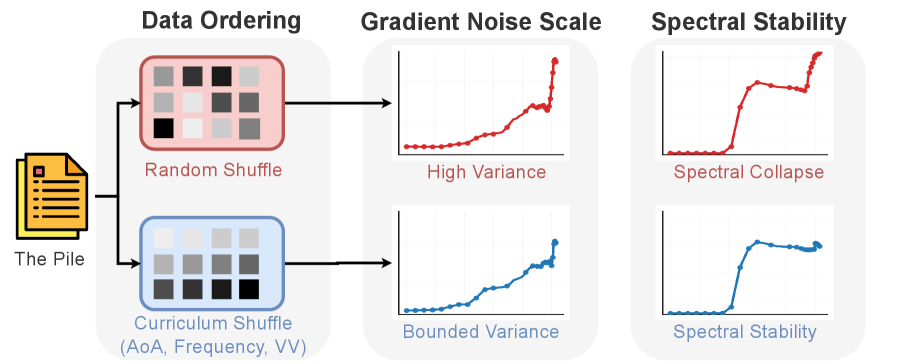
- 实验表明,课程学习能降低梯度噪声和谱饱和,提升小模型的准确率,但大模型增益减小。
📝 摘要(中文)
本研究探讨了课程学习(Curriculum Learning)对大型语言模型(LLM)预训练的影响。通过在Pythia模型(14M-410M参数)上进行300B tokens的训练,并采用三种语言学驱动的课程——年龄习得(Age-of-Acquisition)、词频和动词变体(Verb Variation,VV),与随机排序进行比较。结果表明,不同排序方式下,训练过程遵循相似的潜在阶段序列,而课程学习主要改变了各阶段内的数据暴露。在较小模型中(最高160M参数),随机排序表现出更高的梯度噪声和更强的后期训练输出头谱饱和,以及较低的最终准确率;课程学习在相同计算量下减少了这些影响。在更大规模的模型中,饱和度差异较小,课程学习的增益也随之减小。论文通过基于梯度方差控制的理想化分析,形式化了难度调整与优化稳定性之间的联系,并得出结论:课程学习通过稳定阶段内优化来提供帮助,而不是创建新的阶段。
🔬 方法详解
问题定义:现有的大型语言模型预训练方法通常采用随机数据排序,这可能导致训练不稳定,尤其是在模型规模较小的情况下。现有方法缺乏对数据难度的有效控制,可能导致梯度噪声过大和输出头谱饱和等问题,最终影响模型的性能。
核心思路:论文的核心思路是通过引入课程学习,按照数据的难度进行排序,从而控制训练过程中的梯度方差,提高优化稳定性。通过从易到难地呈现数据,模型可以更有效地学习,避免陷入局部最优解。这种方法旨在稳定模型在每个训练阶段的学习过程,而不是简单地改变学习轨迹。
技术框架:研究采用Pythia模型(14M-410M参数)作为实验对象,并在300B tokens上进行预训练。实验比较了三种语言学驱动的课程学习策略:年龄习得(Age-of-Acquisition)、词频和动词变体(Verb Variation,VV),并与随机排序进行对比。通过监控训练过程中的梯度噪声、输出头谱饱和度和最终准确率等指标,评估不同排序策略的效果。
关键创新:论文的关键创新在于将课程学习与梯度方差控制联系起来,并形式化了难度调整与优化稳定性之间的关系。通过理论分析和实验验证,证明了课程学习可以通过稳定阶段内优化来提高模型性能,而不是通过创建新的学习阶段。
关键设计:实验中,年龄习得课程按照词汇的习得年龄排序,词频课程按照词汇的出现频率排序,动词变体课程按照动词的复杂程度排序。梯度噪声通过计算梯度方差来衡量,输出头谱饱和度通过分析输出层权重的奇异值分解来评估。最终准确率通过在下游任务上的评估来衡量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在较小模型(最高160M参数)中,随机排序表现出更高的梯度噪声和更强的后期训练输出头谱饱和,以及较低的最终准确率;而课程学习在相同计算量下减少了这些影响。例如,使用动词变体课程学习的模型在准确率上相比随机排序的模型有显著提升。虽然在大规模模型中,课程学习的增益有所减小,但仍然能够观察到优化稳定性的提升。
🎯 应用场景
该研究成果可应用于大型语言模型的预训练阶段,通过设计合理的课程学习策略,提高模型的训练效率和稳定性。这对于资源受限的场景,如小规模模型训练或低算力设备上的模型微调,具有重要意义。此外,该研究也为理解课程学习在深度学习中的作用提供了理论基础。
📄 摘要(原文)
Curriculum learning changes the order of pre-training data, but it remains unclear whether it changes the learning trajectory or mainly reorders exposure over a fixed trajectory. We train Pythia models (14M-410M parameters) for 300B tokens under three linguistically motivated curricula-Age-of-Acquisition, word frequency, and Verb Variation (VV)-and compare each against Random ordering; at 1B parameters we compare Random and VV. Across orderings, training follows a shared sequence of latent phases, while curricula mainly change within-phase data exposure. In smaller models (up to 160M parameters), Random ordering exhibits higher gradient noise and stronger late-training output-head spectral saturation, alongside lower final accuracy; curricula reduce both effects at matched compute. At larger scales, saturation differences are smaller and curriculum gains shrink. We formalize the link between difficulty pacing and optimization stability in an idealized analysis based on gradient-variance control, and our results point to a practical takeaway: curricula help by stabilizing within-phase optimization rather than by creating new phases.