Expected Return Causes Outcome-Level Mode Collapse in Reinforcement Learning and How to Fix It with Inverse Probability Scaling
作者: Abhijeet Sinha, Sundari Elango, Dianbo Liu
分类: cs.LG, cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出逆概率缩放的GRPO算法,解决强化学习中期望回报导致的模式崩塌问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 模式崩塌 逆概率缩放 策略优化 多模态学习
📋 核心要点
- 现有强化学习方法在多解问题中易发生模式崩塌,无法有效探索和表示多样化的优质解。
- 论文提出逆概率缩放方法,通过消除结果频率放大,改变学习动态,避免模式崩塌。
- 实验表明,IPS-GRPO在推理和分子生成任务中,能有效减少模式崩塌,并保持或提升性能。
📝 摘要(中文)
许多强化学习(RL)问题允许多个质量相当的终态解,目标不是识别单一最优解,而是表示一组多样化的高质量结果。然而,通过标准期望回报最大化训练的策略通常会崩塌到一小部分结果上,这种现象通常归因于探索不足或正则化较弱。本文表明,这种解释是不完整的:结果层面的模式崩塌是期望回报目标本身的一种结构性结果。在理想化的学习动态下,任意两个结果之间的对数概率比与其奖励差异呈线性关系,这意味着指数比率发散和不可避免的崩塌,这与探索策略、熵正则化或优化算法无关。本文将这种病态的根源确定为期望中的概率乘数,并提出了一个最小的修正:逆概率缩放,它消除了学习信号中的结果频率放大,从根本上改变了学习动态,并可证明地产生与奖励成比例的终端分布,从而防止多模态设置中的崩塌。本文在Group Relative Policy Optimization (GRPO)中实例化了这一原则,作为一种直接修改,IPS-GRPO,不需要辅助模型或架构更改。在不同的推理和分子生成任务中,IPS-GRPO始终减少了结果层面的模式崩塌,同时匹配或超过了基线性能,这表明纠正目标而不是添加探索启发式方法是可靠的多模态策略优化的关键。
🔬 方法详解
问题定义:在强化学习中,当存在多个质量相当的终态解时,标准期望回报最大化方法倾向于收敛到少数几个解,导致模式崩塌。现有的解释侧重于探索不足或正则化不足,但论文指出这是期望回报目标函数本身的结构性问题。
核心思路:核心思路是使用逆概率缩放(Inverse Probability Scaling, IPS)来修正期望回报目标函数。通过消除学习信号中结果频率的放大效应,使得策略更新不再过度偏向于已经频繁出现的结果,从而鼓励探索更多不同的高质量解。
技术框架:论文将IPS方法集成到Group Relative Policy Optimization (GRPO)框架中,提出了IPS-GRPO算法。GRPO本身是一种策略优化算法,IPS-GRPO通过修改GRPO的目标函数来实现逆概率缩放。整体流程与GRPO类似,但目标函数的计算方式有所不同。
关键创新:关键创新在于识别出期望回报目标函数是导致模式崩塌的根本原因,并提出了逆概率缩放作为一种有效的修正方法。与传统的探索策略或正则化方法不同,IPS直接修改了学习目标,从根本上改变了学习动态。
关键设计:IPS-GRPO的关键设计在于目标函数的修改。具体来说,原始GRPO的目标函数是期望回报,而IPS-GRPO的目标函数是经过逆概率缩放后的回报。这意味着在计算梯度时,每个结果的贡献会除以其出现的概率,从而降低了频繁出现结果的影响。具体实现上,IPS-GRPO作为GRPO的即插即用模块,无需修改网络结构或引入额外的模型。
🖼️ 关键图片

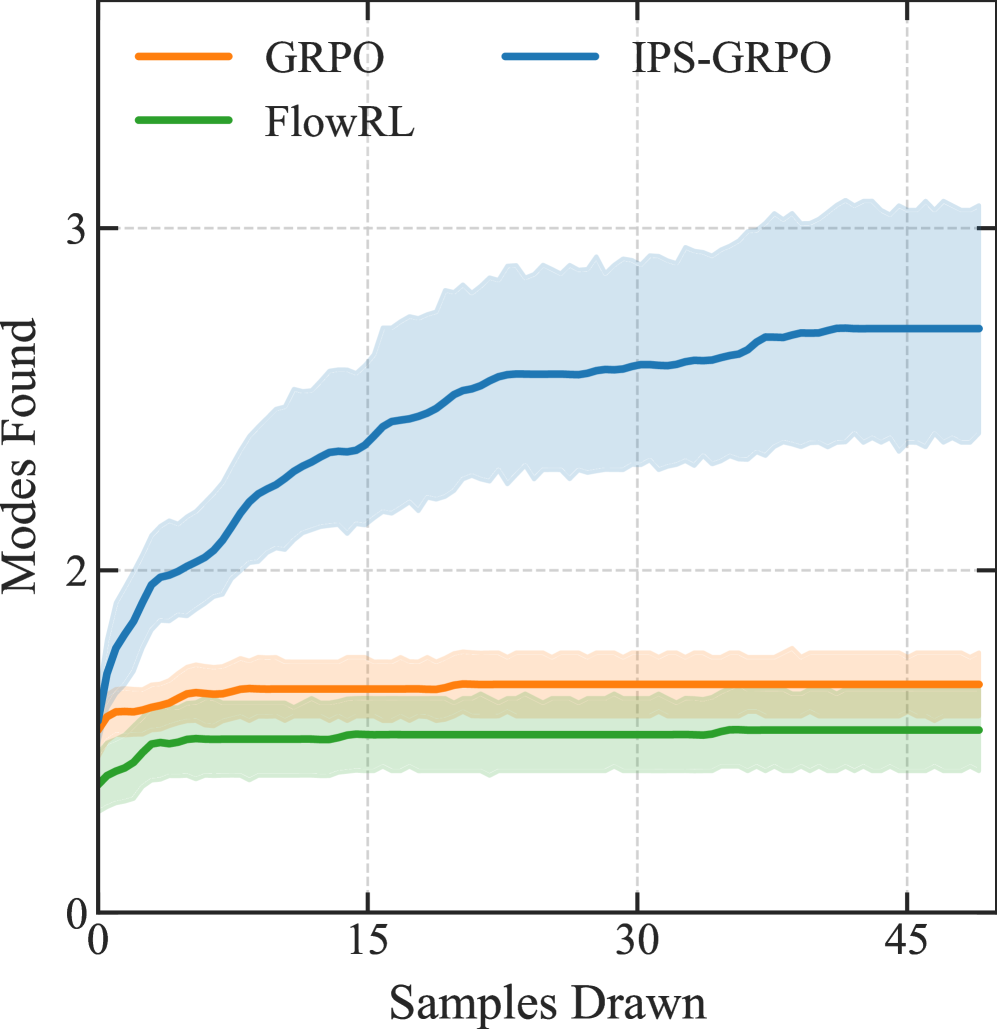
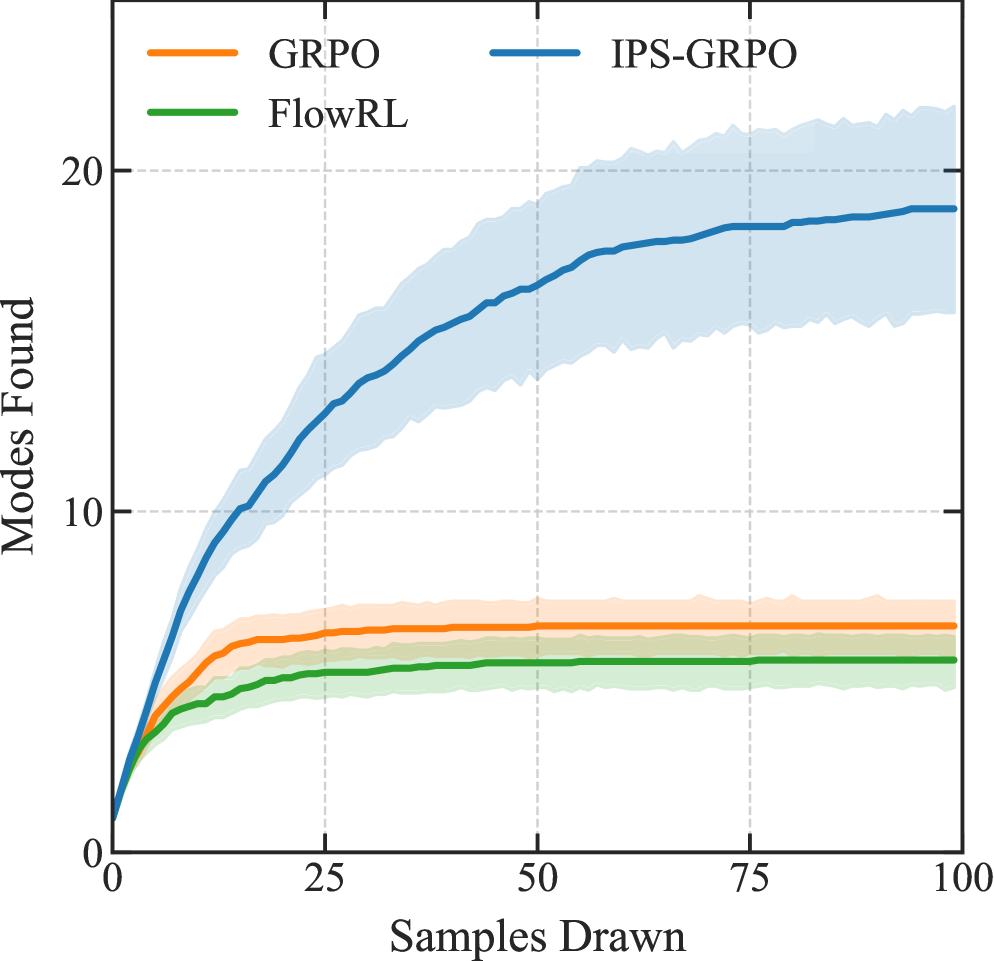
📊 实验亮点
实验结果表明,IPS-GRPO在不同的推理和分子生成任务中,能够显著减少结果层面的模式崩塌,同时保持或超过基线GRPO的性能。这验证了逆概率缩放方法的有效性,并表明纠正目标函数比添加探索启发式方法更有效。
🎯 应用场景
该研究成果可应用于需要生成多样化高质量结果的强化学习任务,例如分子生成、机器人运动规划、对话生成等。通过避免模式崩塌,可以提高生成结果的多样性和质量,从而在药物发现、自动化控制和人机交互等领域发挥重要作用。未来的研究可以探索将IPS方法应用于其他强化学习算法和更复杂的任务。
📄 摘要(原文)
Many reinforcement learning (RL) problems admit multiple terminal solutions of comparable quality, where the goal is not to identify a single optimum but to represent a diverse set of high-quality outcomes. Nevertheless, policies trained by standard expected return maximization routinely collapse onto a small subset of outcomes, a phenomenon commonly attributed to insufficient exploration or weak regularization. We show that this explanation is incomplete: outcome level mode collapse is a structural consequence of the expected-return objective itself. Under idealized learning dynamics, the log-probability ratio between any two outcomes evolves linearly in their reward difference, implying exponential ratio divergence and inevitable collapse independent of the exploration strategy, entropy regularization, or optimization algorithm. We identify the source of this pathology as the probability multiplier inside the expectation and propose a minimal correction: inverse probability scaling, which removes outcome-frequency amplification from the learning signal, fundamentally changes the learning dynamics, and provably yields reward-proportional terminal distributions, preventing collapse in multimodal settings. We instantiate this principle in Group Relative Policy Optimization (GRPO) as a drop-in modification, IPS-GRPO, requiring no auxiliary models or architectural changes. Across different reasoning and molecular generation tasks, IPS-GRPO consistently reduces outcome-level mode collapse while matching or exceeding baseline performance, suggesting that correcting the objective rather than adding exploration heuristics is key to reliable multimodal policy optimization.