Epistemic Uncertainty Quantification for Pre-trained VLMs via Riemannian Flow Matching
作者: Li Ju, Mayank Nautiyal, Andreas Hellander, Ekta Vats, Prashant Singh
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
提出REPVLM,通过黎曼流匹配量化预训练VLM的认知不确定性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 认知不确定性 视觉-语言模型 黎曼流匹配 分布外检测 数据管理
📋 核心要点
- 现有VLM模型缺乏量化认知不确定性的能力,无法有效反映模型对自身知识的掌握程度。
- REPVLM方法利用黎曼流匹配,计算VLM嵌入在超球面流形上的概率密度,以此作为认知不确定性的度量。
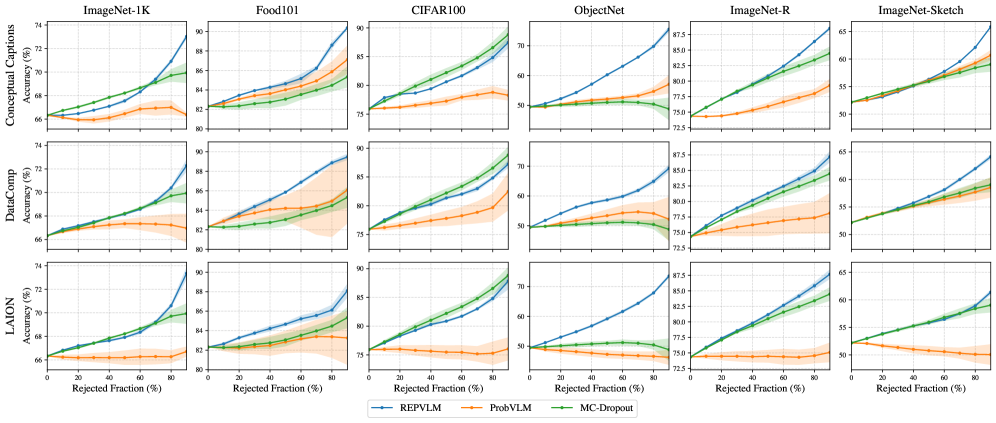
- 实验表明,REPVLM在不确定性预测、分布外检测和数据管理方面均优于现有方法,具有显著优势。
📝 摘要(中文)
视觉-语言模型(VLM)本质上通常是确定性的,缺乏量化认知不确定性的内在机制,而认知不确定性反映了模型知识的缺乏或对其自身表征的无知。本文从理论上论证了嵌入的负对数密度可以作为认知不确定性的代理,其中低密度区域表示模型的无知。所提出的方法REPVLM使用黎曼流匹配计算VLM嵌入的超球面流形上的概率密度。实验结果表明,REPVLM在不确定性和预测误差之间实现了近乎完美的关联,显著优于现有的基线方法。除了分类之外,该模型还为分布外检测和自动数据管理提供了一种可扩展的度量。
🔬 方法详解
问题定义:VLM模型通常是确定性的,无法有效量化认知不确定性。认知不确定性反映了模型对自身知识的掌握程度,在实际应用中至关重要。现有方法难以准确评估VLM的认知不确定性,限制了其在安全敏感场景中的应用。
核心思路:论文的核心思路是将VLM嵌入的负对数密度作为认知不确定性的代理。低密度区域表示模型对该区域的知识匮乏,因此可以作为不确定性的指标。通过计算嵌入的概率密度,可以量化模型的不确定性。
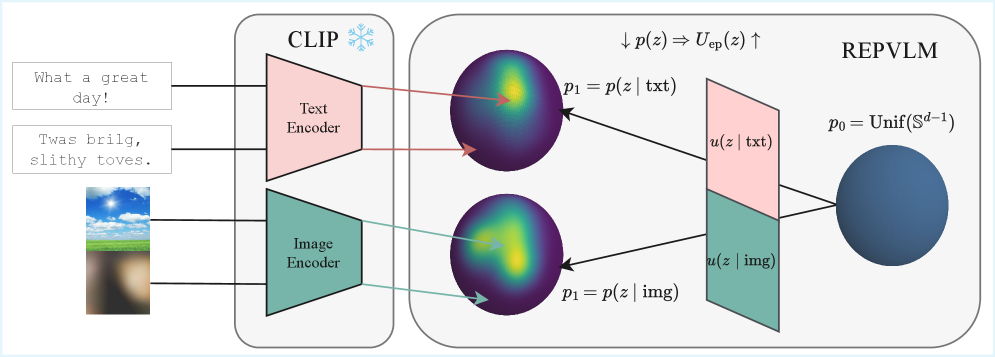
技术框架:REPVLM方法主要包含以下几个阶段:1) 使用预训练VLM提取视觉和语言特征,得到嵌入表示。2) 将嵌入表示映射到超球面流形上。3) 使用黎曼流匹配(Riemannian Flow Matching)学习超球面流形上的概率密度函数。4) 使用负对数密度作为认知不确定性的度量。
关键创新:该方法最重要的创新点在于使用黎曼流匹配来估计VLM嵌入在超球面流形上的概率密度。与传统方法相比,黎曼流匹配能够更好地处理高维流形数据,并能更准确地估计概率密度。此外,将负对数密度作为认知不确定性的代理也是一个重要的创新。
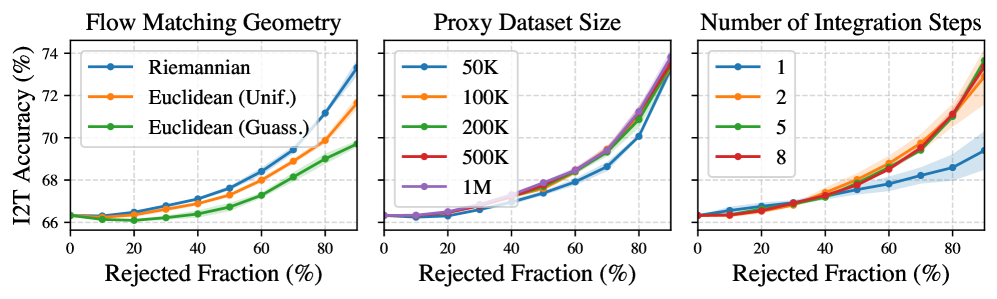
关键设计:REPVLM的关键设计包括:1) 使用预训练的CLIP模型作为VLM。2) 使用球面归一化将嵌入映射到超球面流形上。3) 使用连续归一化流(Continuous Normalizing Flows, CNF)实现黎曼流匹配。4) 使用蒙特卡洛方法估计概率密度。具体参数设置和损失函数细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,REPVLM在不确定性和预测误差之间实现了近乎完美的关联,显著优于现有的基线方法。此外,REPVLM在分布外检测和自动数据管理方面也表现出优异的性能,证明了该方法的有效性和泛化能力。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于多种场景,例如:自动驾驶系统中,可以利用不确定性估计来识别模型不确定的场景,从而避免潜在的危险;在医疗诊断中,可以帮助医生判断模型预测的可靠性,辅助决策;在金融风控中,可以识别模型不确定的交易,降低风险。此外,该方法还可以用于自动数据管理,筛选高质量数据,提升模型性能。
📄 摘要(原文)
Vision-Language Models (VLMs) are typically deterministic in nature and lack intrinsic mechanisms to quantify epistemic uncertainty, which reflects the model's lack of knowledge or ignorance of its own representations. We theoretically motivate negative log-density of an embedding as a proxy for the epistemic uncertainty, where low-density regions signify model ignorance. The proposed method REPVLM computes the probability density on the hyperspherical manifold of the VLM embeddings using Riemannian Flow Matching. We empirically demonstrate that REPVLM achieves near-perfect correlation between uncertainty and prediction error, significantly outperforming existing baselines. Beyond classification, we also demonstrate that the model also provides a scalable metric for out-of-distribution detection and automated data curation.