LAMP: Look-Ahead Mixed-Precision Inference of Large Language Models
作者: Stanislav Budzinskiy, Marian Gloser, Tolunay Yilmaz, Ying Hong Tham, Yuanyi Lin, Wenyi Fang, Fan Wu, Philipp Petersen
分类: cs.LG, math.NA
发布日期: 2026-01-29
💡 一句话要点
LAMP:面向大语言模型的Look-Ahead混合精度推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合精度 大语言模型 Transformer 推理优化 误差分析
📋 核心要点
- 现有大语言模型推理计算量大,部署困难,混合精度计算是降低计算复杂度的有效手段,但精度损失难以控制。
- 论文提出Look-Ahead混合精度(LAMP)策略,通过误差分析自适应地选择部分组件进行高精度计算,平衡精度与效率。
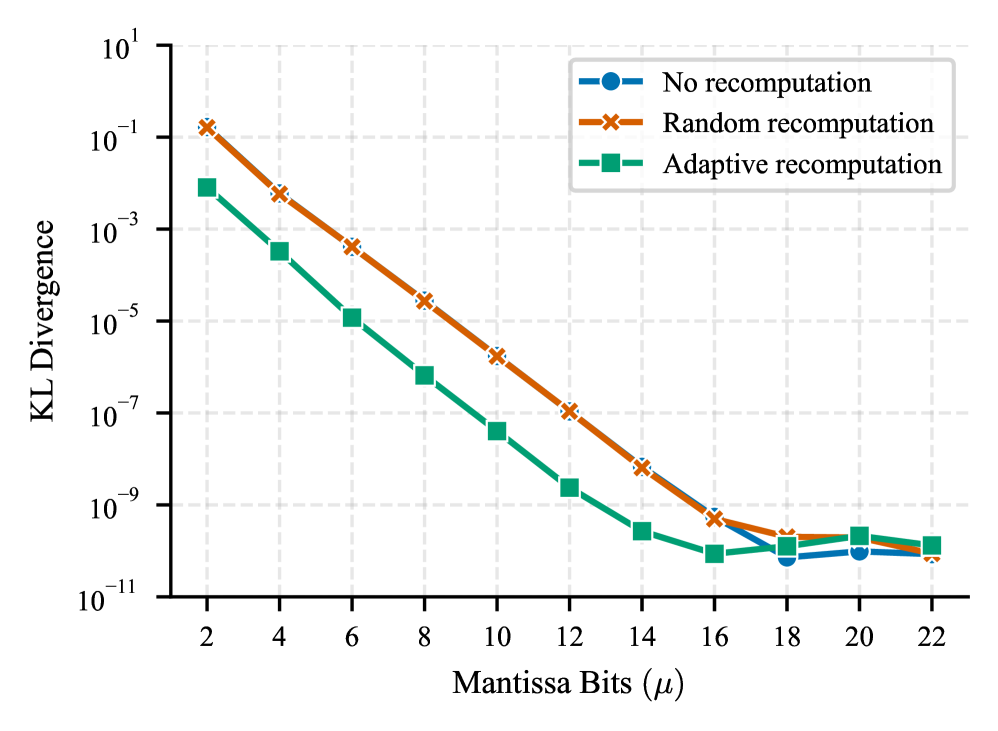
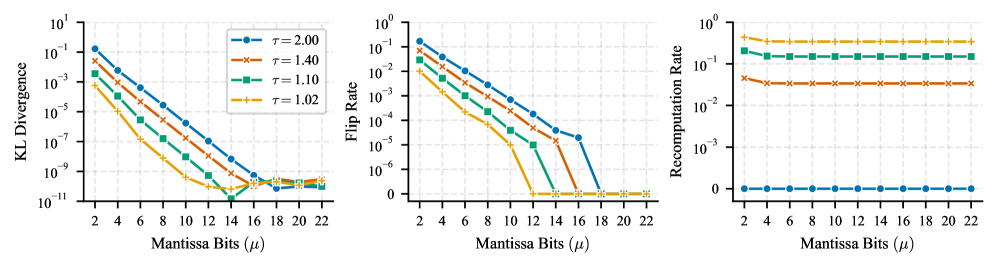
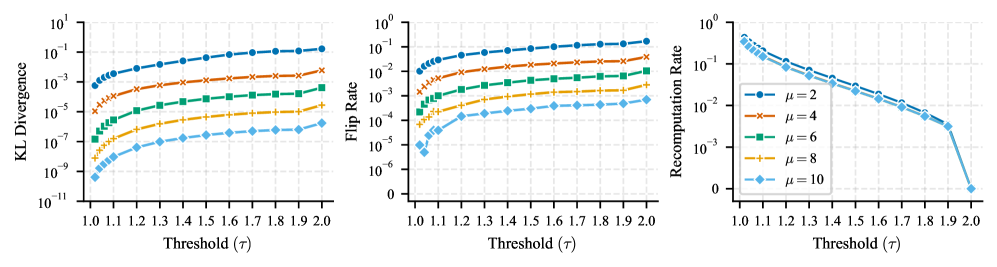
- 在GPT-2模型上的实验表明,极低的重计算率即可实现高达两个数量级的精度提升,验证了该方法的有效性。
📝 摘要(中文)
混合精度计算是当前人工智能发展的重要标志,它推动着大型语言模型朝着高效、本地可部署的解决方案发展。本文着重研究组合丰富的函数的浮点计算,特别是Transformer的推理过程。基于函数组合f(g(x))的舍入误差分析,我们提出了一种自适应策略,该策略选择g(x)的一小部分组件进行更精确的计算,而所有其他计算都可以以较低的精度执行。然后,我们解释了如何将此策略应用于Transformer中的不同组合,并说明其对Transformer推理的总体影响。我们通过GPT-2模型在数值上研究了该算法的有效性,并证明即使是非常低的重计算率也能使精度提高多达两个数量级。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理过程中计算量大、效率低的问题。现有方法,如直接采用低精度计算,虽然能加速推理,但会显著降低模型精度。如何在保证精度的前提下,尽可能地降低计算复杂度,是本文要解决的核心问题。
核心思路:论文的核心思路是基于对函数组合的舍入误差分析,提出一种自适应的混合精度计算策略。该策略并非对所有计算都采用低精度,而是有选择性地对部分计算采用高精度,从而在精度和效率之间取得平衡。关键在于如何选择需要高精度计算的部分。
技术框架:LAMP方法的整体框架可以概括为以下几个步骤:1. 对Transformer模型中的计算进行分解,将其视为一系列函数组合;2. 对每个函数组合进行舍入误差分析,确定哪些组件的计算精度对最终结果影响最大;3. 根据误差分析的结果,自适应地选择一小部分组件进行高精度计算,其余组件采用低精度计算;4. 将混合精度计算应用于Transformer模型的推理过程。
关键创新:LAMP方法的关键创新在于其自适应的混合精度选择策略。与传统的静态混合精度方法不同,LAMP方法能够根据模型的具体结构和输入数据,动态地调整计算精度,从而在精度和效率之间实现更好的平衡。此外,该方法基于严格的误差分析,能够保证精度损失在可控范围内。
关键设计:LAMP方法的关键设计包括:1. 舍入误差分析的具体方法,例如使用泰勒展开或敏感性分析来估计误差;2. 选择高精度计算组件的策略,例如选择误差贡献最大的前k个组件;3. 混合精度计算的具体实现方式,例如使用不同的数据类型(如FP16和FP32)或不同的硬件加速器。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在GPT-2模型上,LAMP方法能够在极低的重计算率下实现高达两个数量级的精度提升。这意味着只需要对少量计算进行高精度处理,就能显著提高模型的整体精度,从而在保证精度的前提下,大幅提升推理效率。该结果验证了LAMP方法的有效性和实用性。
🎯 应用场景
LAMP方法可应用于各种需要高效推理的大型语言模型部署场景,例如移动设备、边缘计算设备等资源受限的环境。通过降低计算复杂度和内存占用,该方法能够使这些设备也能运行复杂的LLM,从而实现更广泛的应用,如智能助手、机器翻译、文本生成等。
📄 摘要(原文)
Mixed-precision computations are a hallmark of the current stage of AI, driving the progress in large language models towards efficient, locally deployable solutions. This article addresses the floating-point computation of compositionally-rich functions, concentrating on transformer inference. Based on the rounding error analysis of a composition $f(g(\mathrm{x}))$, we provide an adaptive strategy that selects a small subset of components of $g(\mathrm{x})$ to be computed more accurately while all other computations can be carried out with lower accuracy. We then explain how this strategy can be applied to different compositions within a transformer and illustrate its overall effect on transformer inference. We study the effectiveness of this algorithm numerically on GPT-2 models and demonstrate that already very low recomputation rates allow for improvements of up to two orders of magnitude in accuracy.