Signal-Adaptive Trust Regions for Gradient-Free Optimization of Recurrent Spiking Neural Networks
作者: Jinhao Li, Yuhao Sun, Zhiyuan Ma, Hao He, Xinche Zhang, Xing Chen, Jin Li, Sen Song
分类: cs.LG, cs.AI
发布日期: 2026-01-29
💡 一句话要点
提出信号自适应信任域(SATR)优化RSNN,提升高维强化学习控制性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环脉冲神经网络 无梯度优化 信任域方法 强化学习 信号自适应
📋 核心要点
- RSNN训练在高维强化学习中面临挑战,无梯度优化受限于梯度估计的高方差,导致更新不稳定。
- 提出信号自适应信任域(SATR),通过信号能量归一化的KL散度约束策略更新,动态调整信任域大小。
- 实验表明,SATR在有限种群下提高了RSNN训练的稳定性,并取得了与PPO-LSTM等基线相当的性能。
📝 摘要(中文)
循环脉冲神经网络(RSNNs)是节能控制策略的有潜力载体,但训练它们用于高维、长时程强化学习仍然具有挑战性。基于种群的无梯度优化通过估计梯度来规避通过不可微脉冲动力学的反向传播。然而,在有限的种群下,这些估计的高方差可能导致有害和过于激进的更新步骤。受到强化学习中信任域方法的启发,该方法在分布空间中约束策略更新,我们提出了信号自适应信任域(SATR),这是一种分布更新规则,通过限制由估计的信号能量归一化的KL散度来约束相对变化。SATR在强信号下自动扩展信任域,并在更新以噪声为主时收缩信任域。我们为伯努利连接分布实例化SATR,该分布已显示出RSNN优化的强大经验性能。在一套高维连续控制基准测试中,SATR提高了有限种群下的稳定性,并达到了与包括PPO-LSTM在内的强大基线相比具有竞争力的回报。此外,为了使SATR能够大规模应用,我们引入了用于二元脉冲和二元权重的位集实现,从而大大减少了实际训练时间,并实现了快速RSNN策略搜索。
🔬 方法详解
问题定义:论文旨在解决循环脉冲神经网络(RSNNs)在高维、长时程强化学习任务中训练困难的问题。现有的基于种群的无梯度优化方法,虽然避免了不可微性带来的反向传播问题,但由于有限种群规模导致的梯度估计方差过高,容易产生不稳定和过于激进的更新,影响训练效果。
核心思路:论文的核心思路是引入信任域的概念,借鉴强化学习中信任域方法约束策略更新的思想。具体而言,提出了一种名为信号自适应信任域(SATR)的分布更新规则,该规则通过限制由估计的信号能量归一化的KL散度来约束相对变化。这样设计的目的是使信任域的大小能够根据信号的强弱自适应调整,在信号强时扩大信任域,允许更大的更新步长,在信号弱时缩小信任域,避免噪声干扰。
技术框架:SATR方法主要包含以下几个关键模块:1) 基于种群的无梯度优化器,用于估计RSNN的梯度;2) 信号能量估计器,用于估计当前更新信号的强度;3) KL散度计算器,用于计算新旧策略之间的分布差异;4) 信任域约束模块,根据信号能量和KL散度动态调整信任域的大小,并约束策略更新。整体流程是:首先使用无梯度优化器估计梯度,然后计算信号能量和KL散度,根据这两个指标调整信任域大小,最后在信任域内更新策略。
关键创新:论文最重要的技术创新点在于提出了信号自适应的信任域机制。与传统的固定大小的信任域方法不同,SATR能够根据信号的强弱动态调整信任域的大小,从而更好地平衡探索和利用,提高训练的稳定性和效率。此外,论文还针对二元脉冲和二元权重的RSNN,提出了位集实现,进一步提高了训练速度。
关键设计:论文的关键设计包括:1) 使用伯努利连接分布来表示RSNN的连接权重,简化了策略更新的计算;2) 使用信号能量归一化的KL散度作为信任域的约束条件,使得信任域的大小能够自适应地调整;3) 针对二元脉冲和二元权重的RSNN,提出了位集实现,利用位运算加速计算,显著减少了训练时间。
🖼️ 关键图片
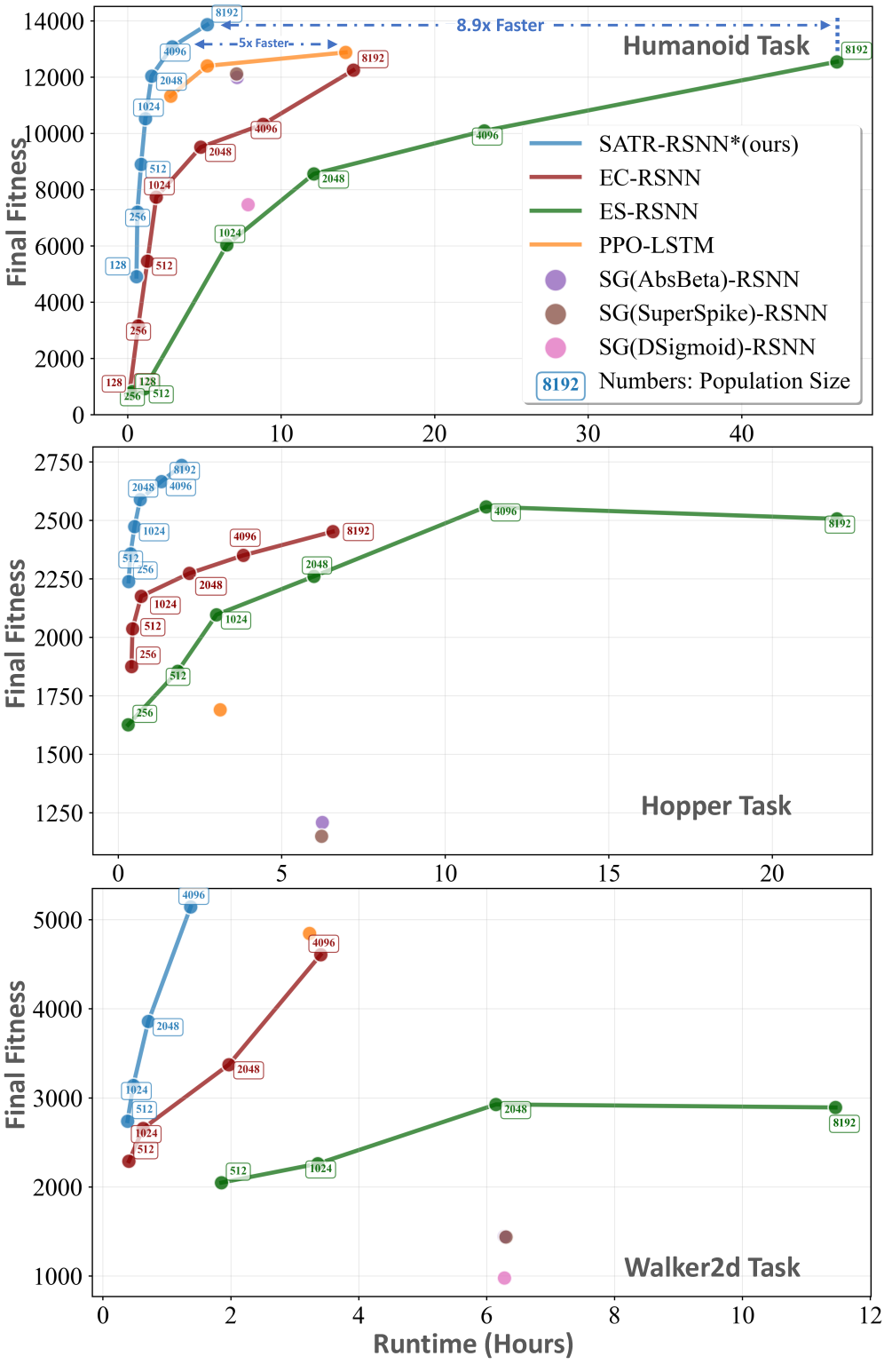

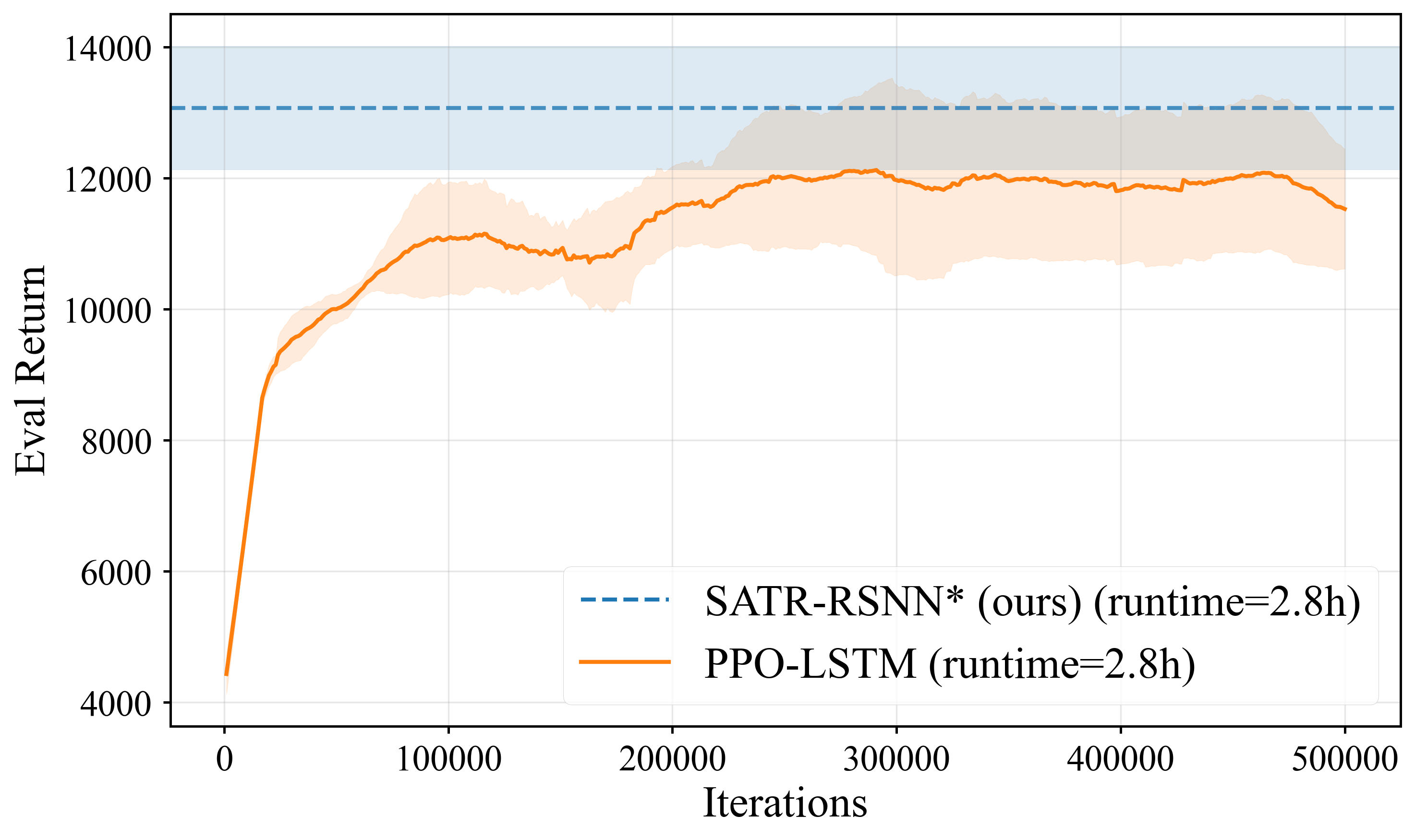
📊 实验亮点
实验结果表明,SATR在多个高维连续控制基准测试中,显著提高了RSNN训练的稳定性,尤其是在有限种群规模下。与PPO-LSTM等强大的基线方法相比,SATR取得了具有竞争力的回报。此外,位集实现显著减少了训练时间,使得SATR能够在大规模RSNN策略搜索中得到应用。
🎯 应用场景
该研究成果可应用于需要节能高效控制策略的领域,例如机器人控制、无人机导航、智能传感器网络等。通过训练RSNN,可以实现低功耗、高性能的控制系统,尤其适用于资源受限的边缘计算设备。此外,该方法还可以推广到其他类型的神经网络和强化学习任务中,具有广泛的应用前景。
📄 摘要(原文)
Recurrent spiking neural networks (RSNNs) are a promising substrate for energy-efficient control policies, but training them for high-dimensional, long-horizon reinforcement learning remains challenging. Population-based, gradient-free optimization circumvents backpropagation through non-differentiable spike dynamics by estimating gradients. However, with finite populations, high variance of these estimates can induce harmful and overly aggressive update steps. Inspired by trust-region methods in reinforcement learning that constrain policy updates in distribution space, we propose \textbf{Signal-Adaptive Trust Regions (SATR)}, a distributional update rule that constrains relative change by bounding KL divergence normalized by an estimated signal energy. SATR automatically expands the trust region under strong signals and contracts it when updates are noise-dominated. We instantiate SATR for Bernoulli connectivity distributions, which have shown strong empirical performance for RSNN optimization. Across a suite of high-dimensional continuous-control benchmarks, SATR improves stability under limited populations and reaches competitive returns against strong baselines including PPO-LSTM. In addition, to make SATR practical at scale, we introduce a bitset implementation for binary spiking and binary weights, substantially reducing wall-clock training time and enabling fast RSNN policy search.