Accurate Network Traffic Matrix Prediction via LEAD: an LLM-Enhanced Adapter-Based Conditional Diffusion Model
作者: Yu Sun, Yaqiong Liu, Nan Cheng, Jiayuan Li, Zihan Jia, Xialin Du, Mugen Peng
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
LEAD:一种LLM增强的、基于Adapter的条件扩散模型,用于精确的网络流量矩阵预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 网络流量预测 流量矩阵 扩散模型 大型语言模型 时间序列预测
📋 核心要点
- 现有网络流量矩阵预测方法在高动态和突发流量下,存在过度平滑和不确定性感知不足的问题,导致预测精度下降。
- LEAD模型通过“流量到图像”转换、冻结LLM与可训练Adapter以及双重条件策略,有效捕获流量的时空依赖关系,提升预测精度。
- 实验结果表明,LEAD在Abilene和GEANT数据集上显著优于现有方法,RMSE分别降低了45.2%和27.3%,证明了其有效性。
📝 摘要(中文)
为了适应6G和AI原生边缘智能的发展,网络运营越来越需要在严格的计算和延迟约束下进行预测性和风险感知的调整。网络流量矩阵(TM)是主动流量工程的基本信号,它表征了节点之间的流量。然而,由于网络动态的随机性、非线性和突发性,精确的TM预测仍然具有挑战性。现有的判别模型常常遭受过度平滑,并且不具备充分的不确定性感知,导致在极端突发情况下保真度较差。为了解决这些限制,我们提出了LEAD,一种大型语言模型(LLM)增强的、基于Adapter的条件扩散模型。首先,LEAD采用“流量到图像”的范式,将流量矩阵转换为RGB图像,从而能够通过视觉骨干网络进行全局依赖建模。然后,我们设计了一个“冻结LLM与可训练Adapter”模型,以有限的计算成本有效地捕获时间语义。此外,我们提出了一种双重条件策略,以精确地引导扩散模型生成复杂、动态的网络流量矩阵。在Abilene和GEANT数据集上的实验表明,LEAD优于所有基线模型。在Abilene数据集上,LEAD相对于最佳基线,RMSE显著降低了45.2%,并且误差幅度仅从单步预测的0.1098略微上升到20步预测的0.1134。同时,在GEANT数据集上,LEAD在20步预测范围内实现了0.0258的RMSE,比最佳基线低27.3%。
🔬 方法详解
问题定义:论文旨在解决网络流量矩阵(TM)的精确预测问题。现有方法,特别是判别模型,在面对网络流量的随机性、非线性和突发性时,容易产生过度平滑现象,并且对预测结果的不确定性估计不足,导致预测精度在实际应用中受到限制。
核心思路:论文的核心思路是将网络流量矩阵预测问题转化为一个条件图像生成问题,并利用大型语言模型(LLM)的强大语义理解能力来提升预测精度。通过将流量矩阵转换为图像,可以利用视觉模型捕获全局依赖关系。同时,利用LLM提取时间序列的语义信息,并结合扩散模型生成高质量的预测结果。
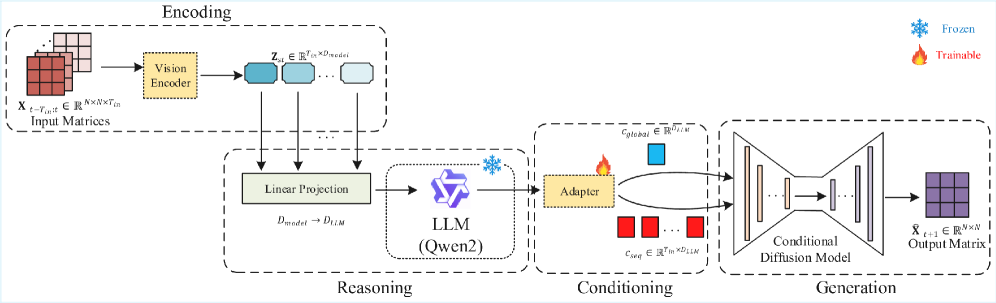
技术框架:LEAD模型主要包含三个核心模块:1) Traffic-to-Image转换模块,将流量矩阵转换为RGB图像;2) LLM增强的Adapter模块,利用冻结的LLM和可训练的Adapter提取时间序列的语义信息;3) 条件扩散模型,基于提取的语义信息和流量矩阵的历史信息,生成未来的流量矩阵。整体流程是:首先将历史流量矩阵转换为图像序列,然后利用LLM增强的Adapter提取时间语义,最后利用双重条件策略引导扩散模型生成预测的流量矩阵。
关键创新:LEAD模型的关键创新在于:1) 提出了“Traffic-to-Image”的范式,将流量预测问题转化为图像生成问题,从而可以利用视觉模型捕获全局依赖关系;2) 设计了“冻结LLM与可训练Adapter”模型,在利用LLM强大语义理解能力的同时,降低了计算成本;3) 提出了双重条件策略,更精确地引导扩散模型生成复杂的动态网络流量矩阵。
关键设计:在Traffic-to-Image转换中,流量值被缩放到0-255的范围内,并映射到RGB图像的像素值。LLM采用冻结参数的方式,仅训练Adapter层,以降低计算成本。扩散模型采用U-Net结构,并使用双重条件(时间语义和历史流量信息)引导生成过程。损失函数采用标准的均方误差(MSE)损失。
🖼️ 关键图片


📊 实验亮点
LEAD模型在Abilene数据集上,相对于最佳基线,RMSE显著降低了45.2%,并且误差幅度仅从单步预测的0.1098略微上升到20步预测的0.1134。在GEANT数据集上,LEAD在20步预测范围内实现了0.0258的RMSE,比最佳基线低27.3%。这些结果表明LEAD模型在网络流量矩阵预测方面具有显著的优势。
🎯 应用场景
该研究成果可应用于智能网络管理、流量工程和网络安全等领域。通过精确预测网络流量矩阵,可以实现主动的流量调度和资源分配,优化网络性能,降低网络拥塞,并及时发现潜在的网络攻击。该技术对于构建高效、可靠和安全的下一代网络具有重要意义。
📄 摘要(原文)
Driven by the evolution toward 6G and AI-native edge intelligence, network operations increasingly require predictive and risk-aware adaptation under stringent computation and latency constraints. Network Traffic Matrix (TM), which characterizes flow volumes between nodes, is a fundamental signal for proactive traffic engineering. However, accurate TM forecasting remains challenging due to the stochastic, non-linear, and bursty nature of network dynamics. Existing discriminative models often suffer from over-smoothing and provide limited uncertainty awareness, leading to poor fidelity under extreme bursts. To address these limitations, we propose LEAD, a Large Language Model (LLM)-Enhanced Adapter-based conditional Diffusion model. First, LEAD adopts a "Traffic-to-Image" paradigm to transform traffic matrices into RGB images, enabling global dependency modeling via vision backbones. Then, we design a "Frozen LLM with Trainable Adapter" model, which efficiently captures temporal semantics with limited computational cost. Moreover, we propose a Dual-Conditioning Strategy to precisely guide a diffusion model to generate complex, dynamic network traffic matrices. Experiments on the Abilene and GEANT datasets demonstrate that LEAD outperforms all baselines. On the Abilene dataset, LEAD attains a remarkable 45.2% reduction in RMSE against the best baseline, with the error margin rising only marginally from 0.1098 at one-step to 0.1134 at 20-step predictions. Meanwhile, on the GEANT dataset, LEAD achieves a 0.0258 RMSE at 20-step prediction horizon which is 27.3% lower than the best baseline.