ConceptMoE: Adaptive Token-to-Concept Compression for Implicit Compute Allocation
作者: Zihao Huang, Jundong Zhou, Xingwei Qu, Qiyang Min, Ge Zhang
分类: cs.LG
发布日期: 2026-01-29
💡 一句话要点
ConceptMoE:自适应token概念压缩实现隐式计算分配,提升LLM效率与性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 自适应计算 token压缩 长序列建模
📋 核心要点
- 现有LLM对所有token分配相同计算资源,忽略了token重要性差异,导致计算效率低下。
- ConceptMoE通过动态合并语义相似token为概念表示,实现token级别自适应计算分配。
- 实验表明,ConceptMoE在多种任务上优于标准MoE,并显著提升了长序列处理速度。
📝 摘要(中文)
大型语言模型对所有token分配统一的计算资源,忽略了部分序列易于预测而另一些需要深度推理。本文提出ConceptMoE,它动态地将语义相似的token合并为概念表示,从而实现隐式的token级别计算分配。一个可学习的chunk模块通过测量token间的相似性来识别最佳边界,并在序列进入计算密集型的概念模型之前,按目标比例R压缩序列。关键在于,MoE架构能够进行受控评估:我们将节省的计算重新分配,以匹配基线的激活FLOPs(不包括注意力图计算)和总参数,从而隔离真正的架构优势。在此条件下,ConceptMoE在语言和视觉语言任务中始终优于标准MoE,在语言预训练上达到+0.9个点,在长上下文理解上达到+2.3个点,在多模态基准上达到+0.6个点。当使用层循环持续训练转换预训练的MoE时,增益达到+5.5个点,证明了其在实际应用中的可行性。除了性能之外,ConceptMoE还将注意力计算减少高达R^2倍,KV缓存减少R倍。在R=2时,经验测量表明,在长序列上预填充加速达到175%,解码加速高达117%。最小的架构修改使其能够直接集成到现有的MoE中,表明自适应概念级处理从根本上提高了大型语言模型的有效性和效率。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在处理序列时,对所有token分配相同的计算资源,没有考虑到不同token的重要性差异。一些token可能包含冗余信息或易于预测,而另一些token则需要更深入的推理。这种均匀分配方式导致计算资源的浪费,降低了模型的效率。
核心思路:ConceptMoE的核心思路是自适应地将语义相似的token合并为概念表示,从而实现隐式的token级别计算分配。通过减少需要处理的token数量,将节省的计算资源重新分配给更重要的概念,提高模型的效率和性能。这种方法类似于人类在阅读时将多个单词组合成一个概念进行理解。
技术框架:ConceptMoE的整体架构包括一个可学习的chunk模块和一个概念模型。chunk模块负责将输入序列分割成多个chunk,并将每个chunk压缩成一个概念表示。概念模型则基于这些概念表示进行后续的计算,例如语言建模或视觉语言任务。MoE架构用于控制评估,确保在公平的条件下比较ConceptMoE和标准MoE。
关键创新:ConceptMoE的关键创新在于引入了自适应的token-to-concept压缩机制。与传统的固定长度token处理方式不同,ConceptMoE能够根据token之间的语义相似性动态地调整chunk的大小,从而更好地捕捉序列中的关键信息。此外,通过MoE架构进行受控实验,能够更准确地评估ConceptMoE的性能提升。
关键设计:chunk模块使用可学习的参数来衡量token之间的相似性,并根据设定的目标压缩比例R来确定chunk的边界。损失函数的设计旨在鼓励chunk模块学习到能够有效压缩序列并保留关键信息的表示。MoE架构中的专家数量和容量因子等参数需要根据具体的任务和数据集进行调整,以达到最佳的性能。
🖼️ 关键图片

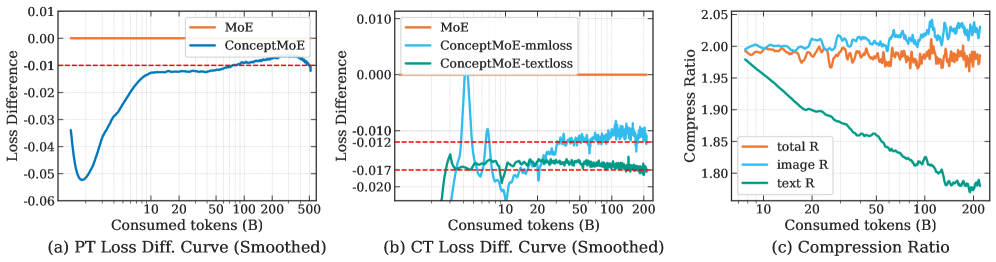

📊 实验亮点
ConceptMoE在语言预训练、长上下文理解和多模态基准测试中均取得了显著的性能提升。具体而言,在语言预训练任务中,ConceptMoE比标准MoE提高了0.9个点;在长上下文理解任务中,提高了2.3个点;在多模态基准测试中,提高了0.6个点。此外,ConceptMoE还显著降低了注意力计算量和KV缓存大小,在R=2时,预填充加速达到175%,解码加速高达117%。
🎯 应用场景
ConceptMoE具有广泛的应用前景,可以应用于各种需要处理长序列的场景,例如机器翻译、文本摘要、对话系统和视频理解。通过减少计算量和内存占用,ConceptMoE可以加速模型的训练和推理过程,使其更易于部署在资源受限的设备上。此外,ConceptMoE还可以作为一种通用的计算优化技术,应用于其他类型的神经网络模型。
📄 摘要(原文)
Large language models allocate uniform computation across all tokens, ignoring that some sequences are trivially predictable while others require deep reasoning. We introduce ConceptMoE, which dynamically merges semantically similar tokens into concept representations, performing implicit token-level compute allocation. A learnable chunk module identifies optimal boundaries by measuring inter-token similarity, compressing sequences by a target ratio $R$ before they enter the compute-intensive concept model. Crucially, the MoE architecture enables controlled evaluation: we reallocate saved computation to match baseline activated FLOPs (excluding attention map computation) and total parameters, isolating genuine architectural benefits. Under these conditions, ConceptMoE consistently outperforms standard MoE across language and vision-language tasks, achieving +0.9 points on language pretraining, +2.3 points on long context understanding, and +0.6 points on multimodal benchmarks. When converting pretrained MoE during continual training with layer looping, gains reach +5.5 points, demonstrating practical applicability. Beyond performance, ConceptMoE reduces attention computation by up to $R^2\times$ and KV cache by $R\times$. At $R=2$, empirical measurements show prefill speedups reaching 175\% and decoding speedups up to 117\% on long sequences. The minimal architectural modifications enable straightforward integration into existing MoE, demonstrating that adaptive concept-level processing fundamentally improves both effectiveness and efficiency of large language models.