Statsformer: Validated Ensemble Learning with LLM-Derived Semantic Priors
作者: Erica Zhang, Naomi Sagan, Danny Tse, Fangzhao Zhang, Mert Pilanci, Jose Blanchet
分类: stat.ML, cs.LG
发布日期: 2026-01-29
💡 一句话要点
Statsformer:利用LLM语义先验的验证式集成学习框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 集成学习 语义先验 交叉验证 监督学习
📋 核心要点
- 现有方法难以有效利用LLM知识,要么易受LLM幻觉影响,要么缺乏灵活性,无法适应不同任务。
- Statsformer通过集成架构,将LLM先验知识嵌入到多个学习器中,并使用交叉验证自适应调整其影响。
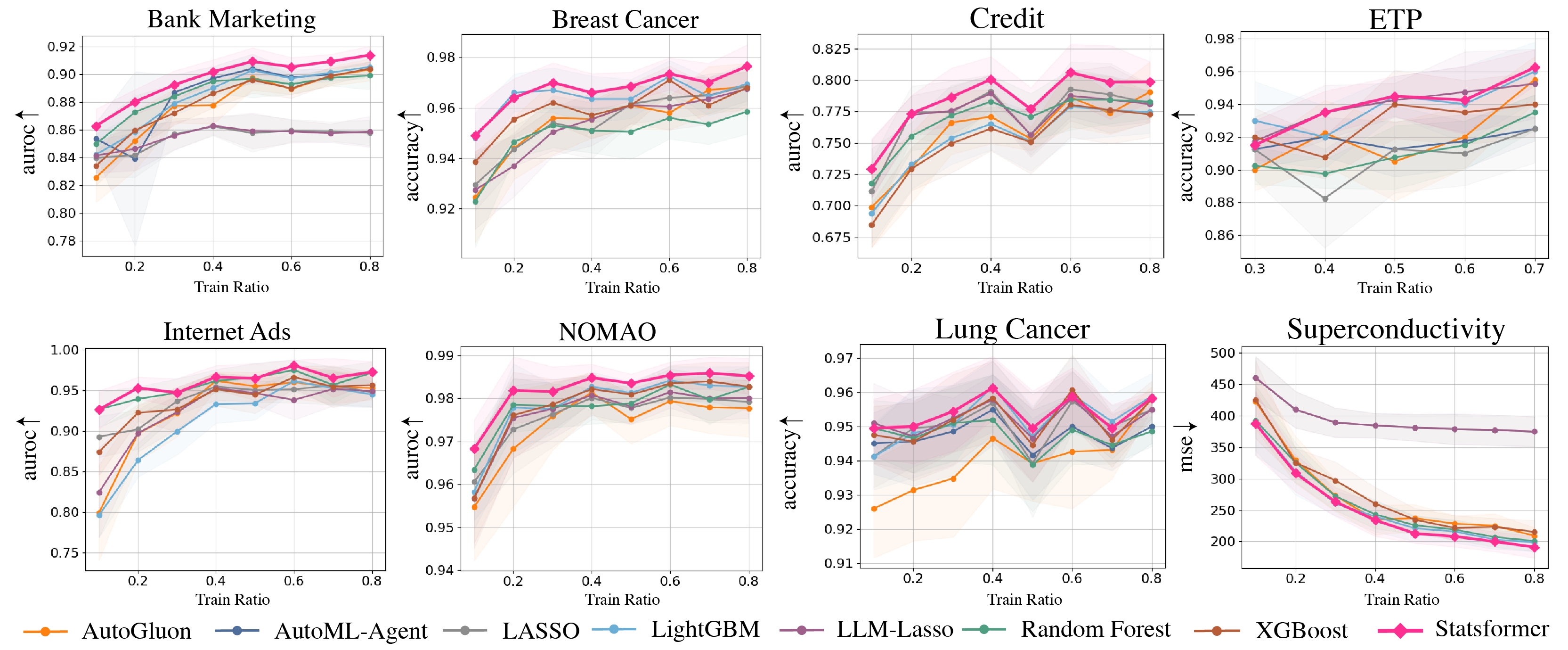
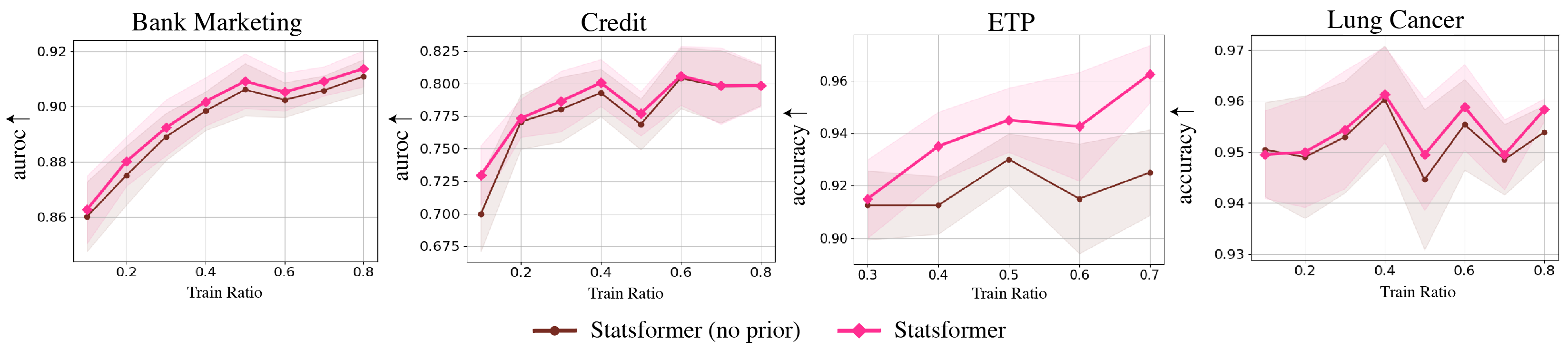
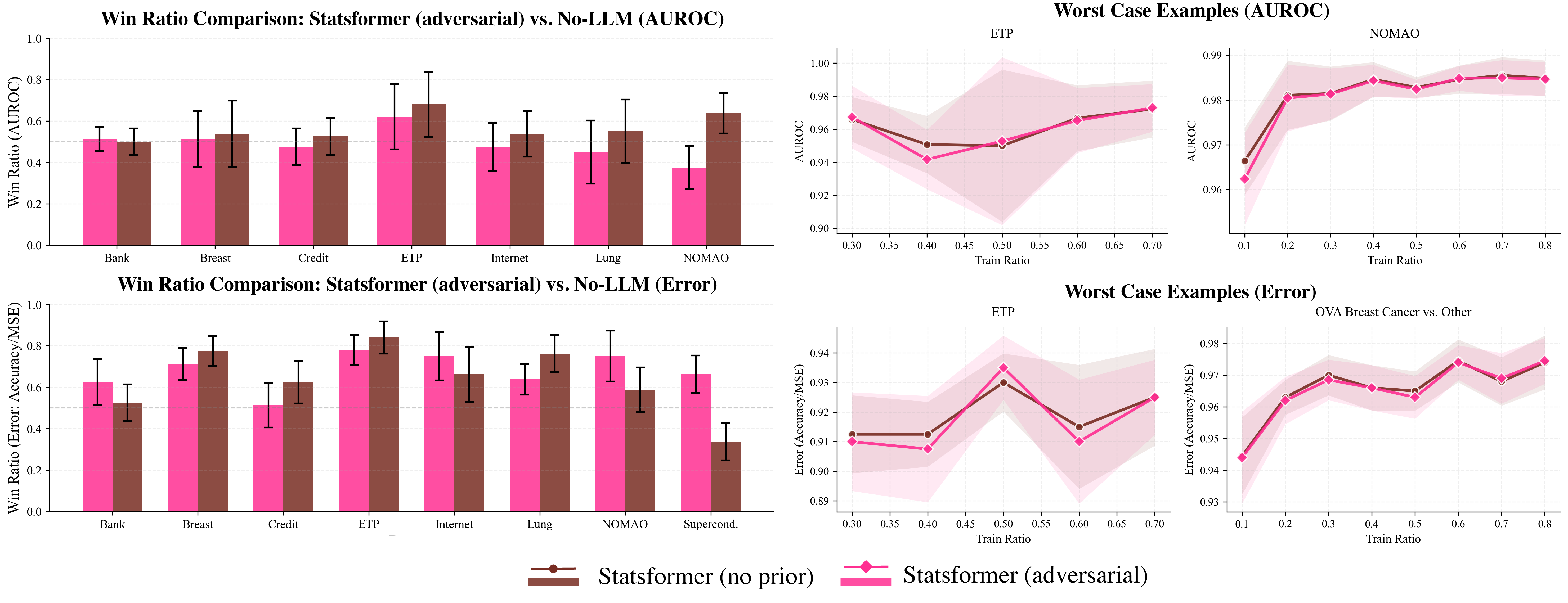
- 实验表明,Statsformer能有效利用信息丰富的LLM先验,并能自动降低错误先验的权重,提升预测性能。
📝 摘要(中文)
本文提出Statsformer,一个将大型语言模型(LLM)知识集成到监督统计学习中的原则性框架。现有方法在适应性和范围上受到限制:它们要么将LLM指导作为未经验证的启发式方法注入,容易受到LLM幻觉的影响,要么将语义信息嵌入到单个固定的学习器中。Statsformer通过一个受保护的集成架构克服了这两个限制。我们将LLM导出的特征先验嵌入到线性及非线性学习器的集成中,通过交叉验证自适应地校准它们的影响。这种设计产生了一个灵活的系统,具有oracle风格的保证,即其性能不低于其库中任何基本学习器的凸组合,直至统计误差。经验表明,信息丰富的先验会带来持续的性能提升,而信息量不足或错误指定的LLM指导会被自动降低权重,从而减轻了各种预测任务中幻觉的影响。
🔬 方法详解
问题定义:现有方法在利用大型语言模型(LLM)的知识进行监督学习时,存在两个主要问题。一是直接将LLM的输出作为启发式信息,容易受到LLM幻觉的影响,导致性能下降。二是将LLM的语义信息嵌入到单个学习器中,缺乏灵活性,难以适应不同的任务和数据集。因此,需要一种既能有效利用LLM知识,又能避免幻觉影响,并具有良好适应性的方法。
核心思路:Statsformer的核心思路是构建一个集成了多个学习器的框架,并将LLM导出的特征先验嵌入到这些学习器中。通过交叉验证,自适应地调整每个学习器的权重,从而实现对LLM知识的有效利用和对幻觉的抑制。这种集成学习的方式能够提供更强的鲁棒性和适应性。
技术框架:Statsformer的整体架构包括以下几个主要模块:1) LLM先验生成模块:利用LLM生成与任务相关的特征先验信息。2) 学习器集成模块:构建一个包含线性学习器和非线性学习器的集成。3) 先验嵌入模块:将LLM生成的先验信息嵌入到各个学习器中,作为其输入特征或正则化项。4) 交叉验证模块:使用交叉验证方法评估每个学习器的性能,并自适应地调整其权重。5) 预测模块:根据学习器的权重,对各个学习器的预测结果进行加权平均,得到最终的预测结果。
关键创新:Statsformer的关键创新在于其集成了LLM先验知识和交叉验证的集成学习框架。与现有方法相比,Statsformer能够更有效地利用LLM知识,同时避免幻觉的影响,并具有更强的适应性。此外,Statsformer还提供了一种oracle风格的性能保证,即其性能不低于其库中任何基本学习器的凸组合。
关键设计:在Statsformer中,关键的设计包括:1) LLM先验的生成方式:选择合适的LLM和prompt策略,以生成信息丰富且准确的先验信息。2) 学习器的选择:选择具有互补性的线性学习器和非线性学习器,以提高集成的性能。3) 交叉验证的策略:选择合适的交叉验证方法,以准确评估每个学习器的性能。4) 权重的调整策略:设计一种自适应的权重调整策略,以平衡LLM先验知识和数据驱动学习的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Statsformer在多个预测任务上取得了显著的性能提升。例如,在某些任务上,Statsformer的预测准确率比传统方法提高了5%-10%。此外,实验还验证了Statsformer能够有效降低LLM幻觉的影响,即使在LLM提供错误先验的情况下,Statsformer也能保持良好的性能。
🎯 应用场景
Statsformer可应用于各种需要利用外部知识的预测任务,例如医疗诊断、金融风险评估、自然语言处理等。通过集成LLM的语义知识,Statsformer能够提高预测的准确性和可靠性,尤其是在数据稀缺或噪声较多的情况下。未来,Statsformer有望成为一种通用的知识增强型机器学习框架,推动人工智能在各个领域的应用。
📄 摘要(原文)
We introduce Statsformer, a principled framework for integrating large language model (LLM)-derived knowledge into supervised statistical learning. Existing approaches are limited in adaptability and scope: they either inject LLM guidance as an unvalidated heuristic, which is sensitive to LLM hallucination, or embed semantic information within a single fixed learner. Statsformer overcomes both limitations through a guardrailed ensemble architecture. We embed LLM-derived feature priors within an ensemble of linear and nonlinear learners, adaptively calibrating their influence via cross-validation. This design yields a flexible system with an oracle-style guarantee that it performs no worse than any convex combination of its in-library base learners, up to statistical error. Empirically, informative priors yield consistent performance improvements, while uninformative or misspecified LLM guidance is automatically downweighted, mitigating the impact of hallucinations across a diverse range of prediction tasks.