Grounding and Enhancing Informativeness and Utility in Dataset Distillation
作者: Shaobo Wang, Yantai Yang, Guo Chen, Peiru Li, Kaixin Li, Yufa Zhou, Zhaorun Chen, Linfeng Zhang
分类: cs.LG, cs.AI
发布日期: 2026-01-29
备注: Accepted by ICLR 2026, 20 pages, 9 figures, 11 tables
💡 一句话要点
提出InfoUtil框架,通过信息量和效用最大化实现数据集蒸馏性能提升
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 数据集蒸馏 知识蒸馏 信息量 效用 Shapley Value 梯度范数 模型压缩 ImageNet
📋 核心要点
- 现有数据集蒸馏方法依赖启发式策略,缺乏对原始数据与合成数据间关系的深入理论分析。
- InfoUtil框架通过最大化信息量和效用,平衡了蒸馏数据集的信息丰富度和代表性,从而提升性能。
- 实验结果表明,InfoUtil在ImageNet-1K数据集上使用ResNet-18时,性能超越现有最佳方法6.1%。
📝 摘要(中文)
数据集蒸馏(DD)旨在从大型真实世界数据集中创建一个紧凑的数据集。虽然最近的方法通常依赖于启发式方法来平衡效率和质量,但原始数据和合成数据之间的基本关系仍未得到充分探索。本文在坚实的理论框架内重新审视了基于知识蒸馏的数据集蒸馏。我们引入了信息量和效用的概念,分别捕捉样本中的关键信息和训练集中的重要样本。基于这些原则,我们从数学上定义了最优数据集蒸馏。然后,我们提出了InfoUtil,一个在合成的蒸馏数据集中平衡信息量和效用的框架。InfoUtil包含两个关键组件:(1)使用Shapley Value属性进行博弈论信息量最大化,以提取样本中的关键信息,以及(2)通过基于梯度范数选择全局有影响力的样本来实现有原则的效用最大化。这些组件确保了蒸馏数据集既具有信息性又经过效用优化。实验表明,我们的方法在使用ResNet-18的ImageNet-1K数据集上,比之前的最先进方法实现了6.1%的性能提升。
🔬 方法详解
问题定义:数据集蒸馏旨在从大规模数据集中提取一个小的、具有代表性的子集,用于加速模型训练并降低存储成本。现有方法通常采用启发式策略,缺乏对原始数据和蒸馏数据之间内在联系的理论分析,导致蒸馏后的数据集可能丢失关键信息或包含冗余信息,从而影响模型性能。
核心思路:InfoUtil的核心思想是将数据集蒸馏问题建模为一个信息量和效用之间的平衡问题。信息量衡量了单个样本所包含的关键信息,效用衡量了样本对模型训练的贡献程度。通过最大化蒸馏数据集的信息量和效用,InfoUtil旨在选择既包含关键信息又对模型训练有益的样本。
技术框架:InfoUtil框架包含两个主要模块:信息量最大化模块和效用最大化模块。信息量最大化模块使用基于Shapley Value的博弈论方法来评估每个样本的信息量,并选择信息量最大的样本。效用最大化模块使用基于梯度范数的方法来评估每个样本对模型训练的贡献程度,并选择贡献最大的样本。这两个模块协同工作,共同构建一个既具有信息性又具有效用的蒸馏数据集。
关键创新:InfoUtil的关键创新在于其将数据集蒸馏问题建模为一个信息量和效用之间的平衡问题,并提出了相应的优化方法。与现有方法相比,InfoUtil不再依赖启发式策略,而是基于严格的理论框架,能够更有效地选择关键样本,从而提高蒸馏数据集的性能。此外,InfoUtil使用Shapley Value和梯度范数来评估样本的信息量和效用,这些方法能够更准确地捕捉样本的内在价值。
关键设计:在信息量最大化模块中,InfoUtil使用Shapley Value来评估每个样本对模型预测的贡献程度。具体来说,InfoUtil将每个样本视为一个博弈参与者,并将模型预测的准确率视为博弈的收益。然后,InfoUtil使用Shapley Value来计算每个样本对收益的贡献,并将该贡献作为样本的信息量。在效用最大化模块中,InfoUtil使用梯度范数来评估每个样本对模型训练的贡献程度。具体来说,InfoUtil计算每个样本在模型损失函数上的梯度范数,并将该梯度范数作为样本的效用。InfoUtil使用贪心算法来选择信息量和效用最大的样本,构建蒸馏数据集。
🖼️ 关键图片


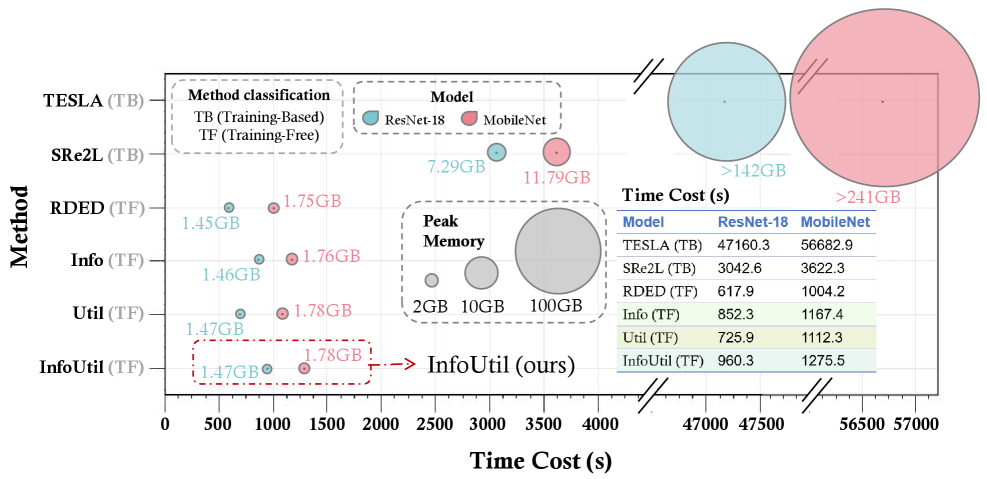
📊 实验亮点
InfoUtil在ImageNet-1K数据集上使用ResNet-18时,相比于之前的最先进方法实现了6.1%的性能提升。这一结果表明,InfoUtil能够更有效地选择关键样本,从而提高蒸馏数据集的性能。此外,实验还表明,InfoUtil在不同的数据集和模型上都具有良好的泛化能力。
🎯 应用场景
InfoUtil可应用于各种需要数据集压缩的场景,如移动设备上的模型部署、边缘计算和联邦学习。通过减少数据存储和传输成本,InfoUtil能够加速模型训练和推理,并提高资源利用率。此外,InfoUtil还可以用于数据隐私保护,通过蒸馏生成更小的数据集,降低原始数据泄露的风险。
📄 摘要(原文)
Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.