Reward Models Inherit Value Biases from Pretraining
作者: Brian Christian, Jessica A. F. Thompson, Elle Michelle Yang, Vincent Adam, Hannah Rose Kirk, Christopher Summerfield, Tsvetomira Dumbalska
分类: cs.LG, cs.AI, cs.CL, cs.CY
发布日期: 2026-01-28
💡 一句话要点
奖励模型继承预训练语言模型的价值观偏见,影响对齐效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 价值观偏见 大型语言模型 预训练模型 对齐 心理语言学 能动性 社群性
📋 核心要点
- 现有奖励模型(RMs)在对齐大型语言模型(LLMs)时,其价值观偏见问题未被充分研究,可能导致对齐效果不佳。
- 该论文的核心思想是揭示RMs从预训练LLMs继承的价值观偏见,并分析这种偏见如何影响RMs的输出。
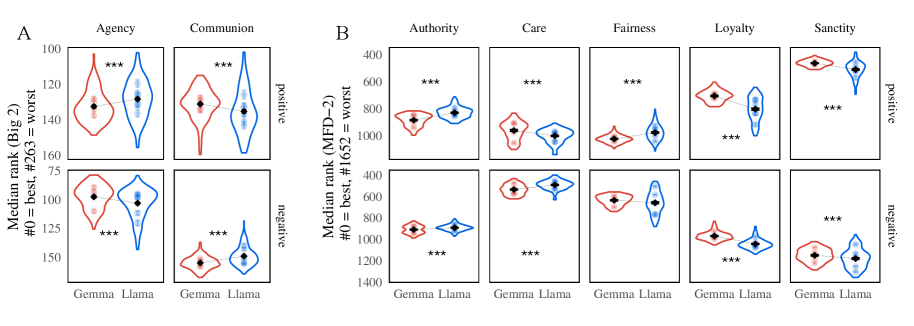
- 实验结果表明,不同的基础模型会导致RMs在“能动性”和“社群性”等价值观维度上存在显著差异,且这种差异具有持久性。
📝 摘要(中文)
奖励模型(RMs)在将大型语言模型(LLMs)与人类价值观对齐方面至关重要,但受到的关注却少于预训练和后训练的LLMs本身。由于RMs由LLMs初始化而来,它们继承了塑造其行为的表征,但这种影响的性质和程度仍未得到充分研究。本研究对10个领先的开源RM进行了全面研究,使用经过验证的心理语言学语料库,表明RMs在人类价值观的多个维度上表现出显著差异,这取决于其基础模型。使用“Big Two”心理学轴,我们展示了Llama RMs对“能动性”的强烈偏好,以及Gemma RMs对“社群性”的相应强烈偏好。即使偏好数据和微调过程相同,这种现象仍然成立,并且我们将其追溯到各自指令调整和预训练模型的logits。这些log-probability差异本身可以被公式化为一个隐式RM;我们推导出可用的隐式奖励分数,并表明它们表现出相同的能动性/社群性差异。我们进行了实验,通过消融偏好数据来源和数量来训练RMs,这表明这种效应不仅可重复,而且出人意料地持久。尽管RMs旨在代表人类偏好,但我们的证据表明,它们的输出受到其所基于的预训练LLMs的影响。这项工作强调了预训练阶段安全和对齐工作的重要性,并明确指出开源开发者对基础模型的选择与对性能的考虑一样,也是对价值观的考虑。
🔬 方法详解
问题定义:论文旨在解决奖励模型(RMs)在对齐大型语言模型(LLMs)时,由于继承自预训练模型的价值观偏见而导致对齐效果受限的问题。现有方法通常关注RMs的训练数据和微调过程,而忽略了预训练模型本身对RMs的影响,这可能导致RMs无法准确反映人类的真实偏好。
核心思路:论文的核心思路是研究RMs从预训练LLMs继承的价值观偏见,并分析这种偏见如何影响RMs的输出。通过心理语言学分析和实验验证,揭示不同基础模型会导致RMs在价值观维度上存在显著差异,从而强调预训练阶段安全和对齐工作的重要性。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择10个领先的开源RM作为研究对象;2) 使用经过验证的心理语言学语料库,评估RMs在人类价值观维度上的表现;3) 使用“Big Two”心理学轴(能动性和社群性)分析RMs的偏好差异;4) 将log-probability差异公式化为隐式RM,并推导出隐式奖励分数;5) 通过消融实验,验证偏好数据来源和数量对RMs偏见的影响。
关键创新:论文最重要的技术创新点在于揭示了RMs从预训练LLMs继承价值观偏见的现象,并证明这种偏见会对RMs的输出产生显著影响。与现有方法不同,该论文强调了预训练模型本身对RMs的影响,并提出了通过分析log-probability差异来评估RMs偏见的方法。
关键设计:论文的关键设计包括:1) 使用“Big Two”心理学轴(能动性和社群性)作为评估RMs价值观偏见的指标;2) 将log-probability差异公式化为隐式RM,并推导出隐式奖励分数,用于量化RMs的偏见程度;3) 通过消融实验,验证偏好数据来源和数量对RMs偏见的影响,从而评估偏见的持久性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Llama RMs对“能动性”表现出强烈偏好,而Gemma RMs对“社群性”表现出相应偏好。即使偏好数据和微调过程相同,这种现象仍然成立,并且可以追溯到各自指令调整和预训练模型的logits。消融实验表明,这种偏见不仅可重复,而且出人意料地持久。
🎯 应用场景
该研究成果可应用于改进大型语言模型的对齐策略,通过选择合适的基础模型或在预训练阶段进行价值观对齐,减少奖励模型中的偏见,从而提高LLMs的安全性、可靠性和公平性。此外,该研究也为评估和选择开源LLMs提供了新的视角,开发者不仅要考虑性能,还要关注模型的价值观倾向。
📄 摘要(原文)
Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the "Big Two" psychological axes, we show a robust preference of Llama RMs for "agency" and a corresponding robust preference of Gemma RMs for "communion." This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers' choice of base model is as much a consideration of values as of performance.