Training Reasoning Models on Saturated Problems via Failure-Prefix Conditioning
作者: Minwu Kim, Safal Shrestha, Keith Ross
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-28
备注: 16 pages
💡 一句话要点
提出失败前缀条件学习方法,解决LLM在饱和推理问题上的训练停滞问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理 失败案例 条件学习
📋 核心要点
- 现有基于RLVR的LLM推理训练方法在问题饱和时面临训练停滞,原因是模型难以遇到有用的失败案例。
- 论文提出失败前缀条件学习,通过在失败推理轨迹的前缀上进行条件训练,增加模型对失败状态的探索。
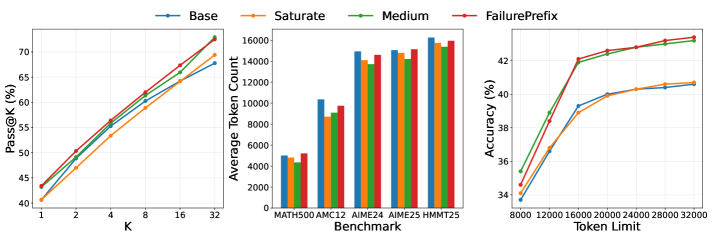
- 实验表明,该方法能有效提升模型在饱和问题上的推理能力,性能提升与在中等难度问题上训练相当,并具有良好的token效率。
📝 摘要(中文)
本文提出了一种名为失败前缀条件学习(failure-prefix conditioning)的方法,旨在解决大型语言模型(LLMs)在使用可验证奖励强化学习(RLVR)进行训练时,在问题变得饱和时训练停滞的问题。核心挑战在于模型难以接触到信息量丰富的失败案例。该方法通过在从罕见错误推理轨迹中提取的前缀上进行条件训练,重新分配探索,使模型暴露于易错状态。实验表明,该方法在保持token效率的同时,性能提升与在中等难度问题上训练相当。此外,该方法还能降低模型在误导性失败前缀下的性能下降,尽管在早期正确推理的坚持方面略有权衡。迭代刷新失败前缀的方法可以进一步提升性能。总而言之,失败前缀条件学习为扩展RLVR在饱和问题上的训练提供了一条有效途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在使用可验证奖励强化学习(RLVR)进行训练时,在问题变得饱和时训练停滞的问题。现有方法的主要痛点在于,随着训练的进行,模型越来越难以遇到包含有用信息的失败案例,导致学习信号稀疏,训练效率低下。
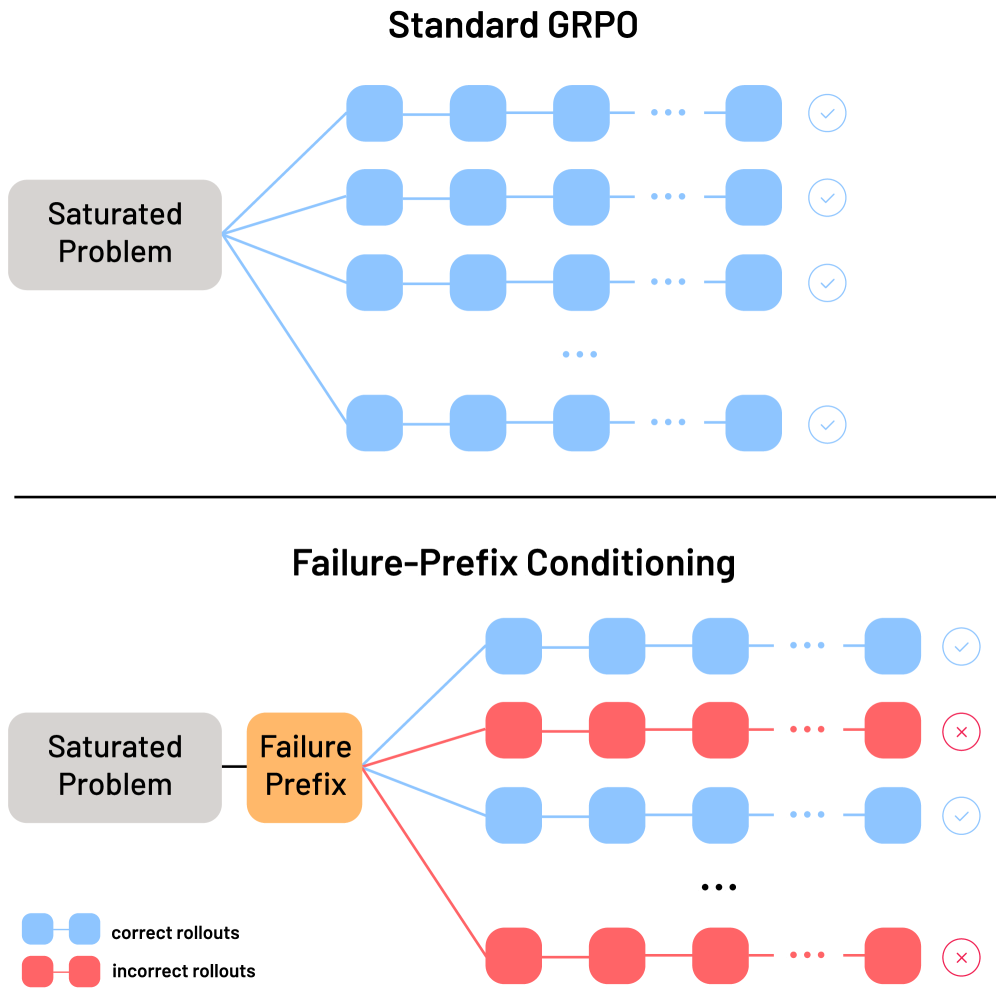
核心思路:论文的核心思路是通过“失败前缀条件学习”来增加模型接触失败案例的机会。具体来说,就是不再从原始问题开始训练,而是从模型在推理过程中犯错的中间状态(即失败轨迹的前缀)开始训练。这样可以迫使模型探索那些容易出错的状态,从而更有效地学习。
技术框架:整体流程如下:1) 使用RLVR训练LLM;2) 收集训练过程中产生的失败推理轨迹;3) 从这些失败轨迹中提取前缀(即部分推理步骤);4) 使用这些前缀作为条件,重新训练LLM。通过迭代这个过程,不断刷新失败前缀,可以进一步提升性能。
关键创新:最重要的创新点在于利用失败轨迹的前缀作为条件进行训练。与传统的从头开始训练相比,这种方法能够更有效地利用失败案例中的信息,加速学习过程。本质区别在于,传统方法依赖于模型自主探索失败案例,而该方法主动引导模型探索失败案例。
关键设计:关键设计包括:1) 如何选择失败轨迹的前缀:论文可能采用了某种策略来选择最具信息量的失败前缀;2) 如何平衡对失败前缀的探索和对正确推理的坚持:论文可能引入了某种机制来避免模型过度关注失败案例,从而影响其正确推理能力;3) 迭代训练的策略:如何定期刷新失败前缀,以避免模型过度拟合特定的失败案例。
🖼️ 关键图片

📊 实验亮点
实验结果表明,失败前缀条件学习方法能够取得与在中等难度问题上训练相当的性能提升,同时保持了token效率。此外,该方法还降低了模型在误导性失败前缀下的性能下降。通过迭代刷新失败前缀,可以进一步提升性能,突破性能瓶颈。这些结果表明,该方法为扩展RLVR在饱和问题上的训练提供了一条有效途径。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、逻辑推理等。通过提高模型在饱和问题上的学习效率,可以降低训练成本,并提升模型的实际应用效果。未来,该方法有望推广到其他强化学习任务中,进一步提升模型的学习能力。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has substantially improved the reasoning abilities of large language models (LLMs), yet training often stalls as problems become saturated. We identify the core challenge as the poor accessibility of informative failures: learning signals exist but are rarely encountered during standard rollouts. To address this, we propose failure-prefix conditioning, a simple and effective method for learning from saturated problems. Rather than starting from the original question, our approach reallocates exploration by conditioning training on prefixes derived from rare incorrect reasoning trajectories, thereby exposing the model to failure-prone states. We observe that failure-prefix conditioning yields performance gains matching those of training on medium-difficulty problems, while preserving token efficiency. Furthermore, we analyze the model's robustness, finding that our method reduces performance degradation under misleading failure prefixes, albeit with a mild trade-off in adherence to correct early reasoning. Finally, we demonstrate that an iterative approach, which refreshes failure prefixes during training, unlocks additional gains after performance plateaus. Overall, our results suggest that failure-prefix conditioning offers an effective pathway to extend RLVR training on saturated problems.