HESTIA: A Hessian-Guided Differentiable Quantization-Aware Training Framework for Extremely Low-Bit LLMs
作者: Guoan Wang, Feiyu Wang, Zongwei Lv, Yikun Zong, Tong Yang
分类: cs.LG, cs.AI
发布日期: 2026-01-28
备注: 13 pages, 2 figures
🔗 代码/项目: GITHUB
💡 一句话要点
HESTIA:一种Hessian引导的可微量化感知训练框架,用于极低比特LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化感知训练 低比特量化 大型语言模型 Hessian矩阵 梯度优化
📋 核心要点
- 现有极低比特量化感知训练方法存在梯度不匹配问题,导致量化模型优化受阻。
- Hestia通过温度控制的Softmax松弛和Hessian引导的退火策略,缓解梯度不匹配问题。
- 实验表明,Hestia在Llama-3.2上优于现有三元QAT基线,零样本性能提升显著。
📝 摘要(中文)
随着大型语言模型(LLMs)规模的持续扩大,部署日益受到内存墙的限制,这推动了向极低比特量化的转变。然而,大多数量化感知训练(QAT)方法从训练一开始就应用硬舍入和直通估计器(STE),这过早地离散化了优化空间,并在潜在权重和量化权重之间引起持续的梯度不匹配,从而阻碍了量化模型的有效优化。为了解决这个问题,我们提出了Hestia,一种Hessian引导的可微QAT框架,用于极低比特LLM,它用温度控制的softmax松弛代替了刚性的阶跃函数,以在训练早期保持梯度流动,同时逐步加强量化。此外,Hestia利用张量级的Hessian迹度量作为轻量级的曲率信号来驱动细粒度的温度退火,从而实现跨模型的灵敏度感知离散化。在Llama-3.2上的评估表明,Hestia始终优于现有的三元QAT基线,对于1B和3B模型,平均零样本改进分别为5.39%和4.34%。这些结果表明,Hessian引导的松弛有效地恢复了表示能力,为1.58比特LLM建立了更强大的训练路径。代码可在https://github.com/hestia2026/Hestia获得。
🔬 方法详解
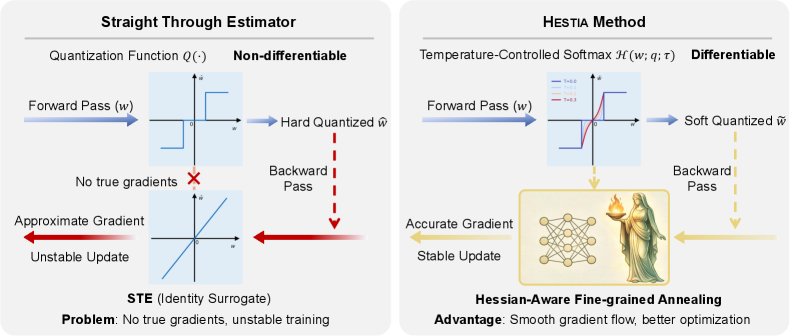
问题定义:论文旨在解决极低比特量化LLM时,由于硬量化和直通估计器(STE)的使用,导致的梯度不匹配问题。现有方法过早地离散化优化空间,使得量化后的权重与原始权重之间存在较大差异,阻碍了模型的有效训练。
核心思路:论文的核心思路是使用可微的量化方法,在训练初期保持梯度流动,并逐步加强量化。通过引入温度控制的Softmax松弛,代替了传统的硬量化阶跃函数,从而在训练初期保持了权重的连续性,缓解了梯度消失问题。同时,利用Hessian矩阵的迹作为曲率信号,指导温度退火过程,实现模型不同部分量化程度的自适应调整。
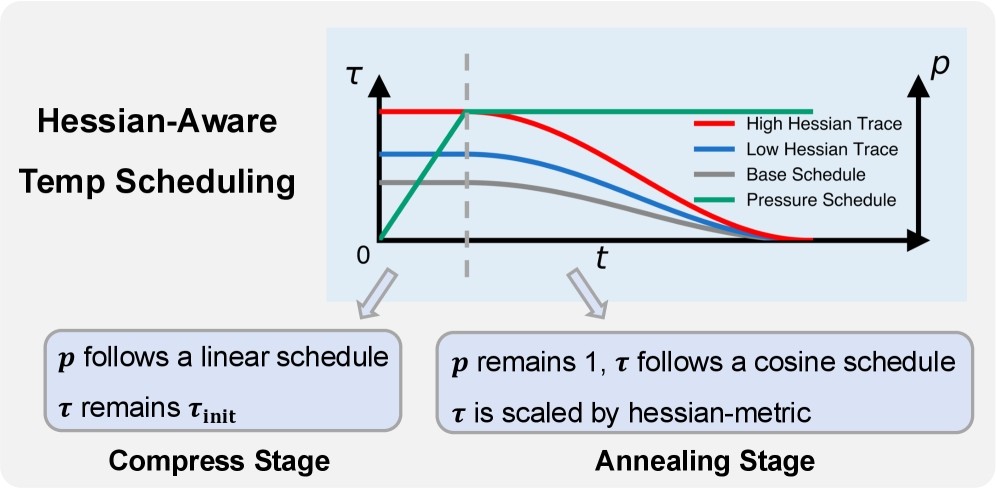
技术框架:Hestia框架主要包含以下几个阶段:1) 初始化:使用预训练模型权重初始化模型。2) Softmax松弛量化:使用温度控制的Softmax函数对权重进行量化,温度越高,量化越平滑。3) Hessian引导的温度退火:计算每个张量的Hessian迹,并根据Hessian迹的大小调整Softmax函数的温度,Hessian迹越大,温度下降越快,量化越严格。4) 训练:使用标准的反向传播算法更新模型权重。
关键创新:论文的关键创新在于:1) 使用Softmax松弛代替硬量化,保持梯度流动。2) 引入Hessian迹作为曲率信号,指导温度退火,实现细粒度的量化控制。3) 提出了一种可微的量化感知训练框架,适用于极低比特LLM。与现有方法的本质区别在于,Hestia不是直接进行硬量化,而是通过可微的松弛方法逐步逼近硬量化,从而避免了梯度不匹配问题。
关键设计:1) 温度控制的Softmax函数:使用温度参数控制量化的平滑程度。2) Hessian迹的计算:使用高效的算法计算Hessian矩阵的迹,作为曲率信号。3) 温度退火策略:根据Hessian迹的大小,自适应地调整温度下降的速度。4) 损失函数:使用标准的交叉熵损失函数进行训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Hestia在Llama-3.2的1B和3B模型上,相比于现有的三元QAT基线,平均零样本性能分别提升了5.39%和4.34%。这些结果验证了Hessian引导的松弛方法能够有效恢复表示能力,为1.58比特LLM建立更鲁棒的训练路径。
🎯 应用场景
该研究成果可应用于资源受限的场景,例如移动设备、边缘计算等,实现低功耗、高性能的LLM部署。通过极低比特量化,可以显著减小模型大小和计算复杂度,从而降低部署成本,并提高推理速度。未来,该方法有望推动LLM在更多实际场景中的应用。
📄 摘要(原文)
As large language models (LLMs) continue to scale, deployment is increasingly bottlenecked by the memory wall, motivating a shift toward extremely low-bit quantization. However, most quantization-aware training (QAT) methods apply hard rounding and the straight-through estimator (STE) from the beginning of the training, which prematurely discretizes the optimization landscape and induces persistent gradient mismatch between latent weights and quantized weights, hindering effective optimization of quantized models. To address this, we propose Hestia, a Hessian-guided differentiable QAT framework for extremely low-bit LLMs, which replaces the rigid step function with a temperature-controlled softmax relaxation to maintain gradient flow early in training while progressively hardening quantization. Furthermore, Hestia leverages a tensor-wise Hessian trace metric as a lightweight curvature signal to drive fine-grained temperature annealing, enabling sensitivity-aware discretization across the model. Evaluations on Llama-3.2 show that Hestia consistently outperforms existing ternary QAT baselines, yielding average zero-shot improvements of 5.39% and 4.34% for the 1B and 3B models. These results indicate that Hessian-guided relaxation effectively recovers representational capacity, establishing a more robust training path for 1.58-bit LLMs. The code is available at https://github.com/hestia2026/Hestia.