Positive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
作者: Zhiqiang Kou, Junyang Chen, Xin-Qiang Cai, Xiaobo Xia, Ming-Kun Xie, Dong-Dong Wu, Biao Liu, Yuheng Jia, Xin Geng, Masashi Sugiyama, Tat-Seng Chua
分类: cs.LG
发布日期: 2026-01-28
备注: 22 pages, 8 figures, 7 tables
💡 一句话要点
提出PU-RL蒸馏方法,用于在本地小模型上实现强化学习对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 蒸馏 本地部署 小模型 偏好优化 PU学习 自我排序
📋 核心要点
- 现有强化学习对齐方法依赖昂贵的人工标注或大规模API支持的奖励模型,不适用于本地部署的小模型。
- 该论文提出一种PU-RL蒸馏方法,无需人工标注或奖励模型,即可将教师模型的偏好优化能力迁移到本地学生模型。
- 实验表明,该方法在低成本设置下表现出色,证明了其在本地小模型强化学习对齐方面的有效性。
📝 摘要(中文)
由于隐私、成本和延迟的限制,本地部署小模型变得越来越普遍。然而,大多数实际流程止步于监督微调(SFT),未能达到强化学习(RL)对齐阶段。主要原因是RL对齐通常需要昂贵的人工偏好标注,或者严重依赖高质量的奖励模型,而这需要大规模API使用和持续的工程维护,两者都不适合本地环境。为了弥合这一差距,我们提出了一种用于本地小模型部署的positive-unlabeled(PU)RL蒸馏方法。在没有人工标注偏好或奖励模型的情况下,我们的方法将教师模型的偏好优化能力从黑盒生成中提炼到本地可训练的学生模型中。对于每个提示,我们查询教师模型一次以获得一个锚定响应,本地采样多个学生模型候选响应,并执行锚定条件下的自我排序以诱导成对或列表偏好,从而通过直接偏好优化或群体相对策略优化实现完全本地的训练循环。理论分析证明,我们的方法诱导的偏好信号在顺序上是一致的,并且集中在接近最优的候选者上,从而支持其偏好优化的稳定性。实验表明,我们的方法在低成本设置下实现了持续强大的性能。
🔬 方法详解
问题定义:论文旨在解决本地部署小模型难以进行强化学习对齐的问题。现有方法要么依赖昂贵的人工标注偏好数据,要么依赖需要大规模API调用和持续维护的高质量奖励模型,这两种方式都不适合资源受限的本地环境。因此,如何在本地环境下,以低成本的方式实现小模型的强化学习对齐是一个挑战。
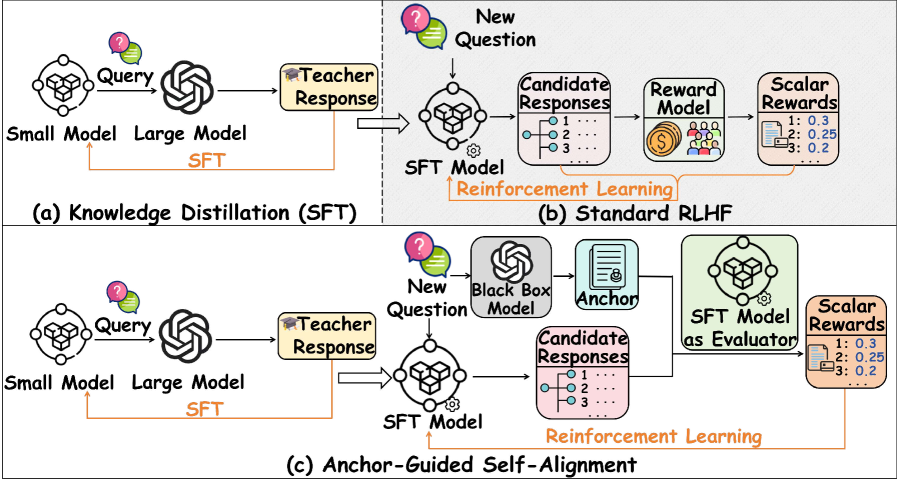
核心思路:论文的核心思路是利用Positive-Unlabeled(PU)学习的思想,通过蒸馏的方式将教师模型的偏好优化能力迁移到本地学生模型。具体来说,对于每个prompt,首先从教师模型获取一个anchor response,然后让学生模型生成多个候选response,并基于anchor response对这些候选response进行自我排序,从而生成伪偏好标签,用于训练学生模型。
技术框架:整体框架包含以下几个主要步骤:1) 教师模型查询:对于给定的prompt,查询教师模型,获得一个anchor response。2) 学生模型采样:在本地,学生模型基于prompt生成多个候选response。3) 锚定条件下的自我排序:基于anchor response,对学生模型生成的候选response进行排序,生成伪偏好标签。4) 偏好优化:利用生成的伪偏好标签,通过直接偏好优化(Direct Preference Optimization, DPO)或群体相对策略优化(Group Relative Policy Optimization, GRPO)等方法训练学生模型。
关键创新:该方法最重要的创新在于利用PU学习的思想,通过锚定条件下的自我排序,在没有人工标注或奖励模型的情况下,生成伪偏好标签,从而实现本地小模型的强化学习对齐。这种方法避免了对昂贵资源的依赖,使得本地部署小模型进行强化学习对齐成为可能。
关键设计:关键设计包括:1) 锚定响应的选择:教师模型的响应作为锚定点,影响着后续的偏好排序。2) 学生模型候选响应的采样策略:采样策略影响着候选响应的多样性和质量。3) 自我排序方法:如何有效地利用锚定响应对候选响应进行排序,生成高质量的伪偏好标签。4) 偏好优化算法:选择合适的偏好优化算法,例如DPO或GRPO,以有效地利用伪偏好标签训练学生模型。
🖼️ 关键图片

📊 实验亮点
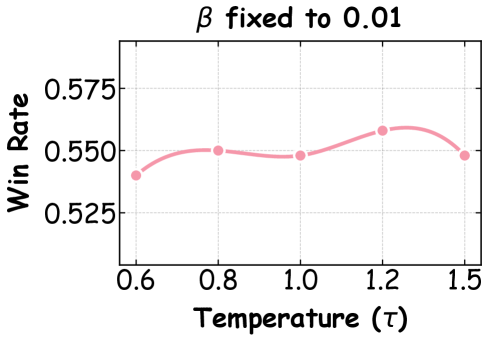
实验结果表明,该方法在低成本设置下取得了显著的性能提升。在没有人工标注或奖励模型的情况下,该方法能够有效地将教师模型的偏好优化能力迁移到本地学生模型,使其在特定任务上表现出与教师模型相近甚至更好的性能。
🎯 应用场景
该研究成果可广泛应用于对隐私、成本和延迟有严格要求的本地部署场景,例如智能家居、边缘计算设备、本地客服机器人等。通过该方法,可以在本地小模型上实现强化学习对齐,提升模型的性能和用户体验,同时避免了对云端API的依赖,保护了用户隐私。
📄 摘要(原文)
Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.