LLM-AutoDP: Automatic Data Processing via LLM Agents for Model Fine-tuning
作者: Wei Huang, Anda Cheng, Yinggui Wang, Lei Wang, Tao Wei
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-28
备注: Accepted by VLDB2026
💡 一句话要点
提出LLM-AutoDP,利用LLM智能体自动进行数据处理以优化模型微调。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据处理 自动化 模型微调 上下文学习 数据质量 隐私保护
📋 核心要点
- 现有数据处理策略依赖人工迭代分析和试错,成本高昂且存在隐私泄露风险,尤其是在医疗等敏感领域。
- LLM-AutoDP利用LLM作为智能体,自动生成和优化数据处理策略,无需人工干预和访问原始数据。
- 实验表明,使用LLM-AutoDP处理的数据训练的模型,性能显著优于使用原始数据训练的模型,且搜索效率大幅提升。
📝 摘要(中文)
大型语言模型(LLM)可以通过在特定领域的数据上进行微调来增强其在专业领域的性能。然而,这些数据通常包含大量低质量样本,因此需要有效的数据处理(DP)。在实践中,DP策略通常通过迭代的人工分析和试错调整来开发。这些过程不可避免地导致高昂的人力成本,并且由于人类直接访问敏感数据,可能导致医疗保健等高隐私领域的隐私问题。因此,在不暴露原始数据的情况下实现自动化数据处理已成为一项关键挑战。为了解决这一挑战,我们提出了一种新颖的框架LLM-AutoDP,该框架利用LLM作为智能体来自动生成和优化数据处理策略。我们的方法生成多个候选策略,并使用反馈信号和比较评估迭代地改进它们。这种迭代的上下文学习机制使智能体能够收敛到高质量的处理流程,而无需直接的人工干预或访问底层数据。为了进一步加速策略搜索,我们引入了三个关键技术:分布保持采样,它减少了数据量,同时保持了分布完整性;处理目标选择,它使用二元分类器来识别低质量样本以进行集中处理;缓存和重用机制,它通过重用先前的处理结果来最大限度地减少冗余计算。结果表明,在我们的框架处理的数据上训练的模型,相对于在未处理的数据上训练的模型,胜率超过80%。与基于LLM智能体的AutoML基线相比,LLM-AutoDP实现了约65%的胜率。此外,我们的加速技术将总搜索时间减少了高达10倍,证明了其有效性和效率。
🔬 方法详解
问题定义:论文旨在解决领域特定数据微调LLM时,数据质量参差不齐导致模型性能受限的问题。现有数据处理方法依赖人工,效率低、成本高,且存在隐私泄露风险。因此,需要一种自动化的数据处理方法,能够在不暴露原始数据的前提下,提升数据质量,从而提高模型微调效果。
核心思路:论文的核心思路是利用LLM本身作为智能体,自动探索和优化数据处理策略。通过迭代的上下文学习机制,LLM智能体能够根据反馈信号和比较评估,逐步改进数据处理流程,最终找到高质量的处理方案。这种方法避免了人工干预,降低了成本,并保护了数据隐私。
技术框架:LLM-AutoDP框架主要包含以下几个模块:1) 策略生成模块:利用LLM生成多个候选数据处理策略。2) 数据处理模块:根据生成的策略对数据进行处理。3) 评估模块:评估处理后的数据质量,并生成反馈信号。4) 策略优化模块:利用反馈信号,通过上下文学习机制,迭代优化数据处理策略。此外,框架还包含分布保持采样、处理目标选择和缓存重用机制等加速技术。
关键创新:论文的关键创新在于利用LLM作为智能体,实现数据处理策略的自动化探索和优化。与传统的AutoML方法相比,LLM-AutoDP能够更好地利用LLM的上下文学习能力,从而更有效地搜索高质量的数据处理流程。此外,论文提出的分布保持采样、处理目标选择和缓存重用机制等加速技术,进一步提高了搜索效率。
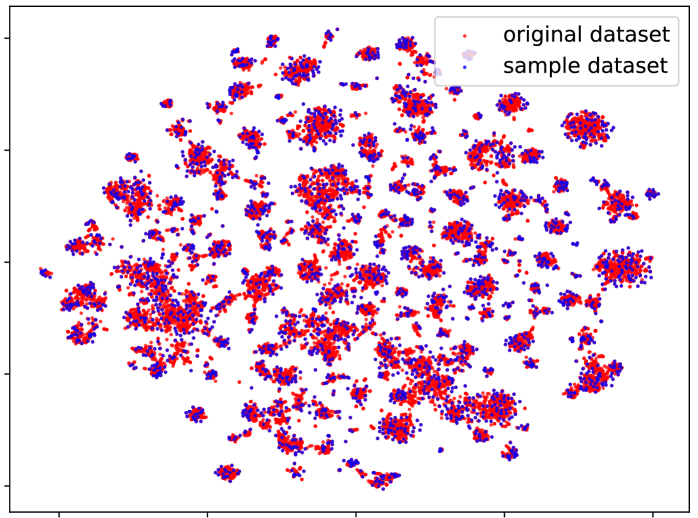
关键设计:1) 分布保持采样:通过采样减少数据量,同时保证采样后的数据分布与原始数据分布相似。具体实现方法未知。2) 处理目标选择:使用二元分类器识别低质量样本,并集中对这些样本进行处理。分类器的训练数据和特征选择未知。3) 缓存重用机制:缓存之前处理的结果,避免重复计算。缓存的粒度和更新策略未知。
🖼️ 关键图片

📊 实验亮点
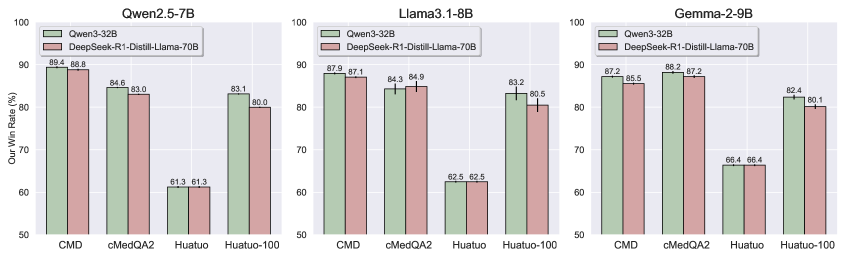
实验结果表明,使用LLM-AutoDP处理的数据训练的模型,相对于使用未处理数据训练的模型,胜率超过80%。与基于LLM智能体的AutoML基线相比,LLM-AutoDP实现了约65%的胜率。此外,论文提出的加速技术将总搜索时间减少了高达10倍,显著提升了搜索效率。
🎯 应用场景
LLM-AutoDP可广泛应用于需要对领域特定数据进行微调的场景,例如医疗、金融、法律等。该方法能够自动提升数据质量,提高模型性能,并降低人工成本和隐私风险。未来,该技术有望应用于更多数据驱动的AI应用中,实现更高效、更安全的数据处理。
📄 摘要(原文)
Large Language Models (LLMs) can be fine-tuned on domain-specific data to enhance their performance in specialized fields. However, such data often contains numerous low-quality samples, necessitating effective data processing (DP). In practice, DP strategies are typically developed through iterative manual analysis and trial-and-error adjustment. These processes inevitably incur high labor costs and may lead to privacy issues in high-privacy domains like healthcare due to direct human access to sensitive data. Thus, achieving automated data processing without exposing the raw data has become a critical challenge. To address this challenge, we propose LLM-AutoDP, a novel framework that leverages LLMs as agents to automatically generate and optimize data processing strategies. Our method generates multiple candidate strategies and iteratively refines them using feedback signals and comparative evaluations. This iterative in-context learning mechanism enables the agent to converge toward high-quality processing pipelines without requiring direct human intervention or access to the underlying data. To further accelerate strategy search, we introduce three key techniques: Distribution Preserving Sampling, which reduces data volume while maintaining distributional integrity; Processing Target Selection, which uses a binary classifier to identify low-quality samples for focused processing; Cache-and-Reuse Mechanism}, which minimizes redundant computations by reusing prior processing results. Results show that models trained on data processed by our framework achieve over 80% win rates against models trained on unprocessed data. Compared to AutoML baselines based on LLM agents, LLM-AutoDP achieves approximately a 65% win rate. Moreover, our acceleration techniques reduce the total searching time by up to 10 times, demonstrating both effectiveness and efficiency.