Less is More: Benchmarking LLM Based Recommendation Agents
作者: Kargi Chauhan, Mahalakshmi Venkateswarlu
分类: cs.IR, cs.LG
发布日期: 2026-01-28
💡 一句话要点
LLM推荐Agent:更少用户历史不损预测精度反降成本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推荐系统 上下文长度 推理成本 推荐质量 基准测试
📋 核心要点
- 现有LLM推荐系统依赖长用户历史,但计算成本高昂,且收益递减。
- 本文通过实验评估不同上下文长度对LLM推荐质量的影响,挑战“越多越好”的假设。
- 实验表明,减少上下文长度可显著降低推理成本,同时保持推荐质量,为实际部署提供指导。
📝 摘要(中文)
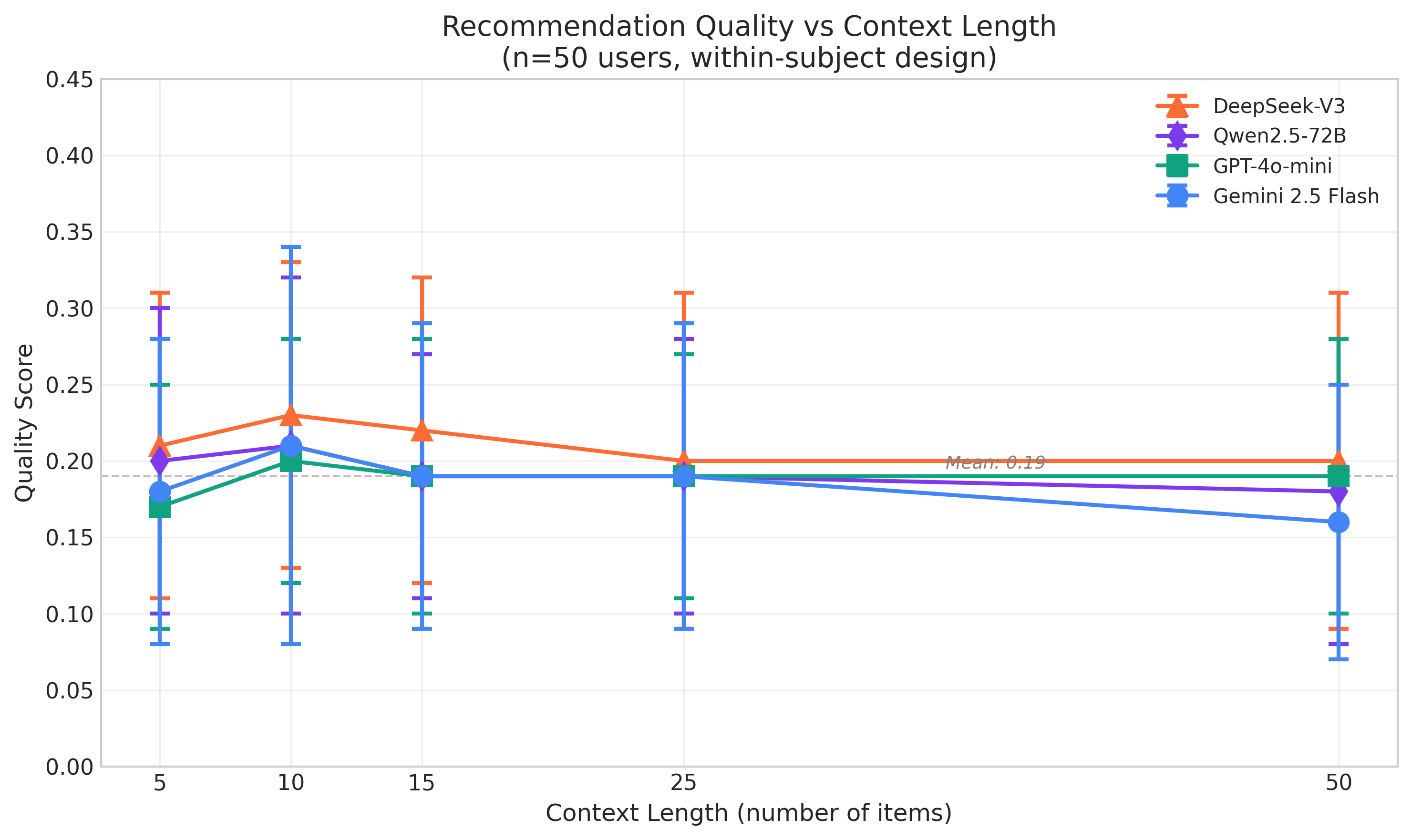
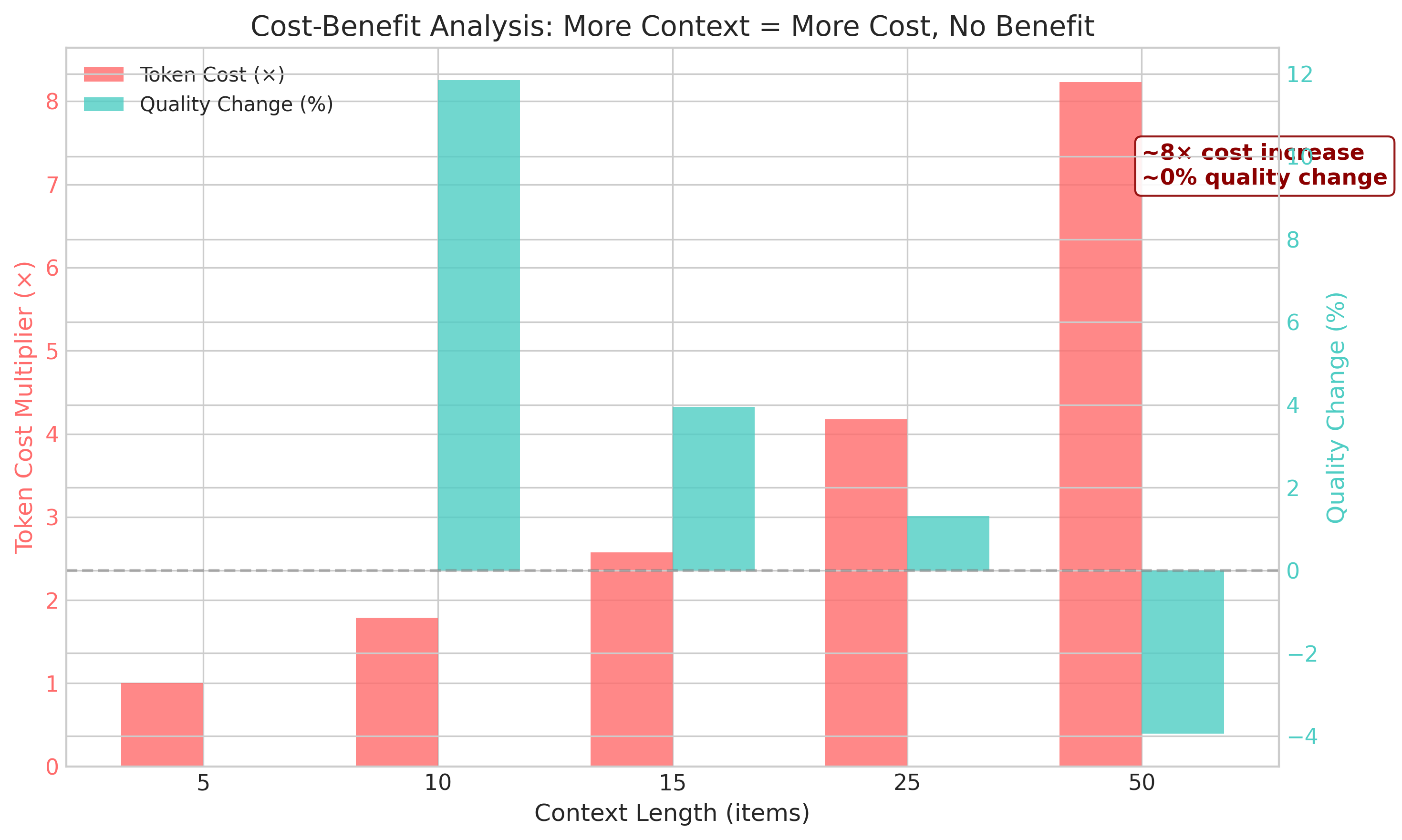
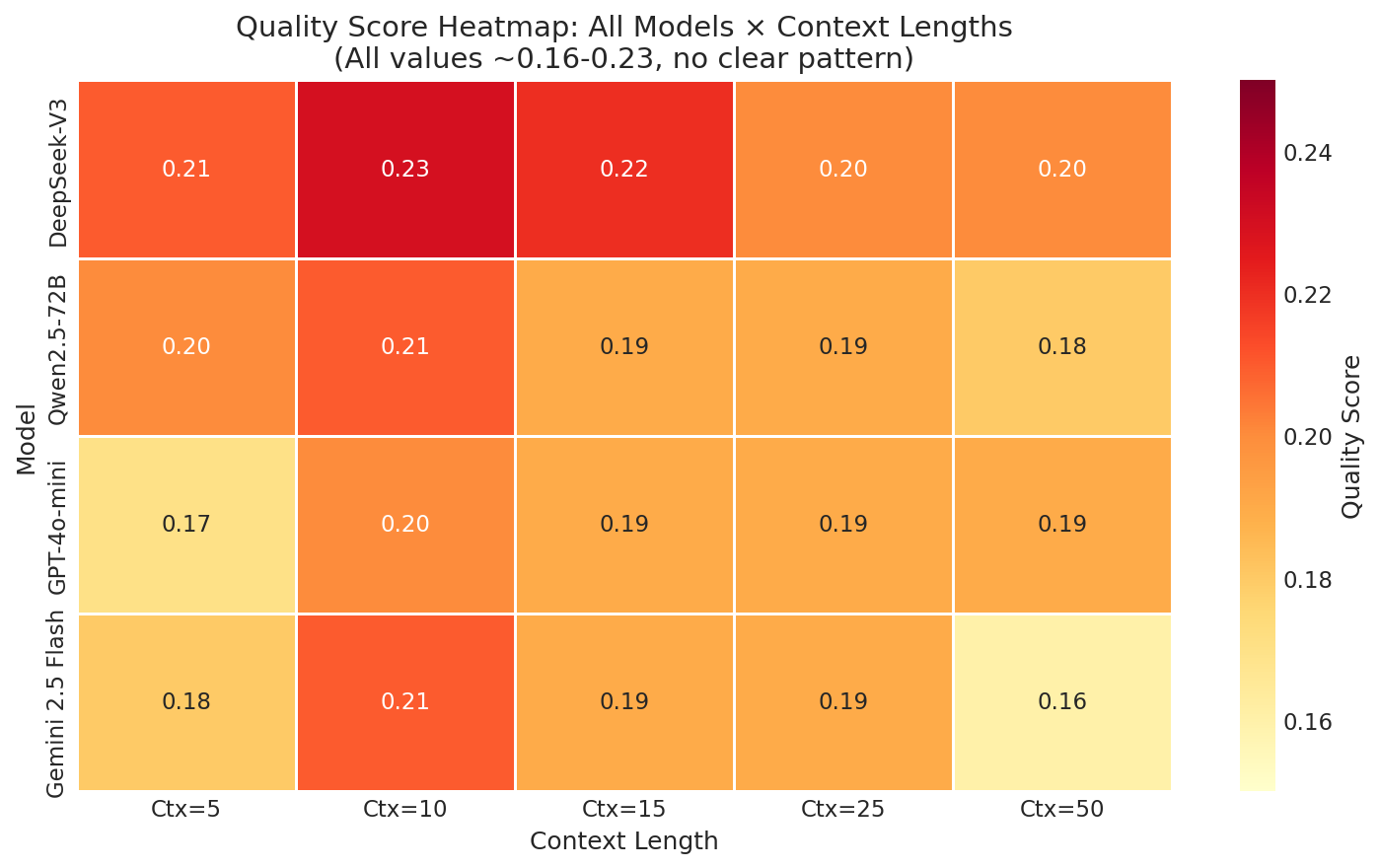
大型语言模型(LLM)越来越多地被用于个性化产品推荐,从业者普遍认为更长的用户购买历史能够带来更好的预测效果。本文对这一假设提出了挑战,通过使用REGEN数据集,对四种最先进的LLM模型GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B和Gemini 2.5 Flash在5到50个项目的上下文长度范围内进行了系统性基准测试。令人惊讶的是,我们对50名用户进行的受试者内设计实验表明,增加上下文长度并不能显著提高推荐质量。在所有条件下,质量得分保持平稳(0.17-0.23)。我们的发现具有重要的实际意义:从业者可以使用较短的历史记录(5-10个项目)代替较长的历史记录(50个项目),从而将推理成本降低约88%,而不会牺牲推荐质量。我们还分析了不同提供商的延迟模式,并发现了可用于指导部署决策的模型特定行为。这项工作挑战了现有的“更多上下文更好”的范式,并为具有成本效益的基于LLM的推荐系统提供了可操作的指导。
🔬 方法详解
问题定义:现有基于LLM的推荐系统通常假设更长的用户购买历史能够提升推荐质量。然而,这种假设忽略了计算成本的增加以及可能存在的收益递减效应。因此,本文旨在研究在LLM推荐系统中,上下文长度(即用户历史记录的长度)与推荐质量之间的关系,并挑战“更多上下文更好”的范式。现有方法的痛点在于,盲目增加上下文长度会导致不必要的计算资源浪费,而没有充分评估其对推荐性能的实际影响。
核心思路:本文的核心思路是通过系统性的实验评估不同上下文长度对LLM推荐质量的影响。具体而言,作者选取了四种先进的LLM模型,并在不同长度的上下文(从5个项目到50个项目)下进行推荐性能的测试。通过对比不同上下文长度下的推荐质量指标,作者旨在揭示上下文长度与推荐质量之间的真实关系,并为实际应用提供指导。
技术框架:本文采用的实验框架主要包括以下几个步骤:1)选择数据集:使用REGEN数据集,该数据集包含丰富的用户购买历史记录。2)选择LLM模型:选取GPT-4o-mini、DeepSeek-V3、Qwen2.5-72B和Gemini 2.5 Flash四种先进的LLM模型。3)设置上下文长度:将上下文长度设置为从5到50个项目不等。4)进行推荐实验:使用LLM模型根据用户历史记录生成推荐结果。5)评估推荐质量:使用适当的指标(例如,准确率、召回率等)评估推荐结果的质量。6)分析实验结果:对比不同上下文长度下的推荐质量,分析上下文长度与推荐质量之间的关系。
关键创新:本文最重要的技术创新点在于,它挑战了现有LLM推荐系统中“更多上下文更好”的范式。通过实验证明,在一定范围内,减少上下文长度并不会显著降低推荐质量,反而可以显著降低计算成本。这一发现对于实际应用具有重要的指导意义,可以帮助从业者在保证推荐质量的前提下,更加高效地利用计算资源。与现有方法的本质区别在于,本文不再盲目追求更长的用户历史记录,而是通过实验数据来验证上下文长度对推荐质量的实际影响。
关键设计:在实验设计方面,作者采用了受试者内设计,即每个用户都在不同的上下文长度下进行测试,从而可以更准确地评估上下文长度对推荐质量的影响。此外,作者还分析了不同LLM模型的延迟模式,为实际部署提供了参考。具体的技术细节包括:数据集的预处理方法、LLM模型的prompt设计、推荐质量评估指标的选择等。这些细节的设计都旨在保证实验结果的可靠性和有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,增加上下文长度并不能显著提高LLM推荐系统的质量,质量得分在不同条件下保持平稳(0.17-0.23)。更重要的是,使用较短的历史记录(5-10个项目)代替较长的历史记录(50个项目)可以将推理成本降低约88%,而不会牺牲推荐质量。这些发现为实际应用提供了重要的指导,表明在LLM推荐系统中,并非上下文长度越长越好。
🎯 应用场景
该研究成果可应用于各种在线推荐系统,例如电商、视频平台和音乐应用等。通过减少LLM推荐系统所需的上下文长度,可以在不牺牲推荐质量的前提下,显著降低推理成本,提高系统的效率和可扩展性。此外,该研究还为LLM模型的选择和部署提供了指导,有助于构建更具成本效益的推荐系统。未来,可以进一步研究如何根据用户行为动态调整上下文长度,以实现更个性化和高效的推荐。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed for personalized product recommendations, with practitioners commonly assuming that longer user purchase histories lead to better predictions. We challenge this assumption through a systematic benchmark of four state of the art LLMs GPT-4o-mini, DeepSeek-V3, Qwen2.5-72B, and Gemini 2.5 Flash across context lengths ranging from 5 to 50 items using the REGEN dataset. Surprisingly, our experiments with 50 users in a within subject design reveal no significant quality improvement with increased context length. Quality scores remain flat across all conditions (0.17--0.23). Our findings have significant practical implications: practitioners can reduce inference costs by approximately 88\% by using context (5--10 items) instead of longer histories (50 items), without sacrificing recommendation quality. We also analyze latency patterns across providers and find model specific behaviors that inform deployment decisions. This work challenges the existing ``more context is better'' paradigm and provides actionable guidelines for cost effective LLM based recommendation systems.