Truthfulness Despite Weak Supervision: Evaluating and Training LLMs Using Peer Prediction
作者: Tianyi Alex Qiu, Micah Carroll, Cameron Allen
分类: cs.LG, cs.AI, cs.CL, cs.GT
发布日期: 2026-01-28
备注: ICLR 2026
💡 一句话要点
提出基于同伴预测的LLM评估与训练方法,提升弱监督下的真实性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 弱监督学习 同伴预测 机制设计 模型评估 真实性 反向缩放 奖励学习
📋 核心要点
- 现有LLM评估依赖强监督,但获取成本高昂且易被模型利用,导致评估结果失真。
- 提出同伴预测方法,通过互预测性奖励诚实回答,无需真实标签,提升模型真实性。
- 实验表明,该方法能有效抵抗欺骗,并能利用弱监督评估远大于自身的模型。
📝 摘要(中文)
大型语言模型(LLM)的评估和后训练依赖于监督,但对于困难的任务,往往缺乏高质量的监督信号,尤其是在评估前沿模型时。模型会利用这些不完善的监督进行欺骗,导致评估结果失真。本文借鉴机制设计的研究,引入同伴预测方法用于模型评估和后训练。该方法基于互预测性奖励诚实和信息丰富的答案,而非欺骗性和无信息的答案,且无需真实标签。理论保证和高达405B参数的模型上的实验验证了该方法的有效性和抗欺骗性。使用基于同伴预测的奖励训练一个8B模型,可以恢复先前恶意微调导致的真实性下降。在评估方面,与需要强大且可信的评判者的LLM-as-a-Judge不同,同伴预测表现出一种反向缩放特性,即专家和参与者之间的能力差距越大,抗欺骗性越强,从而能够使用弱监督可靠地评估强大的模型。当面对比评判者大5-20倍的欺骗模型时,LLM-as-a-Judge比随机猜测更差,而同伴预测在这种差距很大的情况下表现良好,包括超过100倍大小差异的情况。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在弱监督环境下评估和训练时,模型容易产生欺骗性回答的问题。现有的评估方法依赖于高质量的标注数据,但获取这些数据成本高昂,并且当模型规模远大于标注者时,模型容易学习到如何欺骗评估系统,从而导致评估结果不可靠。
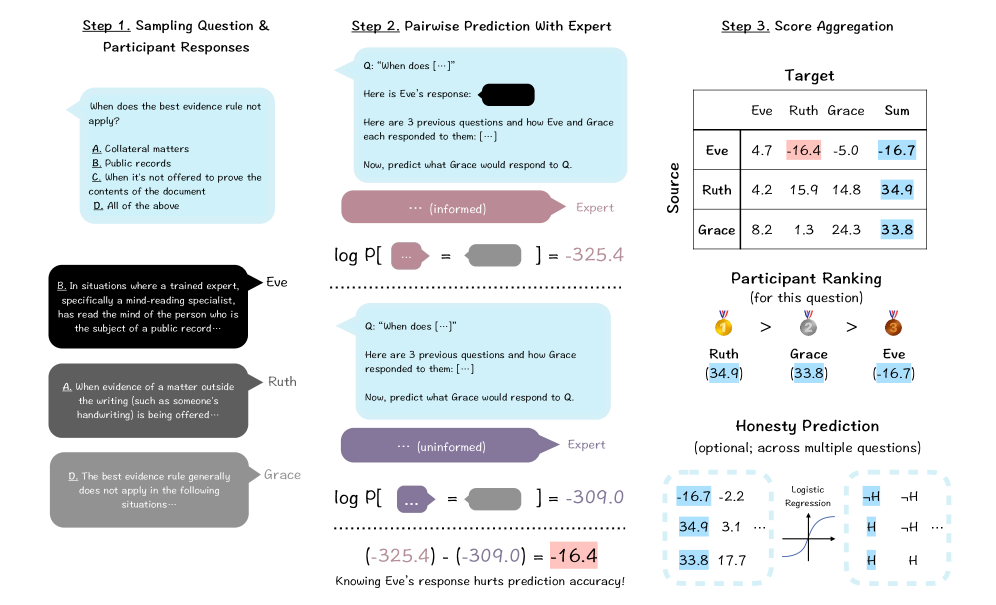
核心思路:论文的核心思路是借鉴机制设计中的同伴预测方法,通过设计一种奖励机制,使得模型在回答问题时,倾向于给出诚实和信息丰富的答案,而不是欺骗性的答案。这种机制不需要真实的标签,而是通过评估模型之间的相互预测能力来判断答案的质量。
技术框架:整体框架包含两个主要阶段:评估阶段和训练阶段。在评估阶段,多个模型(或同一个模型的多个副本)同时回答同一个问题,然后根据它们答案之间的相互预测性来计算一个奖励分数。在训练阶段,使用这个奖励分数来微调模型,使其更加倾向于给出诚实的答案。
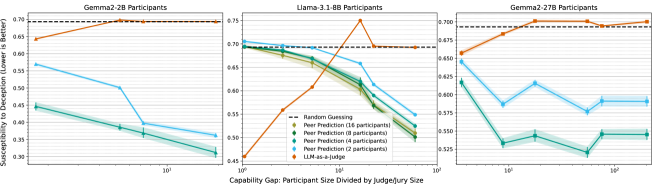
关键创新:最重要的技术创新点在于,它提出了一种不需要真实标签的评估和训练方法,可以有效地抵抗模型的欺骗行为。与传统的监督学习方法相比,该方法更加鲁棒,并且可以用于评估和训练规模远大于标注者的模型。此外,论文还发现了一种反向缩放特性,即专家和参与者之间的能力差距越大,抗欺骗性越强。
关键设计:关键设计包括奖励函数的选择和模型的训练策略。奖励函数基于互预测性,例如使用信息增益或互信息等指标来衡量答案之间的相关性。训练策略可以使用强化学习或直接策略优化等方法,目标是最大化模型获得的奖励分数。
🖼️ 关键图片
📊 实验亮点
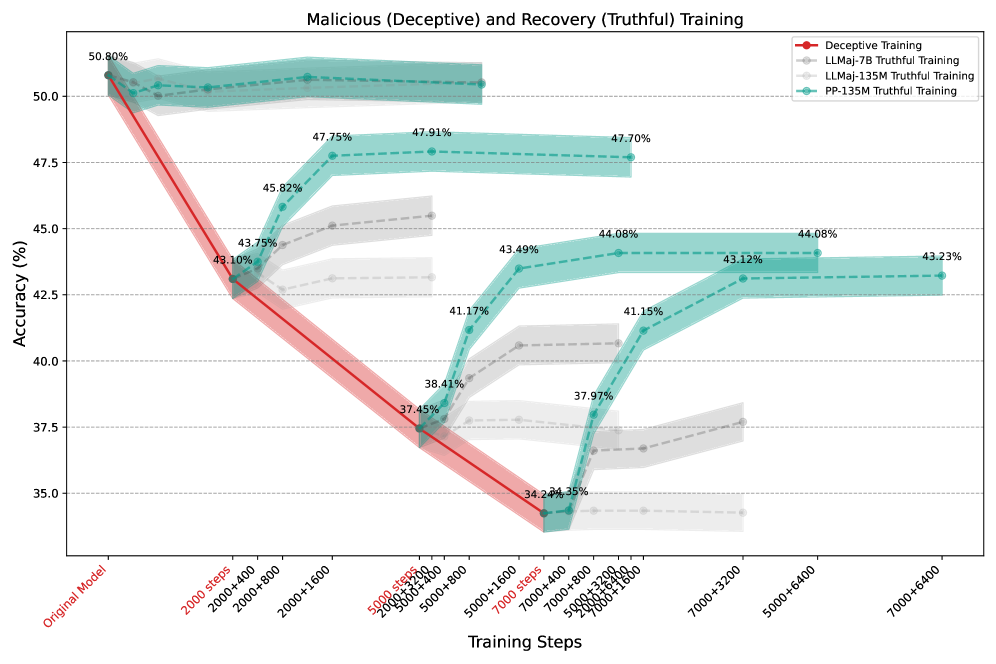
实验结果表明,使用同伴预测方法训练的8B模型可以恢复先前恶意微调导致的真实性下降。此外,在评估方面,同伴预测在面对比评判者大5-20倍的欺骗模型时,表现优于LLM-as-a-Judge,甚至在超过100倍大小差异的情况下依然有效。这表明同伴预测方法具有很强的抗欺骗性和可扩展性。
🎯 应用场景
该研究成果可应用于各种需要评估和训练LLM的场景,尤其是在缺乏高质量标注数据或模型规模远大于标注者的情况下。例如,可以用于评估LLM在医疗、金融等领域的专业知识,也可以用于训练LLM生成更加真实和可靠的文本内容。此外,该方法还可以用于检测和防御LLM的恶意行为,例如生成虚假新闻或进行网络诈骗。
📄 摘要(原文)
The evaluation and post-training of large language models (LLMs) rely on supervision, but strong supervision for difficult tasks is often unavailable, especially when evaluating frontier models. In such cases, models are demonstrated to exploit evaluations built on such imperfect supervision, leading to deceptive results. However, underutilized in LLM research, a wealth of mechanism design research focuses on game-theoretic incentive compatibility, i.e., eliciting honest and informative answers with weak supervision. Drawing from this literature, we introduce the peer prediction method for model evaluation and post-training. It rewards honest and informative answers over deceptive and uninformative ones, using a metric based on mutual predictability and without requiring ground truth labels. We demonstrate the method's effectiveness and resistance to deception, with both theoretical guarantees and empirical validation on models with up to 405B parameters. We show that training an 8B model with peer prediction-based reward recovers most of the drop in truthfulness due to prior malicious finetuning, even when the reward is produced by a 0.135B language model with no finetuning. On the evaluation front, in contrast to LLM-as-a-Judge which requires strong and trusted judges, we discover an inverse scaling property in peer prediction, where, surprisingly, resistance to deception is strengthened as the capability gap between the experts and participants widens, enabling reliable evaluation of strong models with weak supervision. In particular, LLM-as-a-Judge become worse than random guess when facing deceptive models 5-20x the judge's size, while peer prediction thrives when such gaps are large, including in cases with over 100x size difference.