Memory Retrieval in Transformers: Insights from The Encoding Specificity Principle
作者: Viet Hung Dinh, Ming Ding, Youyang Qu, Kanchana Thilakarathna
分类: cs.LG
发布日期: 2026-01-28
💡 一句话要点
基于编码特异性原则,揭示Transformer中Attention层的记忆检索机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 注意力机制 可解释性AI 记忆检索 编码特异性原则
📋 核心要点
- 现有LLM的可解释性方法对Transformer中Attention层的记忆检索机制探索不足。
- 该研究将Transformer注意力机制与人类记忆检索联系,提出关键词作为检索线索的假设。
- 实验分离出Attention层中编码和促进关键词检索的神经元,并应用于机器遗忘等下游任务。
📝 摘要(中文)
大型语言模型(LLMs)的可解释人工智能(XAI)领域仍处于发展阶段,存在许多未解决的问题,但日益增长的监管压力促使人们关注其在确保透明度、问责制和保护隐私的机器遗忘中的作用。尽管XAI的最新进展提供了一些见解,但基于Transformer的LLMs中注意力层的具体作用仍未得到充分探索。本研究借鉴心理学和计算心理语言学的研究,将Transformer注意力与人类记忆中基于线索的检索联系起来,从而研究注意力层所实例化的记忆机制。在这种观点下,queries编码检索上下文,keys索引候选记忆轨迹,注意力权重量化线索轨迹相似性,values携带编码内容,共同构建上下文表示,从而促进记忆检索。在编码特异性原则的指导下,我们假设检索初始阶段使用的线索被实例化为关键词。我们为这个关键词作为线索的假设提供了收敛证据。此外,我们分离了注意力层中选择性地编码和促进上下文定义关键词检索的神经元。因此,这些关键词可以从已识别的神经元中提取出来,并进一步用于下游应用,例如遗忘。
🔬 方法详解
问题定义:目前对大型语言模型中Transformer的注意力层如何实现记忆检索的机制理解不足,尤其是在可解释性方面。现有的XAI方法未能充分揭示注意力层在记忆检索中的具体作用,以及如何利用这些知识来改进下游任务,例如机器遗忘。
核心思路:该论文的核心思路是将Transformer的注意力机制类比于人类记忆检索过程中的线索依赖性。具体来说,论文假设queries充当检索上下文的编码,keys作为候选记忆的索引,注意力权重衡量线索与记忆的相似度,而values则携带编码的内容。通过这种类比,论文认为关键词在检索过程中扮演着关键线索的角色。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 基于编码特异性原则,提出关键词作为检索线索的假设。2) 通过实验验证该假设,寻找支持关键词作为线索的证据。3) 在Transformer的注意力层中,识别并分离出专门负责编码和促进关键词检索的神经元。4) 利用这些识别出的神经元和关键词,应用于下游任务,例如机器遗忘。
关键创新:该论文的关键创新在于将心理学中的编码特异性原则应用于理解Transformer的注意力机制,并提出了“关键词作为线索”的假设。这种视角为理解Transformer如何进行记忆检索提供了一种新的思路,并为开发更可解释的LLM提供了基础。此外,识别出专门负责关键词检索的神经元也是一个重要的发现。
关键设计:论文的关键设计包括:1) 设计实验来验证关键词作为检索线索的假设,例如通过操纵输入文本中的关键词来观察注意力权重的变化。2) 使用神经元激活模式分析技术,识别注意力层中与关键词检索相关的神经元。3) 设计基于关键词的机器遗忘方法,通过修改或删除与关键词相关的神经元连接来达到遗忘特定信息的目的。
🖼️ 关键图片

📊 实验亮点
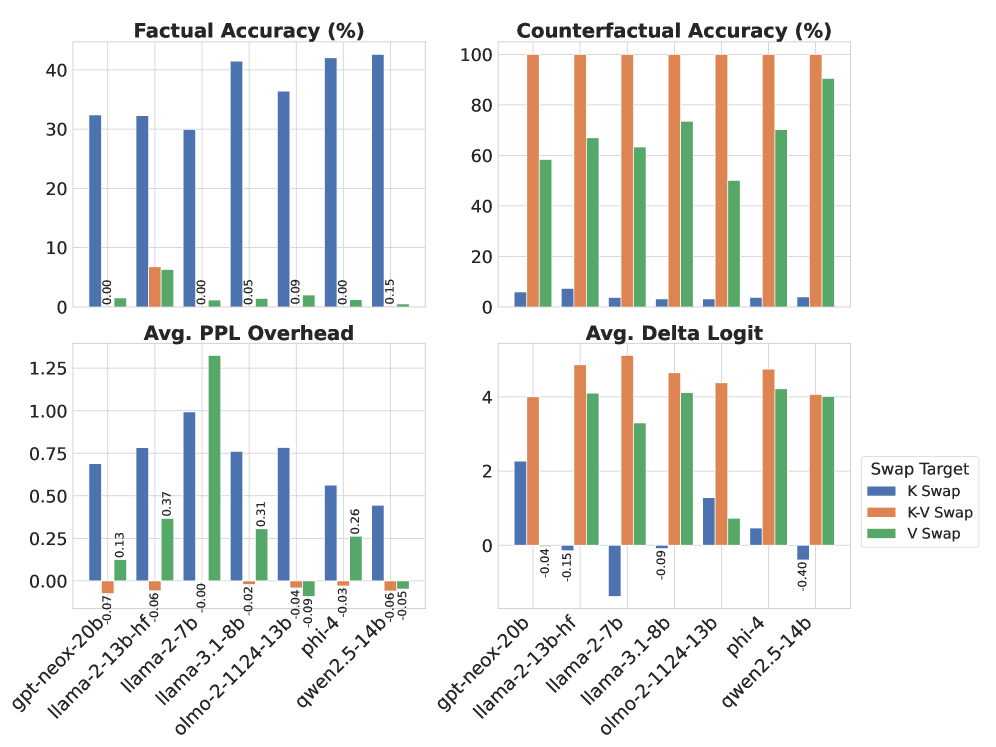
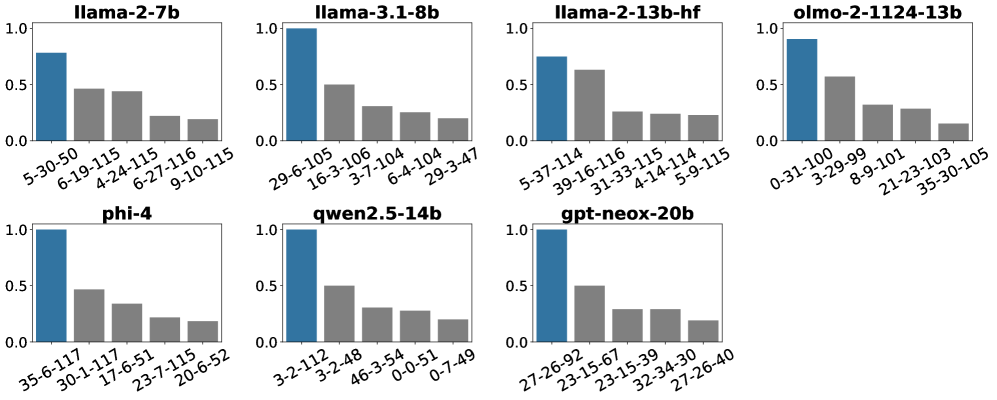
该研究通过实验验证了“关键词作为线索”的假设,并成功分离出注意力层中负责关键词检索的神经元。这些神经元的识别为理解Transformer的内部工作机制提供了新的视角,并为开发基于神经元的机器遗忘方法奠定了基础。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性,例如通过识别关键检索线索来理解模型的决策过程。此外,该研究还为开发更有效的机器遗忘技术提供了思路,可以用于保护用户隐私和数据安全。未来,该研究或可用于构建更具透明性和可控性的AI系统。
📄 摘要(原文)
While explainable artificial intelligence (XAI) for large language models (LLMs) remains an evolving field with many unresolved questions, increasing regulatory pressures have spurred interest in its role in ensuring transparency, accountability, and privacy-preserving machine unlearning. Despite recent advances in XAI have provided some insights, the specific role of attention layers in transformer based LLMs remains underexplored. This study investigates the memory mechanisms instantiated by attention layers, drawing on prior research in psychology and computational psycholinguistics that links Transformer attention to cue based retrieval in human memory. In this view, queries encode the retrieval context, keys index candidate memory traces, attention weights quantify cue trace similarity, and values carry the encoded content, jointly enabling the construction of a context representation that precedes and facilitates memory retrieval. Guided by the Encoding Specificity Principle, we hypothesize that the cues used in the initial stage of retrieval are instantiated as keywords. We provide converging evidence for this keywords-as-cues hypothesis. In addition, we isolate neurons within attention layers whose activations selectively encode and facilitate the retrieval of context-defining keywords. Consequently, these keywords can be extracted from identified neurons and further contribute to downstream applications such as unlearning.