HE-SNR: Uncovering Latent Logic via Entropy for Guiding Mid-Training on SWE-BENCH
作者: Yueyang Wang, Jiawei Fu, Baolong Bi, Xili Wang, Xiaoqing Liu
分类: cs.LG, cs.CL, cs.SE
发布日期: 2026-01-28
备注: 21 pages, 15 figures
💡 一句话要点
提出HE-SNR指标,通过熵压缩指导LLM在SWE-BENCH上的中训练,提升软件工程任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 中训练 软件工程 熵压缩 高熵信噪比
📋 核心要点
- 现有指标如PPL受长上下文影响,与SWE性能相关性弱,无法有效指导LLM中训练。
- 提出熵压缩假设,认为智能在于将不确定性结构化为低阶熵压缩状态的能力。
- 构建HE-SNR指标,并在MoE模型上验证,证明其具有更强的鲁棒性和预测能力。
📝 摘要(中文)
SWE-bench是评估大型语言模型在复杂软件工程任务上性能的首要基准。虽然这些能力主要是在中训练阶段获得,并在监督微调(SFT)期间被激发,但目前缺乏能够有效指导中训练的指标。诸如困惑度(PPL)之类的标准指标受到“长上下文税”的影响,并且与下游SWE性能的相关性较弱。本文通过引入严格的数据过滤策略来弥补这一差距。关键在于,我们提出了熵压缩假设,将智能重新定义为将不确定性构建为低阶熵压缩状态的能力,而非标量Top-1压缩。基于这种细粒度的熵分析,我们提出了一个新的指标,即高熵信噪比(HE-SNR)。在不同上下文窗口(32K/128K)的工业级混合专家(MoE)模型上验证表明,我们的方法具有卓越的鲁棒性和预测能力。这项工作为优化LLM在复杂工程领域的潜在能力提供了理论基础和实践工具。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在软件工程(SWE)任务上的性能评估主要依赖于SWE-bench等基准。然而,如何在中训练阶段有效地指导LLM学习,使其具备解决复杂SWE任务的能力,仍然是一个挑战。传统的困惑度(PPL)等指标受到“长上下文税”的影响,并且与下游SWE任务的性能相关性较弱,无法准确反映模型在中训练阶段的学习效果。
核心思路:论文的核心思路是基于“熵压缩假设”,重新定义智能。作者认为,智能并非简单地压缩信息(如Top-1压缩),而是将不确定性结构化为低阶熵压缩状态的能力,即模型能够以一种“合理的犹豫”的方式表达其对不同答案的置信度。基于此,论文提出了一种新的指标:高熵信噪比(HE-SNR),用于指导LLM的中训练。
技术框架:该方法主要包含以下几个步骤:1) 数据过滤:采用严格的数据过滤策略,确保训练数据的质量。2) 熵分析:对模型的输出进行细粒度的熵分析,计算每个token的熵值。3) HE-SNR计算:基于熵分析的结果,计算HE-SNR指标,该指标反映了模型输出中高熵信号与噪声的比率。4) 中训练指导:使用HE-SNR指标作为指导,优化LLM的中训练过程。
关键创新:论文的关键创新在于提出了“熵压缩假设”和HE-SNR指标。与传统的PPL等指标相比,HE-SNR能够更准确地反映模型在中训练阶段的学习效果,并且与下游SWE任务的性能具有更强的相关性。此外,该方法还提出了一种新的数据过滤策略,可以有效提高训练数据的质量。
关键设计:HE-SNR的具体计算方式未知,论文中提到是基于细粒度的熵分析,计算高熵信号与噪声的比率。数据过滤策略的具体细节也未知。MoE模型的具体结构和参数设置也未知。损失函数的设计也未知,但推测是利用HE-SNR来指导模型的训练,例如,可以设计一个损失函数,使得模型在训练过程中能够最大化HE-SNR。
🖼️ 关键图片
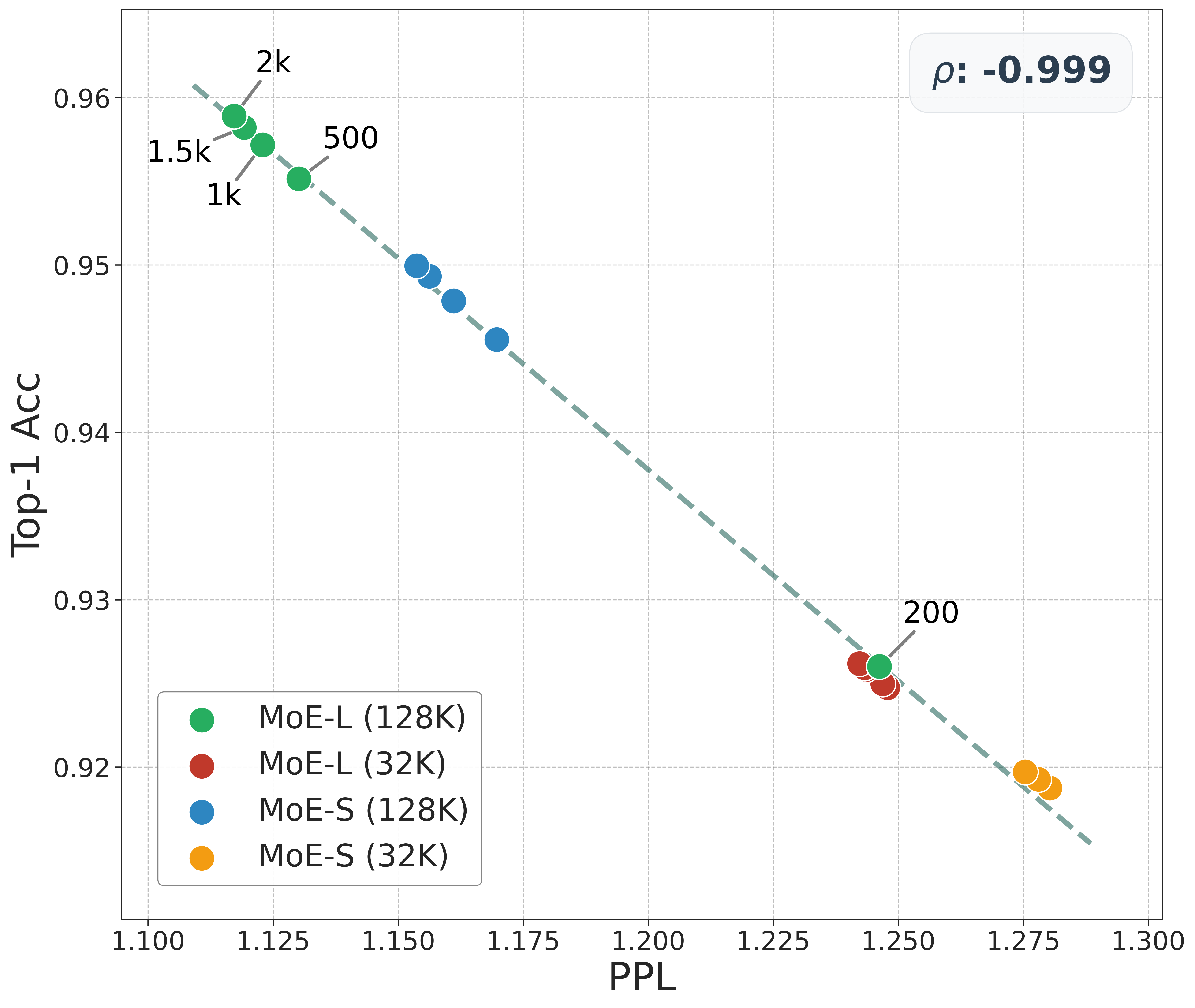
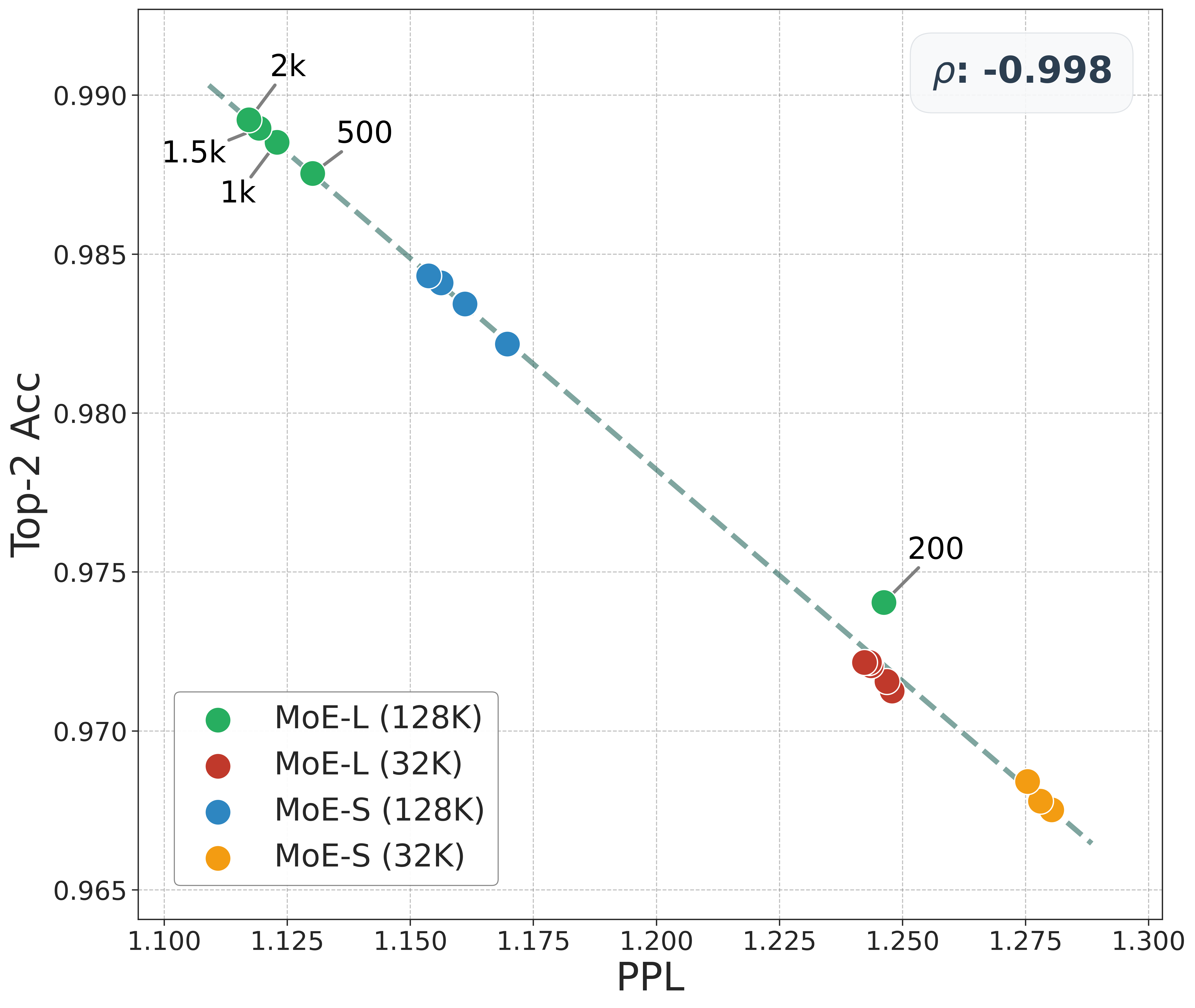
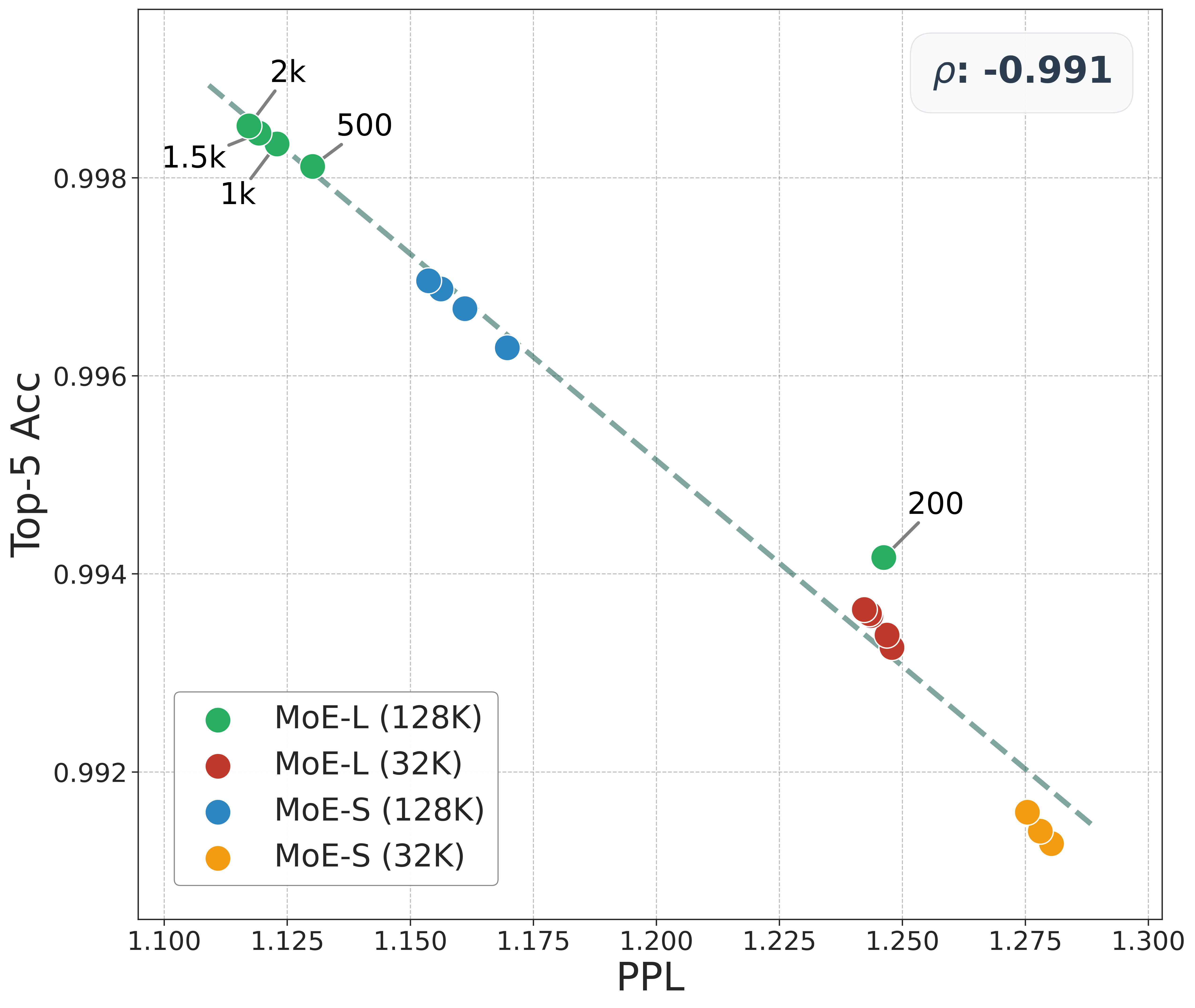
📊 实验亮点
论文在工业级混合专家(MoE)模型上验证了HE-SNR指标的有效性,使用了32K和128K两种不同的上下文窗口。实验结果表明,HE-SNR指标具有卓越的鲁棒性和预测能力,能够有效指导LLM的中训练,提升模型在SWE-bench上的性能。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于大型语言模型的中训练阶段,尤其是在软件工程领域。通过使用HE-SNR指标指导训练,可以提升模型在SWE-bench等基准上的性能,从而提高模型在代码生成、代码修复、代码理解等实际应用中的能力。此外,该方法也可以推广到其他需要处理复杂任务的领域,例如自然语言处理、机器翻译等。
📄 摘要(原文)
SWE-bench has emerged as the premier benchmark for evaluating Large Language Models on complex software engineering tasks. While these capabilities are fundamentally acquired during the mid-training phase and subsequently elicited during Supervised Fine-Tuning (SFT), there remains a critical deficit in metrics capable of guiding mid-training effectively. Standard metrics such as Perplexity (PPL) are compromised by the "Long-Context Tax" and exhibit weak correlation with downstream SWE performance. In this paper, we bridge this gap by first introducing a rigorous data filtering strategy. Crucially, we propose the Entropy Compression Hypothesis, redefining intelligence not by scalar Top-1 compression, but by the capacity to structure uncertainty into Entropy-Compressed States of low orders ("reasonable hesitation"). Grounded in this fine-grained entropy analysis, we formulate a novel metric, HE-SNR (High-Entropy Signal-to-Noise Ratio). Validated on industrial-scale Mixture-of-Experts (MoE) models across varying context windows (32K/128K), our approach demonstrates superior robustness and predictive power. This work provides both the theoretical foundation and practical tools for optimizing the latent potential of LLMs in complex engineering domains.