Meta-Cognitive Reinforcement Learning with Self-Doubt and Recovery
作者: Zhipeng Zhang, Wenting Ma, Kai Li, Meng Guo, Lei Yang, Wei Yu, Hongji Cui, Yichen Zhang, Mo Zhang, Jinzhe Lin, Zhenjie Yao
分类: cs.LG, cs.AI
发布日期: 2026-01-28
💡 一句话要点
提出基于自我怀疑与恢复的元认知强化学习框架,提升奖励腐蚀环境下的鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元认知学习 强化学习 鲁棒性 自我怀疑 价值预测误差 奖励腐蚀 连续控制
📋 核心要点
- 现有鲁棒强化学习方法难以推理自身学习过程的可靠性,容易对噪声过拟合或在不确定性累积时失效。
- 论文提出一种元认知强化学习框架,通过内部估计的可靠性信号来评估、调节和恢复智能体的学习行为。
- 实验表明,该方法在奖励腐蚀的连续控制任务中,相比现有方法能获得更高的平均回报并减少训练失败。
📝 摘要(中文)
鲁棒强化学习方法通常侧重于抑制不可靠的经验或受损的奖励,但缺乏对自身学习过程可靠性进行推理的能力。因此,这些方法要么对噪声过度反应而变得过于保守,要么在不确定性累积时遭遇灾难性失败。本文提出了一种元认知强化学习框架,使智能体能够基于内部估计的可靠性信号来评估、调节和恢复其学习行为。该方法引入了一个由价值预测误差稳定性(VPES)驱动的元信任变量,通过故障安全调节和逐步信任恢复来调节学习动态。在具有奖励腐蚀的连续控制基准测试中进行的实验表明,与强大的鲁棒性基线相比,启用恢复的元认知控制实现了更高的平均回报,并显著减少了后期训练失败。
🔬 方法详解
问题定义:现有强化学习方法在面对奖励腐蚀等噪声环境时,通常通过抑制不可靠经验或奖励来提高鲁棒性。然而,这些方法缺乏对自身学习过程可靠性的评估能力,导致其要么对噪声过度反应,变得过于保守,要么在不确定性累积时彻底失败。因此,如何让智能体具备自我认知能力,从而在不确定环境中更有效地学习是一个关键问题。
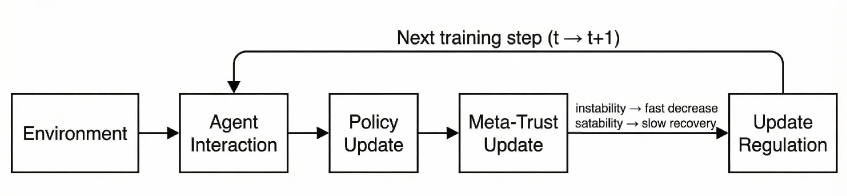
核心思路:论文的核心思路是引入元认知机制,使智能体能够评估自身学习过程的可靠性,并根据评估结果动态地调节学习行为。具体来说,智能体维护一个“元信任”变量,该变量反映了智能体对当前学习状态的置信度。当智能体检测到学习过程不稳定或不可靠时,会降低元信任,从而减缓学习速度,避免过度拟合噪声。反之,当学习过程稳定时,则逐步恢复元信任,加快学习速度。
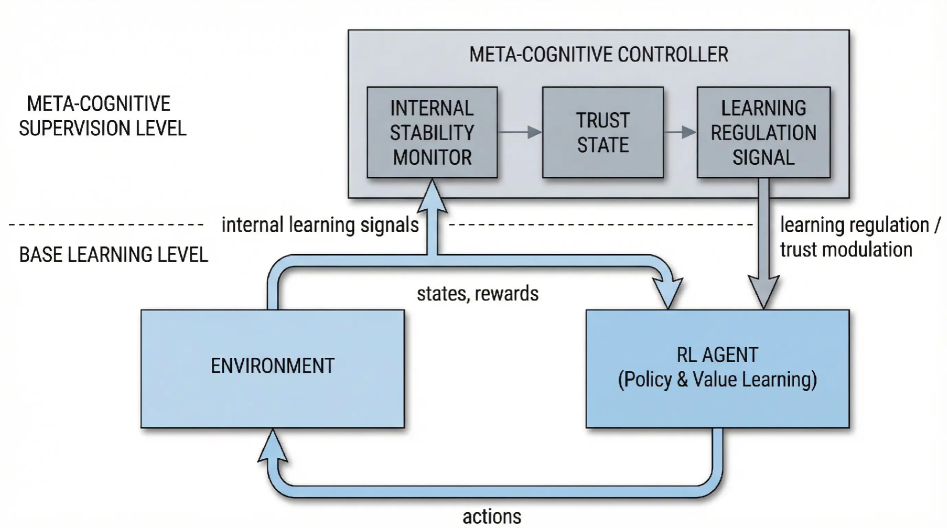
技术框架:该框架包含一个标准的强化学习智能体和一个元认知模块。强化学习智能体负责与环境交互并学习策略。元认知模块负责评估智能体学习过程的可靠性,并根据评估结果调节智能体的学习行为。元认知模块的核心是“元信任”变量,该变量由价值预测误差稳定性(VPES)驱动。VPES衡量了价值函数预测的一致性,可以作为学习过程稳定性的指标。整体流程是:智能体与环境交互,获得经验数据;元认知模块根据VPES更新元信任;元信任调节强化学习智能体的学习率;智能体根据调节后的学习率更新策略。
关键创新:该论文的关键创新在于引入了元认知机制到强化学习中,使智能体具备了自我评估和调节学习行为的能力。与传统的鲁棒强化学习方法相比,该方法不仅能够抑制噪声,还能够根据学习过程的稳定性动态地调整学习策略,从而在不确定环境中获得更好的性能。此外,使用价值预测误差稳定性(VPES)作为元信任的驱动信号也是一个创新点,VPES能够有效地反映学习过程的稳定性。
关键设计:元信任变量的更新方式:元信任的更新基于VPES,如果VPES低于某个阈值,则降低元信任;如果VPES高于某个阈值,则逐步恢复元信任。学习率的调节方式:智能体的学习率由元信任变量进行调节,元信任越高,学习率越高;元信任越低,学习率越低。具体公式未知,需要在论文中查找。损失函数:损失函数未知,需要在论文中查找。网络结构:网络结构未知,需要在论文中查找。
🖼️ 关键图片
📊 实验亮点
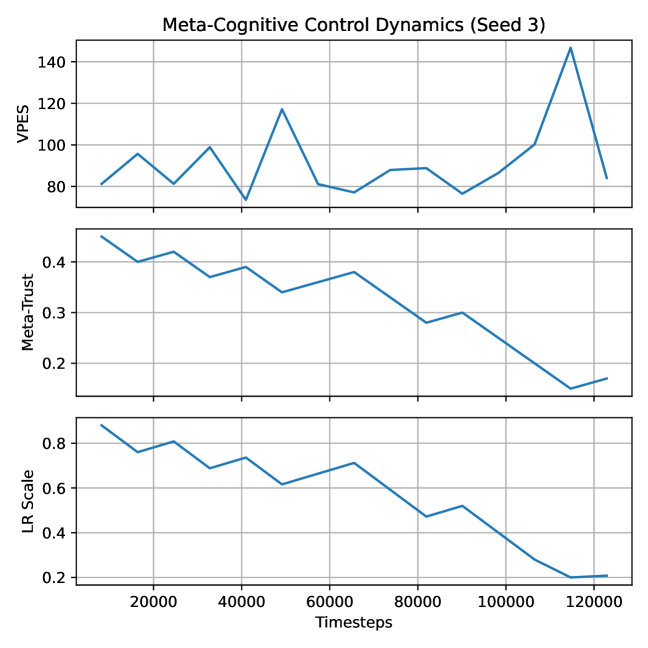
实验结果表明,在具有奖励腐蚀的连续控制基准测试中,该方法相比于其他鲁棒强化学习基线,能够获得更高的平均回报,并且显著减少了后期训练失败的情况。具体性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要在不确定或噪声环境中进行学习的机器人和人工智能系统。例如,在自动驾驶领域,可以利用该方法提高车辆在恶劣天气或传感器故障情况下的鲁棒性。在金融交易领域,可以帮助交易系统更好地应对市场波动和欺诈行为。此外,该方法还可以应用于游戏AI、智能制造等领域,提高智能体在复杂环境中的适应能力。
📄 摘要(原文)
Robust reinforcement learning methods typically focus on suppressing unreliable experiences or corrupted rewards, but they lack the ability to reason about the reliability of their own learning process. As a result, such methods often either overreact to noise by becoming overly conservative or fail catastrophically when uncertainty accumulates. In this work, we propose a meta-cognitive reinforcement learning framework that enables an agent to assess, regulate, and recover its learning behavior based on internally estimated reliability signals. The proposed method introduces a meta-trust variable driven by Value Prediction Error Stability (VPES), which modulates learning dynamics via fail-safe regulation and gradual trust recovery. Experiments on continuous-control benchmarks with reward corruption demonstrate that recovery-enabled meta-cognitive control achieves higher average returns and significantly reduces late-stage training failures compared to strong robustness baselines.