Self-Distillation Enables Continual Learning
作者: Idan Shenfeld, Mehul Damani, Jonas Hübotter, Pulkit Agrawal
分类: cs.LG
发布日期: 2026-01-27
💡 一句话要点
提出自蒸馏微调SDFT,实现从演示中持续学习,缓解灾难性遗忘。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 自蒸馏 灾难性遗忘 模仿学习 在线学习
📋 核心要点
- 现有持续学习方法依赖强化学习或监督微调,前者需显式奖励,后者易灾难性遗忘。
- SDFT利用自蒸馏,将演示条件模型作为自身教师,生成在线策略训练信号。
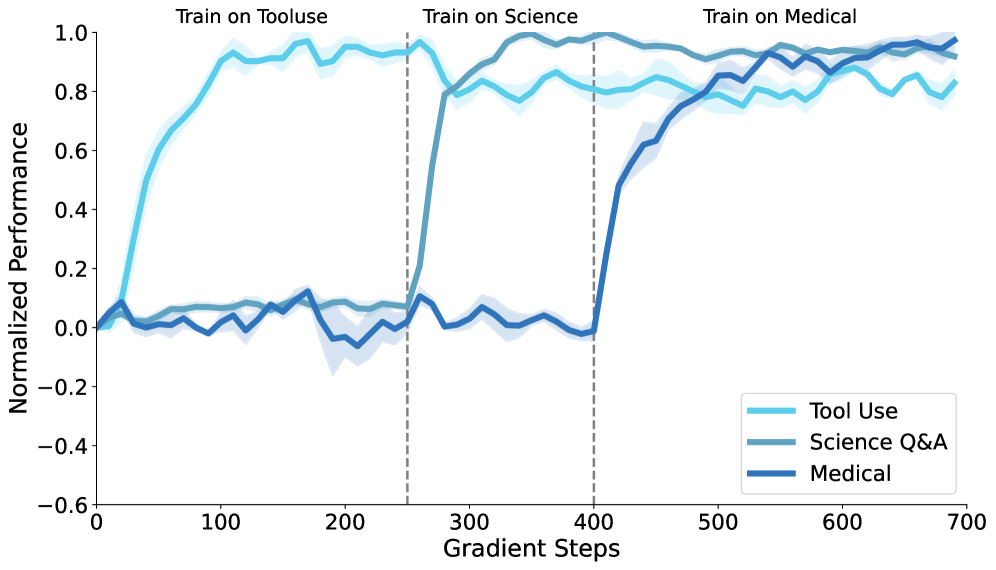
- 实验表明,SDFT在技能学习和知识获取上优于SFT,显著减少灾难性遗忘。
📝 摘要(中文)
持续学习是基础模型面临的一项根本挑战,它要求模型在不降低现有能力的情况下获取新的技能和知识。虽然在线强化学习可以减少遗忘,但它需要通常不可用的显式奖励函数。主要的替代方案——从专家演示中学习,主要由监督微调(SFT)主导,而SFT本质上是离线策略的。我们引入了自蒸馏微调(SDFT),这是一种简单的方法,可以直接从演示中实现在线策略学习。SDFT利用上下文学习,使用演示条件模型作为其自身的教师,生成在线策略训练信号,在获取新技能的同时保留先前的能力。在技能学习和知识获取任务中,SDFT始终优于SFT,在实现更高的新任务准确率的同时,显著减少了灾难性遗忘。在序列学习实验中,SDFT使单个模型能够随着时间的推移积累多个技能而不会出现性能下降,从而将在线策略蒸馏确立为从演示中持续学习的实用途径。
🔬 方法详解
问题定义:论文旨在解决持续学习中,模型在学习新任务时遗忘旧任务知识的问题,即灾难性遗忘。现有的监督微调(SFT)方法虽然简单有效,但本质上是离线策略学习,容易导致模型过拟合新数据,从而忘记之前学习的知识。强化学习虽然可以在线学习,但需要显式的奖励函数,这在很多实际场景中难以获取。
核心思路:论文的核心思路是利用自蒸馏,让模型自己作为自己的“老师”,通过模仿自己的输出来学习新的知识。具体来说,模型在学习新任务时,会根据演示数据生成自己的输出,然后将这些输出作为目标,训练模型去逼近这些目标。由于目标是由模型自身生成的,因此可以看作是一种在线策略学习,能够更好地保留之前学习的知识。
技术框架:SDFT的整体框架如下:首先,使用演示数据对模型进行微调,得到一个演示条件模型。然后,使用该模型作为教师,生成在线策略训练信号。具体来说,对于每个训练样本,模型会根据演示数据生成一个输出,然后将该输出作为目标,使用KL散度等损失函数,训练模型去逼近该目标。这个过程可以迭代多次,直到模型收敛。
关键创新:SDFT的关键创新在于使用自蒸馏来实现在线策略学习。与传统的监督微调相比,SDFT能够更好地保留之前学习的知识,从而减少灾难性遗忘。与强化学习相比,SDFT不需要显式的奖励函数,可以直接从演示数据中学习。
关键设计:SDFT的关键设计包括:1) 使用演示条件模型作为教师,生成在线策略训练信号;2) 使用KL散度等损失函数,衡量模型输出与目标之间的差异;3) 迭代训练模型,直到模型收敛。论文中没有明确提及具体的参数设置或网络结构,但可以根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
SDFT在技能学习和知识获取任务中均优于SFT。例如,在序列学习实验中,SDFT使单个模型能够随着时间的推移积累多个技能而不会出现性能下降,显著减少了灾难性遗忘。具体性能数据和提升幅度在论文中进行了详细的展示,证明了SDFT作为一种实用的从演示中持续学习方法的有效性。
🎯 应用场景
SDFT具有广泛的应用前景,例如机器人技能学习、对话系统、知识图谱构建等。它可以帮助模型在不断学习新知识的同时,保持原有的能力,从而实现真正的持续学习。该方法尤其适用于那些难以获取显式奖励函数的场景,例如模仿人类行为、学习复杂技能等。
📄 摘要(原文)
Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.