Improving Policy Exploitation in Online Reinforcement Learning with Instant Retrospect Action
作者: Gong Gao, Weidong Zhao, Xianhui Liu, Ning Jia
分类: cs.LG
发布日期: 2026-01-27
💡 一句话要点
IRA:通过即时回顾动作提升在线强化学习中的策略利用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 在线强化学习 策略利用 Q-表示学习 动作指导 策略更新
📋 核心要点
- 现有在线强化学习算法在探索和策略更新方面存在不足,导致策略利用效率低下。
- IRA算法通过Q-表示差异演化、贪婪动作指导和即时策略更新来提升策略学习和利用。
- 实验表明,IRA在MuJoCo连续控制任务中显著提高了学习效率和最终性能,并缓解了过估计偏差。
📝 摘要(中文)
现有的基于价值的在线强化学习(RL)算法由于探索效率低下和策略更新延迟,策略利用速度较慢。为了解决这些挑战,我们提出了一种名为即时回顾动作(IRA)的算法。具体来说,我们提出了Q-表示差异演化(RDE)来促进Q网络表示学习,从而为相邻状态-动作对实现可区分的表示。此外,我们采用了一种显式的方法,通过启用贪婪动作指导(GAG)来约束策略,这是通过回溯历史动作来实现的,从而有效地增强了策略更新过程。我们提出的方法依赖于为学习算法提供准确的k近邻动作价值估计,并通过策略约束学习设计快速适应的策略。我们进一步提出了即时策略更新(IPU)机制,该机制通过系统地增加策略更新的频率来增强策略利用。我们进一步发现,IRA方法在早期训练中的保守性可以缓解基于价值的RL中的过度估计偏差问题。实验结果表明,IRA可以显著提高在线RL算法在八个MuJoCo连续控制任务中的学习效率和最终性能。
🔬 方法详解
问题定义:现有基于价值的在线强化学习算法,由于探索效率低和策略更新延迟,导致策略利用速度慢。算法难以区分相似状态-动作对的价值,并且策略更新不够及时,无法快速适应环境变化。
核心思路:IRA的核心思路是通过回顾历史动作,并结合Q值表示学习和策略约束,来加速策略的探索和利用。具体来说,通过Q-表示差异演化(RDE)增强Q网络的表示能力,通过贪婪动作指导(GAG)显式地约束策略,并通过即时策略更新(IPU)提高策略更新的频率。
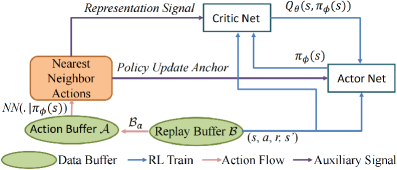
技术框架:IRA算法主要包含三个模块:Q-表示差异演化(RDE)、贪婪动作指导(GAG)和即时策略更新(IPU)。RDE模块负责学习更好的状态-动作表示,GAG模块负责利用历史信息约束策略更新,IPU模块负责加速策略更新。整体流程是,在每个时间步,算法首先使用RDE学习Q值表示,然后使用GAG选择动作并更新策略,最后使用IPU机制加速策略更新。
关键创新:IRA的关键创新在于将回顾历史动作的思想引入在线强化学习,并结合Q值表示学习和策略约束,从而实现了更高效的策略探索和利用。与现有方法相比,IRA能够更有效地利用历史信息,并更快速地适应环境变化。此外,IRA还发现早期训练的保守性有助于缓解过估计偏差问题。
关键设计:RDE模块通过最大化相邻状态-动作对的Q值表示差异来学习更好的表示。GAG模块通过回溯历史动作,并选择Q值最高的动作来指导策略更新。IPU模块通过增加策略更新的频率来加速策略学习。具体实现细节包括:使用k近邻算法估计动作价值,使用特定的损失函数来训练Q网络,以及使用特定的策略更新规则来更新策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,IRA算法在八个MuJoCo连续控制任务中显著提高了学习效率和最终性能。与基线算法相比,IRA能够更快地收敛到最优策略,并取得更高的平均奖励。例如,在某些任务中,IRA的性能提升超过了20%。此外,实验还验证了IRA算法缓解过估计偏差的能力。
🎯 应用场景
IRA算法可应用于各种需要快速适应和高效策略利用的在线强化学习场景,例如机器人控制、自动驾驶、游戏AI等。该算法能够提高智能体在复杂环境中的学习效率和性能,使其能够更快地掌握最优策略,并更好地适应环境变化。此外,IRA算法缓解过估计偏差的特性,使其在风险敏感型应用中具有潜在价值。
📄 摘要(原文)
Existing value-based online reinforcement learning (RL) algorithms suffer from slow policy exploitation due to ineffective exploration and delayed policy updates. To address these challenges, we propose an algorithm called Instant Retrospect Action (IRA). Specifically, we propose Q-Representation Discrepancy Evolution (RDE) to facilitate Q-network representation learning, enabling discriminative representations for neighboring state-action pairs. In addition, we adopt an explicit method to policy constraints by enabling Greedy Action Guidance (GAG). This is achieved through backtracking historical actions, which effectively enhances the policy update process. Our proposed method relies on providing the learning algorithm with accurate $k$-nearest-neighbor action value estimates and learning to design a fast-adaptable policy through policy constraints. We further propose the Instant Policy Update (IPU) mechanism, which enhances policy exploitation by systematically increasing the frequency of policy updates. We further discover that the early-stage training conservatism of the IRA method can alleviate the overestimation bias problem in value-based RL. Experimental results show that IRA can significantly improve the learning efficiency and final performance of online RL algorithms on eight MuJoCo continuous control tasks.